Learn more about Search Results プラグイン - Page 2

- You may be interested
- Intelのテクノロジーを使用して、PyTorch...
- デジタルアーティストのスティーブン・タ...
- 「ナノフォトニクスがカメラレンズを平ら...
- 2023 AIインデックスレポート:将来に期待...
- このAI論文では、「ステーブルシグネチャ...
- 最適なパイプラインとトランスフォーマー...
- 最新のWindowsアップデートによるAIによる...
- 生成AIの責任ある使用の緊急性
- IntelとHugging Faceがパートナーシップを...
- チャタヌーガプラントは、量子種子を育て...
- Rにおけるトップ10のエラーとそれらを修正...
- 「ハイブリッド検索を用いたRAGパイプライ...
- 「HuggingFace Diffusersにおける拡散モデ...
- 『React開発の向上:ChatGPTの力を解き放...
- 言語を使って、ロボットが広範な世界をよ...

「Retroformer」をご紹介します:プラグインの回顧モデルを学習することで、大規模な言語エージェントの反復的な改善を実現する優れたAIフレームワーク
大規模な言語モデル(LLM)を強化して、単にユーザーの質問に応答するのではなく、目標のために独立して活動できる自律的な言語エージェントにするという、力強い新しいトレンドが浮上しています。React、Toolformer、HuggingGPT、生成エージェント、WebGPT、AutoGPT、BabyAGI、Langchainなどは、LLMを利用して自律的な意思決定エージェントを開発する実用性を効果的に実証したよく知られた研究です。これらの手法は、LLMを使用してテキストベースの出力とアクションを生成し、それを使用して特定の文脈でAPIにアクセスし、活動を実行します。 ただし、現在の言語エージェントの大部分は、パラメータ数の多いLLMの範囲が非常に広いため、環境の報酬関数に最適化された行動を持っていません。ReflexionやSelf-Refine、Generative Agentなど、同様のアプローチを取る他の多くの作品とは異なり、比較的新しい言語エージェントアーキテクチャである反省アーキテクチャは、過去の失敗から学ぶために、口頭フィードバック、具体的には自己反省を利用してエージェントを支援します。これらの反射エージェントは、環境のバイナリまたはスカラーの報酬を音声入力としてテキストの要約に変換し、言語エージェントのプロンプトにさらなる文脈を提供します。 自己反省フィードバックは、エージェントに特定の改善領域を指示することで、エージェントにとって意味的な信号となります。これにより、エージェントは過去の失敗から学び、同じ間違いを繰り返さずに次回の試行でより良い結果を出すことができます。ただし、自己反省操作によって反復的な改善が可能になるものの、事前に訓練された凍結LLMから有用な反省フィードバックを生成することは困難です(図1参照)。これは、LLMが特定の環境でエージェントの誤りを特定し、改善の提案を含む要約を生成する能力が必要だからです。 図1は、凍結LLMの情報のない自己反省のイラストです。エージェントは「Teen Titans」という回答ではなく、「Teen Titans Go」と回答するべきであり、これが前回の試行が失敗した主な理由です。一連の思考、行動、詳細な観察を通じて、エージェントは目標を見失いました。しかし、凍結LLMからの音声フィードバックは、以前のアクションシーケンスを新たな計画として提案するだけであり、次の試行でも同じ間違った行動につながります。 特定の状況でのタスクの信用割り当ての問題を専門にするために、凍結言語モデルを十分に調整する必要があります。また、現在の言語エージェントは、異なる可能な報酬に基づいて勾配ベースの学習からの思考や計画に一貫した方法で取り組んでいません。Salesforce Researchの研究者は、Retroformerというモラルフレームワークを紹介し、制約を解決するためのプラグインの後向きモデルを学習して言語エージェントを強化する方法を提案しています。Retroformerは、方策最適化を通じて環境からの入力に基づいて言語エージェントのプロンプトを自動的に改善します。 具体的には、提案されたエージェントアーキテクチャは、失敗した試行を反省し、将来の報酬に対してエージェントが実行したアクションにクレジットを割り当てることで、事前に訓練された言語モデルを反復的に改善します。これは、複数の環境とタスク全体にわたる任意の報酬情報から学習することによって行われます。HotPotQAなどのオープンソースのシミュレーションおよび実世界の設定(WikipediaのAPIに繰り返し問い合わせる必要があるWebエージェントのツール使用スキルを評価する)で実験を行います。HotPotQAは、検索ベースの質問応答タスクで構成されています。反省に対して、勾配を使用しない思考や計画を行わないRetroformerエージェントは、より速く学習し、より良い意思決定を行います。具体的には、Retroformerエージェントは、検索ベースの質問応答タスクのHotPotQAの成功率をわずか4回の試行で18%向上させ、多くの状態アクション空間を持つ環境でのツール使用における勾配ベースの計画と推論の価値を証明しています。 結論として、彼らが貢献した内容は次の通りです: • この研究では、大規模言語エージェントへのコンテキスト入力に基づいて提示されるプロンプトを反復的に洗練することで、学習速度とタスク完了を向上させるRetroformerを開発しました。提案された手法は、Actor LLMのパラメータにアクセスせず、勾配を伝播する必要もないため、言語エージェントアーキテクチャ内のレトロスペクティブモデルの強化に焦点を当てています。 • 提案された手法により、さまざまなタスクと環境のためのさまざまな報酬信号からの学習が可能となります。Retroformerは、その汎用性のため、GPTやBardなどのクラウドベースのLLMに適応可能なプラグインモジュールです。
2023年のトップ8のChatGPTプラグイン(およびその使い方)
ChatGPTは、OpenAIの言語モデルシステムの最新バージョンであるGPT4によって動作しており、適切なプラグインを備えることで、さまざまなタスクを達成するための貴重な資産となり得ますただし、重要なのは...

