Learn more about Search Results ボタン - Page 29

- You may be interested
- 「次元の呪い、解明される」
- 「MLOpsを活用した顧客離反予測プロジェク...
- 大規模に基礎モデルをトレーニングするた...
- 「SwiggyがZomatoとBlinkitに続き、生成AI...
- 「Decafと出会う:顔と手のインタラクショ...
- 「SQLの理解:ウィンドウ関数の始め方」
- 最適化アルゴリズム:ニューラルネットワ...
- 「力強いコネクティビティ:IoTにおけるエ...
- スターリング-7B AIフィードバックからの...
- 人間中心のメカニズム設計とデモクラティ...
- 「IoTエッジデバイスのためのクラウドベー...
- データサイエンスのワークフローにChatGPT...
- BTSの所属レーベルHYBEがAIを活用して複数...
- 「大学は、量子の未来のためにエンジニア...
- 「AI仮想アシスタントのメリットとデメリ...
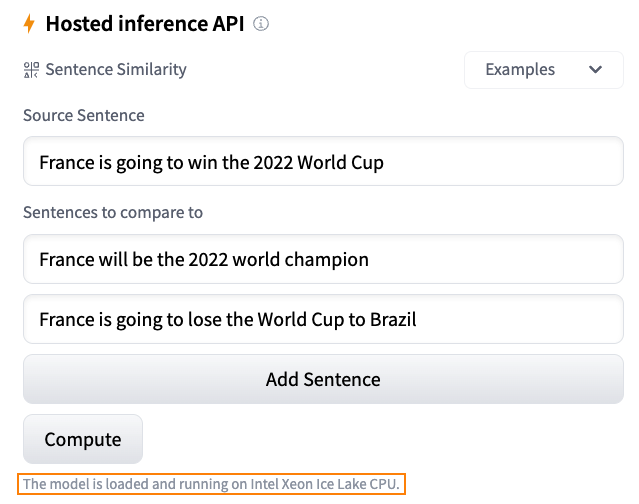
Hugging Faceにおける推論ソリューションの概要
毎日、開発者や組織はHugging Faceでホストされたモデルを採用し、アイデアを概念実証デモに、デモを本格的なアプリケーションに変えています。例えば、Transformerモデルは、自然言語処理、コンピュータビジョン、音声など、さまざまな機械学習(ML)アプリケーションの人気のあるアーキテクチャとなりました。最近では、ディフューザーがテキストから画像または画像から画像を生成するための人気のあるアーキテクチャとなりました。他のアーキテクチャも他のタスクで人気があり、私たちはそれらをすべてHF Hubでホストしています! Hugging Faceでは、最新のモデルを最小限の摩擦でテストおよび展開できる能力は、MLプロジェクトのライフサイクル全体で重要です。コストとパフォーマンスの比率を最適化することも同様に重要であり、無料のCPUベースの推論ソリューションを提供していただいたインテルの友人に感謝申し上げます。これは私たちのパートナーシップにおけるさらなる大きな一歩です。また、Intel Xeon Ice Lakeアーキテクチャによる高速化を無料でお楽しみいただけるため、ユーザーコミュニティの皆様にとっても素晴らしいニュースです。 さあ、Hugging Faceでの推論オプションを見てみましょう。 無料推論ウィジェット Hugging Faceハブでの私のお気に入りの機能の1つは、推論ウィジェットです。モデルページにある推論ウィジェットを使用すると、サンプルデータをアップロードして1クリックで予測することができます。 以下は、sentence-transformers/all-MiniLM-L6-v2モデルを使用した文の類似性の例です: モデルの動作、出力、およびデータセットのいくつかのサンプルでのパフォーマンスを素早く把握する最良の方法です。モデルはサーバー上でオンデマンドでロードされ、必要なくなるとアンロードされます。コードを書く必要はありませんし、この機能は無料です。どこが好きではないですか? 無料推論API 推論APIは、推論ウィジェットの内部で動作しています。単純なHTTPリクエストで、ハブの任意のモデルをロードし、数秒でデータを予測することができます。モデルのURLと有効なハブトークンが必要です。 以下は、xlm-roberta-baseモデルを1行でロードして予測する方法です: curl https://api-inference.huggingface.co/models/xlm-roberta-base \ -X POST \…

