Learn more about Search Results ブートストラップ - Page 2

- You may be interested
- Googleは、AIを搭載したブラウザベースの...
- 生産性向上のための10の最高のAIツール(...
- あなたの特徴は重要ですか?それが良いと...
- データサイエンスチームの協力のための5つ...
- 『ODSCのAIウィークリーレビュー:12月15...
- 『Pythonの呼び出し可能オブジェクト:基...
- 「エッセンシャルAI、シリーズAラウンドで...
- 「カイリー・ヴェルゾサがAI企業とパート...
- ハーバード大学の新しいコンピューターサ...
- 「今秋のAiXビジネスサミットの第一弾スピ...
- 「ChatGPTは人間の創造性テストでトップ1%...
- スウィン・トランスフォーマー | モダンな...
- 「人工知能(AI)のトップコンテンツ検出...
- 研究者たちは、肩越しに画面をのぞき見す...
- データアナリストの仕事内容はどのように...

NVIDIA AIがSteerLMを発表:大規模言語モデル(LLMs)の推論中にユーザーが応答をカスタマイズできる新たな人工知能(AI)メソッド
人工知能の絶えず進化する風景の中で、開発者やユーザーの双方を悩ませる課題があります: 大規模言語モデルからよりカスタマイズされたニュアンス豊かな応答が求められる需要です。Llama 2などのこれらのモデルは、人間のようなテキストを生成できますが、個々のユーザーの固有の要求に対応するために本当に柔軟な回答が必要です。現在のアプローチである教師あり fine-tuning(SFT)や人間のフィードバックからの強化学習(RLHF)には限界があり、機械的で複雑な回答につながる可能性があります。 NVIDIA Researchは、これらの課題に対応する画期的な手法であるSteerLMを発表しました。SteerLMは、大規模言語モデルの応答をカスタマイズする革新的かつユーザーセントリックなアプローチを提供し、ユーザーがモデルの振る舞いを指針とする主要属性を定義することにより、より多くの制御を提供します。 SteerLMは、大規模言語モデルのカスタマイズを簡素化する4段階の教師あり fine-tuningプロセスを介して動作します。まず、人間によって注釈付けされたデータセットを使用してAttribute Prediction Modelをトレーニングし、有用性、ユーモア、創造性などの品質を評価します。次に、このモデルを使用してさまざまなデータセットに注釈を付け、言語モデルがアクセスできるデータのバラエティを向上させます。その後、SteerLMは属性条件付きの教師あり fine-tuningを使用して、指定された属性(品質など)に基づいて応答を生成するようにモデルをトレーニングします。最後に、ブートストラップトレーニングを通じてモデルを洗練し、多様な応答を生成し、最適な合わせに向けて微調整します。 SteerLMの素晴らしい機能の一つは、リアルタイムの調整可能性です。これにより、ユーザーは推論中に属性を微調整し、その場で特定のニーズに合わせることができます。この驚くべき柔軟性により、ゲーミングや教育、アクセシビリティなど、さまざまな潜在的な応用が可能となります。SteerLMにより、企業は1つのモデルから個別のアプリケーションごとにモデルを再構築する必要なく、複数のチームに対してパーソナライズされた機能を提供することができます。 SteerLMのシンプルさとユーザーフレンドリーさは、メトリクスとパフォーマンスにも明らかです。実験では、SteerLM 43BがChatGPT-3.5やLlama 30B RLHFなどの既存のRLHFモデルを凌駕し、Vicunaベンチマークで優れた結果を示しました。インフラやコードの最小限の変更で簡単な fine-tuningプロセスを提供することで、SteerLMは手間をかけずに優れた結果を提供し、AIカスタマイズの分野での重要な進展となっています。 NVIDIAは、SteerLMをNVIDIA NeMoフレームワーク内のオープンソースソフトウェアとして公開することで、高度なカスタマイズを民主化する大きな一歩を踏み出しています。開発者は、コードにアクセスしてこの技術を試す機会を得ることができます。Hugging Faceなどのプラットフォームで利用できるカスタマイズされた13B Llama 2モデルに関しても、詳細な手順が提供されています。 大規模言語モデルが進化し続ける中で、SteerLMのようなソリューションの必要性はますます重要となります。SteerLMを使用することで、よりカスタマイズ可能で適応性のあるAIシステムを提供し、ユーザーの価値観と一致した本当に助けになるAIを実現する方向に、AIコミュニティは大きな一歩を踏み出します。