ChatGPTコードインタープリタープラグインの使用方法10選
「待ち望まれていたChatGPTコードインタープリタープラグインがついに展開されています以下に、それを使ってできることを紹介します」

Google AIは、MediaPipe Diffusionプラグインを導入しましたこれにより、デバイス上で制御可能なテキストから画像生成が可能になります
最近、拡散モデルはテキストから画像を生成する際に非常に成功を収め、画像の品質、推論のパフォーマンス、および創造的な可能性の範囲の大幅な向上をもたらしています。しかし、効果的な生成管理は、特に言葉で定義しにくい条件下では依然として課題となっています。 Googleの研究者によって開発されたMediaPipe拡散プラグインにより、ユーザーの制御下でデバイス内でのテキストから画像の生成が可能になります。本研究では、デバイスそのもの上で大規模な生成モデルのGPU推論に関する以前の研究を拡張し、既存の拡散モデルおよびそのLow-Rank Adaptation(LoRA)のバリエーションに統合できるプログラマブルなテキストから画像の生成の低コストなソリューションを提供します。 拡散モデルでは、イテレーションごとに画像の生成が行われます。拡散モデルの各イテレーションは、ノイズが混入した画像から目標の画像までを生成することで始まります。テキストのプロンプトを通じた言語理解は、画像生成プロセスを大幅に向上させています。テキストの埋め込みは、テキストから画像の生成のためのモデルにリンクされ、クロスアテンション層を介して結びつけられます。ただし、物体の位置や姿勢などの詳細は、テキストのプロンプトを使用して伝えるのがより困難な例です。研究者は、条件画像からの制御情報を拡散に追加することで、拡散を利用して制御を導入します。 Plug-and-Play、ControlNet、およびT2Iアダプターの方法は、制御されたテキストから画像を生成するためによく使用されます。Plug-and-Playは、入力画像から状態をエンコードするために、拡散モデル(Stable Diffusion 1.5用の860Mパラメータ)のコピーと、広く使用されているノイズ除去拡散暗黙モデル(DDIM)逆推定手法を使用します。これにより、入力画像から初期ノイズ入力を導出します。コピーされた拡散からは、自己注意の空間特徴が抽出され、Plug-and-Playを使用してテキストから画像への拡散に注入されます。ControlNetは、拡散モデルのエンコーダーの訓練可能な複製を構築し、ゼロで初期化されたパラメータを持つ畳み込み層を介して接続し、条件情報をエンコードし、それをデコーダーレイヤーに渡します。残念ながら、これによりサイズが大幅に増加し、Stable Diffusion 1.5では約450Mパラメータとなり、拡散モデル自体の半分となります。T2I Adapterは、より小さなネットワーク(77Mパラメータ)であるにもかかわらず、制御された生成で同等の結果を提供します。条件画像のみがT2I Adapterに入力され、その結果がすべての後続の拡散サイクルで使用されます。ただし、このスタイルのアダプターはモバイルデバイス向けではありません。 MediaPipe拡散プラグインは、効果的かつ柔軟性があり、拡張性のある条件付き生成を実現するために開発されたスタンドアロンネットワークです。 