Learn more about Search Results 認証 - Page 29

- You may be interested
- 音楽作曲のための変分トランスフォーマー...
- UCバークレーの研究者たちは、Gorillaとい...
- Python プロジェクトの設定:パート VI
- PandasAIの紹介:GenAIを搭載したデータ分...
- 「グラフ彩色の魅力的な世界を探索する」
- 「開発者向けの15以上のAIツール(2023年9...
- GPTとBERT:どちらが優れているのか?
- 算術推論問題のための即座のエンジニアリング
- 音から視覚へ:音声から画像を合成するAud...
- サステイナブルな銀行業務のための生成AI ...
- 「12年間のデータの旅の年末レポート」
- データサイエンスプロジェクトでのPython...
- 「LLMsの実践的な導入」
- 「ChatGPTのような生成AIを使用してペルソ...
- 連邦政府、自動車メーカーに対し、マサチ...
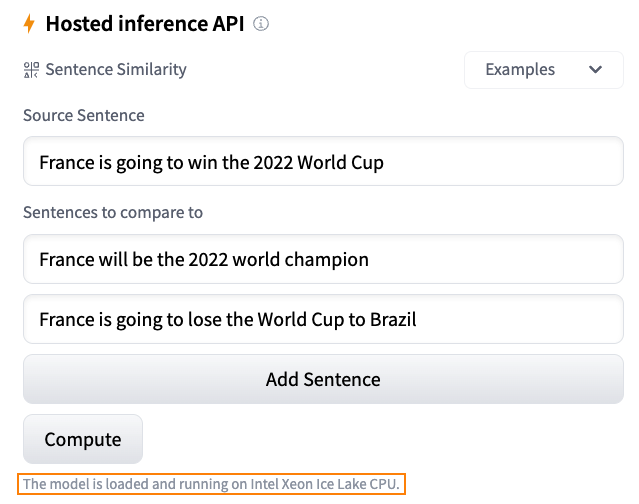
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

オーディオデータセットの完全ガイド
イントロダクション 🤗 Datasetsは、あらゆるドメインのデータセットをダウンロードして準備するためのオープンソースライブラリです。そのミニマリスティックなAPIにより、ユーザーはたった1行のPythonコードでデータセットをダウンロードして準備することができます。効率的な前処理を可能にするための一連の関数も提供されています。利用可能なデータセットの数は類を見ないものであり、ダウンロードできる最も人気のある機械学習データセットがすべて揃っています。 さらに、🤗 Datasetsにはオーディオ特化の機能も備わっており、研究者や実践者にとってもオーディオデータセットの取り扱いを容易にするものです。このブログでは、これらの機能をデモンストレーションし、なぜ🤗 Datasetsがオーディオデータセットのダウンロードと準備のためのベストな場所なのかをご紹介します。 目次 The Hub オーディオデータセットのロード ロードが簡単、処理も簡単 ストリーミングモード:銀の弾丸 The Hubのオーディオデータセットのツアー まとめ The Hub The Hugging Face Hubは、モデル、データセット、デモをホストするプラットフォームであり、すべてがオープンソースで公開されています。さまざまなドメイン、タスク、言語にわたるオーディオデータセットの成長するコレクションがあります。🤗 Datasetsとの緊密な統合により、Hubのすべてのデータセットを1行のコードでダウンロードすることができます。 Hubに移動して、タスクでデータセットをフィルタリングしましょう: Hubの音声認識データセット…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

Hugging Faceの推論エンドポイントを使用してLLMをデプロイする
オープンソースのLLMであるFalcon、(オープン-)LLaMA、X-Gen、StarCoder、またはRedPajamaは、ここ数ヶ月で大きく進化し、ChatGPTやGPT4などのクローズドソースのモデルと特定のユースケースで競合することができるようになりました。しかし、これらのモデルを効率的かつ最適化された方法で展開することはまだ課題です。 このブログ投稿では、モデルの展開を容易にするマネージドSaaSソリューションであるHugging Face Inference EndpointsにオープンソースのLLMを展開する方法と、応答のストリーミングとエンドポイントのパフォーマンステストの方法を紹介します。さあ、始めましょう! Falcon 40Bの展開方法 LLMエンドポイントのテスト JavaScriptとPythonでの応答のストリーミング 始める前に、Inference Endpointsについての知識をおさらいしましょう。 Hugging Face Inference Endpointsとは何ですか Hugging Face Inference Endpointsは、本番環境での機械学習モデルの展開を簡単かつ安全な方法で提供します。Inference Endpointsを使用することで、開発者やデータサイエンティストはインフラストラクチャの管理をせずにAIアプリケーションを作成できます。展開プロセスは数回のクリックで簡略化され、オートスケーリングによる大量のリクエストの処理、ゼロスケールへのスケールダウンによるインフラストラクチャのコスト削減、高度なセキュリティの提供などが可能となります。 LLM展開における最も重要な機能のいくつかは以下の通りです: 簡単な展開: インフラストラクチャやMLOpsの管理を必要とせず、本番用のAPIとしてモデルを展開できます。 コスト効率:…

5つの最高のDeepfake検出ツールと技術(2023年7月)
デジタル時代において、ディープフェイクはオンラインコンテンツの真正性にとって重大な脅威として浮上していますこれらの洗練されたAI生成のビデオは、本物の人物を信じられるように模倣し、事実とフィクションを区別することがますます困難になっていますしかし、ディープフェイクの背後にある技術が進化するにつれて、それらを検出するために設計されたツールや技術も進化してきました
実験追跡ツールの構築方法[Neptuneのエンジニアの学びから]
あなたのチームのMLOpsエンジニアとして、よくMLプラットフォームに機能を追加したり、データサイエンティストが利用するためのスタンドアロンツールを構築することで、彼らのワークフローを改善するように依頼されることがあります実験トラッキングはそのような機能の一つですそして、この記事を読んでいるのであれば、あなたがサポートしているデータサイエンティストはおそらく...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...

Amazon SageMakerを使用してSaaSプラットフォームを統合し、MLパワードアプリケーションを実現します
Amazon SageMakerは、データの受け入れ、変換、バイアスの測定、モデルのトレーニング、展開、および本番環境でのモデルの管理といった幅広い機能を備えたエンドツーエンドの機械学習(ML)プラットフォームですAmazon SageMaker Data Wrangler、Amazon SageMaker Studio、Amazon SageMaker Canvas、Amazon SageMaker Model Registry、Amazon SageMaker Feature Store、Amazon SageMakerなど、Amazon SageMakerは、最高クラスのコンピューティングとサービスを提供しています
自分のハードウェアでのコード理解
現在の大規模言語モデル(LLM)が実行できるさまざまなタスクの中で、ソースコードの理解は、ソフトウェア開発者やデータエンジニアとしてソースコードで作業している場合に特に興味深いものかもしれません
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.