このAIの論文は、テキスト変換グラフとして言語モデルパイプラインを抽象化するプログラミングモデルであるDSPyを紹介しています
言語モデル(LM)は、リサーチャーにデータを少なく使用し、より高度な理解レベルで自然言語処理システムを作成する能力を与えています。これにより、「プロンプト」メソッドや軽量なファインチューニングの技術が増加し、新しいタスクにおいてLMが動作するための方法が開発されています。ただし、問題は、各タスクごとにLMに尋ねる方法が非常に敏感であることであり、単一のプロセスで複数のLMの相互作用がある場合にこの問題がさらに複雑になります。 機械学習(ML)コミュニティは、言語モデル(LM)をプロンプトする方法や複雑なタスクに取り組むためのパイプラインの構築方法を積極的に探索しています。残念ながら、既存のLMパイプラインはしばしば、試行錯誤を重ねて見つけられた長い文字列である「プロンプトテンプレート」に依存しています。LMパイプラインの開発と最適化におけるより体系的なアプローチを追求するために、スタンフォードなどのさまざまな機関の研究者チームは、DSPyというプログラミングモデルを導入しました。DSPyは、LMパイプラインをテキスト変換グラフに抽象化するものです。これらは基本的には命令型の計算グラフであり、LMは宣言型モジュールを通じて呼び出されます。 DSPyのモジュールはパラメータ化されており、提示、ファインチューニング、拡張、推論技術の組み合わせを適用する方法を学習できます。彼らはDSPyパイプラインを最大化するためのコンパイラを設計しました。 DSPyコンパイラは、DSPyプログラムの品質やコスト効率を向上させることを目的として開発されました。コンパイラは、プログラム自体と、オプションのラベルとパフォーマンス評価のための検証メトリックを含む、少量のトレーニング入力を入力として受け取ります。コンパイラの動作は、提供された入力を使用してプログラムの異なるバージョンをシミュレートし、各モジュールのための例のトレースを生成することに関与します。これらのトレースは、自己改善の手段として使用され、効果的なフューショットプロンプトの作成やパイプラインのさまざまな段階での小規模な言語モデルのファインチューニングに活用されます。 重要な点として、DSPyの最適化方法は非常に柔軟です。彼らは「テレプロンター」と呼ばれる手法を使用しており、システムの各部分がデータから最善の方法で学習することを保証するための一般的なツールのようなものです。 2つの事例研究を通じて示されたように、簡潔なDSPyプログラムは、数学のワード問題の解決、マルチホップリトリーバルの処理、複雑な質問に答える、エージェントループを制御するなどの高度なLMパイプラインを表現し最適化することができます。コンパイル後のわずか数分で、わずか数行のDSPyコードを使用して、GPT-3.5やllama2-13b-chatを自己ブートストラップパイプラインにすることができ、従来のフューショットプロンプトに比べて25%以上および65%以上の性能を実現します。 結論として、本研究はDSPyプログラミングモデルとその関連するコンパイラを介して自然言語処理への画期的なアプローチを紹介しています。複雑なプロンプト技術をパラメータ化された宣言型モジュールに変換し、一般的な最適化戦略(テレプロンター)を活用することで、これによるNLPパイプラインの構築と最適化を非常に効率的に行う新しい方法を提供しています。

「Amazon SageMakerを使用して、マルチモダリティモデルを用いた画像からテキストへの生成型AIアプリケーションを構築する」
この投稿では、人気のあるマルチモーダリティモデルの概要を提供しますさらに、これらの事前訓練モデルをAmazon SageMakerに展開する方法も示しますさらに、特に、eコマースのゼロショットタグと属性生成および画像からの自動プロンプト生成など、いくつかの現実世界のシナリオに焦点を当てながら、これらのモデルの多様な応用についても議論します

「DINO — コンピュータビジョンのための基盤モデル」
「コンピュータビジョンにとっては、エキサイティングな10年です自然言語の分野での大成功がビジョンの領域にも移されており、ViT(ビジョントランスフォーマー)の導入などが含まれています...」(Konpyūta bijon ni totte wa, ekisaitinguna jūnen desu. Shizen gengo no bunya de no daiseikō ga bijon no ryōiki ni mo utsusarete ori, ViT…
「時間差学習と探索の重要性:図解ガイド」
最近、強化学習(RL)アルゴリズムは、タンパク質の折りたたみやドローンレースの超人レベルの到達、さらには統合などの研究課題を解決することで、注目を集めています
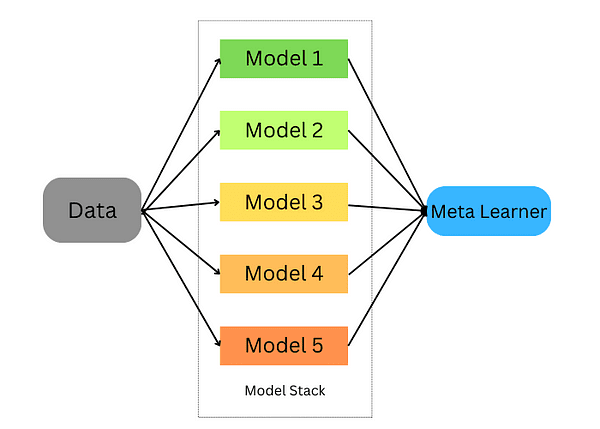
アンサンブル学習技術:Pythonでのランダムフォレストを使った手順解説
Pythonにおけるランダムフォレストの実践的な手順解説

「教師あり学習の理論と概要の理解」
この記事は、人気のある教師あり学習アルゴリズムの高レベルな概要をカバーし、初心者向けに特別に作成されています

ウェブ開発者のためのAI:プロジェクトの紹介とセットアップ
この投稿では、Qwikを使用してウェブ開発プロジェクトをブートストラップし、OpenAIのAIツールを組み込む準備を整えます

Amazon CloudWatchで、ポッドベースのGPUメトリクスを有効にします
この記事では、コンテナベースのGPUメトリクスの設定方法と、EKSポッドからこれらのメトリクスを収集する例について詳しく説明します

「ナレ・ヴァンダニャン、Ntropyの共同創設者兼CEO- インタビューシリーズ」
Ntropyの共同創設者兼CEOであるナレ・ヴァンダニアンは、開発者が100ミリ秒未満で超人的な精度で金融取引を解析することを可能にするプラットフォームを提供していますこれにより、新世代の自律型ファイナンスへの道が開かれ、以前には不可能だった製品やサービスが動作しますこのプラットフォームは、生の取引ストリームをデータの組み合わせによってコンテキスト化された構造化情報に変換します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.