訓練済みのベースラインモデルに簡単に接続できる、プラグインのようなものです。 オリジナルモデルからの重みを使用しないゼロベースのトレーニングです。 モバイルデバイス上でほとんど追加費用なしにベースモデルとは独立して実行可能なため、ポータブルです。 プラグインはそのネットワーク自体であり、その結果はテキストから画像への変換モデルに統合されます。拡散モデル(青)に対応するダウンサンプリング層は、プラグインから取得した特徴を受け取ります。 テキストから画像の生成のためのモバイルデバイス上でのポータブルなオンデバイスパラダイムであるMediaPipe拡散プラグインは、無料でダウンロードできます。条件付きの画像を取り込み、多スケールの特徴抽出を使用して、拡散モデルのエンコーダーに適切なスケールで特徴を追加します。テキストから画像への拡散モデルと組み合わせると、プラグインモデルは画像生成に条件信号を追加します。プラグインネットワークは、相対的にシンプルなモデルであるため、パラメータはわずか6Mとなっています。モバイルデバイスでの高速推論を実現するために、MobileNetv2は深度方向の畳み込みと逆ボトルネックを使用しています。 基本的な特徴 自己サービス機械学習のための理解しやすい抽象化。低コードAPIまたはノーコードスタジオを使用してアプリケーションを修正、テスト、プロトタイプ化、リリースするために使用します。 Googleの機械学習(ML)ノウハウを使用して開発された、一般的な問題に対する革新的なMLアプローチ。 ハードウェアアクセラレーションを含む完全な最適化でありながら、バッテリー駆動のスマートフォン上でスムーズに実行するために十分に小さく効率的です。
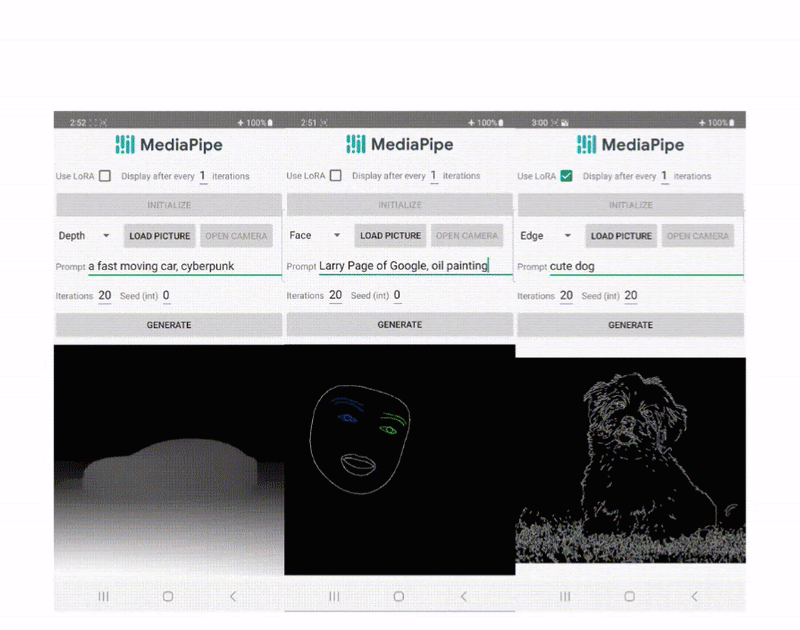
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…

ChatGPT Vislaプラグインを使用してビデオを作成する方法
たった一つのプロンプトで、Visla ChatGPTプラグインはわずか数秒でスクリプトとストック画像を使用したビデオを作成します

VoAGIニュース、6月28日:データサイエンスのチートシートのための10のChatGPTプラグイン • データ分析を自動化するChatGPTプラグイン
データサイエンスのチートシートのための10のChatGPTプラグイン • Noteableプラグイン:データ分析を自動化するChatGPTプラグイン • 無料でClaude AIにアクセスする方法は3つあります • ベクトルデータベースとは何か、なぜLLMにとって重要なのか • データサイエンティストのための探索的データ分析の必須ガイド

バーディーンChatGPTプラグインの使い方
この記事では、Bardeen ChatGPTプラグインを使って嫌な仕事を自動化する方法を紹介します

ChatGPT プラグイン:知っておく必要があるすべて
OpenAIが展開したサードパーティのプラグインについて学び、ChatGPTsの実際の使用を理解しましょう

注目すべきプラグイン:データ分析を自動化するChatGPTプラグイン
このChatGPTプラグインを使用して、EDAプロセスを高速化してください
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.