オーディオデータセットの完全ガイド
イントロダクション 🤗 Datasetsは、あらゆるドメインのデータセットをダウンロードして準備するためのオープンソースライブラリです。そのミニマリスティックなAPIにより、ユーザーはたった1行のPythonコードでデータセットをダウンロードして準備することができます。効率的な前処理を可能にするための一連の関数も提供されています。利用可能なデータセットの数は類を見ないものであり、ダウンロードできる最も人気のある機械学習データセットがすべて揃っています。 さらに、🤗 Datasetsにはオーディオ特化の機能も備わっており、研究者や実践者にとってもオーディオデータセットの取り扱いを容易にするものです。このブログでは、これらの機能をデモンストレーションし、なぜ🤗 Datasetsがオーディオデータセットのダウンロードと準備のためのベストな場所なのかをご紹介します。 目次 The Hub オーディオデータセットのロード ロードが簡単、処理も簡単 ストリーミングモード:銀の弾丸 The Hubのオーディオデータセットのツアー まとめ The Hub The Hugging Face Hubは、モデル、データセット、デモをホストするプラットフォームであり、すべてがオープンソースで公開されています。さまざまなドメイン、タスク、言語にわたるオーディオデータセットの成長するコレクションがあります。🤗 Datasetsとの緊密な統合により、Hubのすべてのデータセットを1行のコードでダウンロードすることができます。 Hubに移動して、タスクでデータセットをフィルタリングしましょう: Hubの音声認識データセット…

UnityゲームをSpaceにホストする方法
UnityゲームをHugging Face Spaceでホストできることを知っていますか?いいえ?そうです、できます! Hugging Face Spacesは、デモを構築、ホスト、共有するための簡単な方法です。通常は機械学習のデモに使用されますが、プレイ可能なUnityゲームもホストできます。以下にいくつかの例を示します。 Huggy Farming Game Unity APIデモ 次に、Spaceで独自のUnityゲームをホストする方法を説明します。 ステップ1:静的HTMLテンプレートを使用してSpaceを作成する まず、Hugging Face Spacesに移動してスペースを作成します。 “Static HTML”テンプレートを選択し、スペースに名前を付けて作成します。 ステップ2:Gitを使用してスペースをクローンする Gitを使用して、新しく作成したスペースをローカルマシンにクローンします。ターミナルまたはコマンドプロンプトで次のコマンドを実行することでこれを行うことができます。 git clone https://huggingface.co/spaces/{your-username}/{your-space-name} ステップ3:Unityプロジェクトを開く…

倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
ミッション:オープンで良い機械学習 私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。 MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。 ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。 私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。 倫理的なカテゴリ 私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。 ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています: 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。 コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。 詳細はhttps://huggingface.co/ethicsをご覧ください。 これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます! セーフガード オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。 私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています: コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。 ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。…

AI音声認識をUnityで
はじめに このチュートリアルでは、Hugging Face Unity APIを使用してUnityゲームに最先端の音声認識を実装する方法を案内します。この機能は、コマンドの実行、NPCへの話しかけ、アクセシビリティの向上、音声をテキストに変換する必要がある他の機能など、さまざまな用途で使用することができます。 自分自身でUnityで音声認識を試してみるには、itch.ioでライブデモをチェックしてください。 前提条件 このチュートリアルでは、Unityの基本的な知識があることを前提としています。また、Hugging Face Unity APIをインストールしている必要があります。APIの設定手順については、以前のブログ記事を参照してください。 手順 1. シーンの設定 このチュートリアルでは、プレイヤーが録音を開始および停止でき、その結果がテキストに変換される非常にシンプルなシーンを設定します。 まず、Unityプロジェクトを作成し、次の4つのUI要素を持つキャンバスを作成します。 開始ボタン:録音を開始します。 停止ボタン:録音を停止します。 テキスト(TextMeshPro):音声認識の結果が表示される場所です。 2. スクリプトの設定 SpeechRecognitionTestという名前のスクリプトを作成し、空のGameObjectにアタッチします。 スクリプト内で、UIコンポーネントへの参照を定義します。 [SerializeField]…

DuckDB Hugging Face Hubに保存されている50,000以上のデータセットを分析する
Hugging Face Hubは、誰にでもデータセットへのオープンアクセスを提供し、ユーザーがそれらを探索し理解するためのツールを提供することに特化しています。Falcon、Dolly、MPT、およびStarCoderなどの人気のある大規模言語モデル(LLM)のトレーニングに使用されるデータセットの多くを見つけることができます。不公平性や偏見を解決するためのDisaggregatorsのようなデータセット用のツールや、データセット内の例をプレビューするためのDataset Viewerなどのツールもあります。 Dataset Viewerを使用してOpenAssistantデータセットのプレビューを表示します。 私たちは、Hub上のデータセットを分析するための別の機能を最近追加しました。Hubに保存されている任意のデータセットでDuckDBを使用してSQLクエリを実行できます!2022年のStackOverflow Developer Surveyによると、SQLは3番目に人気のあるプログラミング言語です。また、分析クエリを実行するために設計された高速なデータベース管理システム(DBMS)が必要でしたので、DuckDBとの統合に興奮しています。これにより、より多くのユーザーがHub上のデータセットにアクセスし、分析することができると思います! 要約 Datasets Serverは、Hub上のすべての公開データセットをParquetファイルに自動変換します。データセットページの上部にある「Auto-converted to Parquet」ボタンをクリックすることで、それらのファイルを表示することができます。また、単純なHTTP呼び出しでParquetファイルのURLリストにアクセスすることもできます。 r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus") j = r.json() urls = [f['url'] for…

ギャラリー、図書館、アーカイブ、博物館向けのHugging Face Hub
ギャラリー、図書館、アーカイブ、博物館のためのハギングフェイスハブ ハギングフェイスハブとは何ですか? Hugging Faceは、高品質な機械学習を誰にでもアクセス可能にすることを目指しています。この目標は、広く使われているTransformersライブラリなどのオープンソースのコードライブラリを開発すること、無料のコースを提供すること、そしてHugging Faceハブを提供することなど、さまざまな方法で追求されています。 Hugging Faceハブは、人々が機械学習モデル、データセット、デモを共有しアクセスできる中央リポジトリです。ハブには19万以上の機械学習モデル、3万3000以上のデータセット、10万以上の機械学習アプリケーションとデモがホストされています。これらのモデルは、事前学習済みの言語モデル、テキスト、画像、音声分類モデル、物体検出モデル、さまざまな生成モデルなど、さまざまなタスクをカバーしています。 ハブにホストされているモデル、データセット、デモは、さまざまなドメインと言語をカバーしており、ハブを通じて利用できる範囲を拡大するための定期的なコミュニティの取り組みが行われています。このブログ記事は、ギャラリー、図書館、アーカイブ、博物館(GLAM)セクターで働く人々がハギングフェイスハブをどのように利用して貢献できるかを理解することを目的としています。 記事全体を読むか、最も関連のあるセクションにジャンプすることができます! ハブが何か分からない場合は、「ハギングフェイスハブとは何ですか?」から始めてください。 ハブで機械学習モデルを見つける方法を知りたい場合は、「ハギングフェイスハブの使用方法:ハブで関連するモデルを見つける方法」から始めてください。 ハブでGLAMデータセットを共有する方法を知りたい場合は、「ウォークスルー:GLAMデータセットをハブに追加する方法」から始めてください。 いくつかの例を見たい場合は、「ハギングフェイスハブの使用例」をチェックしてください。 ハギングフェイスハブで何を見つけることができますか? モデル Hugging Faceハブは、さまざまなタスクとドメインをカバーする機械学習モデルへのアクセスを提供しています。多くの機械学習ライブラリがHugging Faceハブとの統合を持っており、これらのライブラリを介して直接モデルを使用したりハブに共有したりすることができます。 データセット Hugging Faceハブには3万以上のデータセットがあります。これらのデータセットには、テキスト、画像、音声、マルチモーダルなど、さまざまなドメインとモダリティがカバーされています。これらのデータセットは、機械学習モデルのトレーニングや評価に価値があります。 スペース Hugging Face…

Hugging Faceのパネル
私たちは、PanelとHugging Faceのコラボレーションを発表できることを喜んでいます!🎉 Hugging Face SpacesにPanelのテンプレートを統合しました。これにより、Panelアプリを簡単に構築し、Hugging Face上で簡単にデプロイすることができます。 Panelは何を提供していますか? Panelは、Pythonで強力なツール、ダッシュボード、複雑なアプリケーションを簡単に構築できるオープンソースのPythonライブラリです。PyDataエコシステム、パワフルなデータテーブルなどがすぐに利用できるようになっています。高レベルのリアクティブAPIと低レベルのコールバックベースのAPIにより、探索的なアプリケーションを素早く構築することができます。また、複雑なマルチページアプリケーションや豊富な相互作用を持つアプリケーションを構築することも制限されません。PanelはHoloVizエコシステムの一員であり、データ探索ツールの連携エコシステムへのゲートウェイです。Panelは、他のHoloVizツールと同様に、NumFocusがスポンサーとなっており、AnacondaとBlackstoneからのサポートを受けています。 以下は、私たちのユーザーが価値を見出しているPanelのいくつかの注目すべき機能です。 Panelは、Matplotlib、Seaborn、Altair、Plotly、Bokeh、PyDeck、Vizzuなど、さまざまなプロットライブラリに広範なサポートを提供しています。 すべての相互作用は、Jupyterとスタンドアロンのデプロイメントで同じように機能します。Panelは、Jupyterノートブックからダッシュボードにコンポーネントをシームレスに統合することができ、データ探索と結果の共有の間でスムーズな移行を実現します。 Panelは、複雑なマルチページアプリケーション、高度な相互作用機能、大規模データセットの可視化、リアルタイムデータのストリーミングを構築することができます。 PyodideとWebAssemblyとの統合により、PanelアプリケーションをWebブラウザでシームレスに実行することができます。 Hugging FaceでPanelアプリを構築する準備はできましたか?Hugging Faceのデプロイメントドキュメントをチェックして、このボタンをクリックして旅を始めましょう: 🌐 コミュニティに参加しましょう Panelコミュニティは活気があり、サポートが充実しており、経験豊富な開発者やデータサイエンティストが知識を共有したり、助け合ったりすることを楽しみにしています。以下の方法で参加し、私たちとつながりましょう: Discord Discourse Twitter LinkedIn Github

リアルワールドのMLOpsの例:Brainlyでのビジュアル検索のためのエンドツーエンドのMLOpsパイプライン
シリーズ「実世界のMLOpsの例」の第2回目では、Brainlyの機械学習エンジニアであるPaweł Pęczekが、Brainlyのビジュアル検索チームにおけるエンドツーエンドの機械学習オペレーション(MLOps)プロセスを詳しく説明しますそして、MLOpsで成功するためには、技術やプロセスだけではなく、さらに詳細な情報を共有します Enjoy...

Pythonでトレーニング済みモデルを保存する方法
実世界の機械学習(ML)のユースケースに取り組む際、最適なアルゴリズム/モデルを見つけることは責任の終わりではありませんこれらのモデルを将来の使用や本番環境への展開のために保存、保管、パッケージ化することが重要ですこれらのプラクティスはいくつかの理由から必要です:再強調すると、MLモデルの保存と保管...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.