Learn more about Search Results ML - Page 295

- You may be interested
- 現代のデータエンジニアリング
- スタンフォードの研究者たちは、「EquivAc...
- ギアに乗り込んでください:「Forza Motor...
- NLP のマスタリング:ディープラーニング...
- UC San Diegoの研究者たちは、EUGENeとい...
- コロンビア大学とAppleの研究者が『フェレ...
- dtreevizを使用して、信じられないほどの...
- 「Canvaを使用して無料のAIアバターを作成...
- AGIの現実世界の課題
- 分散トレーニング:🤗 TransformersとAmaz...
- OpenAIはGPT-4 Turboを搭載した次世代AIの...
- 「ChatGPTの新たなライバル:Googleのジェ...
- 「ヘルスケアとゲノミクス産業が機械学習...
- このAIサブカルチャーのモットーは、「行...
- 日本からの新しいAI研究は、人間の表情の...

「機械学習 vs AI vs ディープラーニング vs ニューラルネットワーク:違いは何ですか?」
テクノロジーの急速な進化は、ビジネスが効率化のために洗練されたアルゴリズムにますます頼ることで、私たちの日常生活を形作っていますこのような背景の中で、私たちはしばしばバズワードを耳にします...
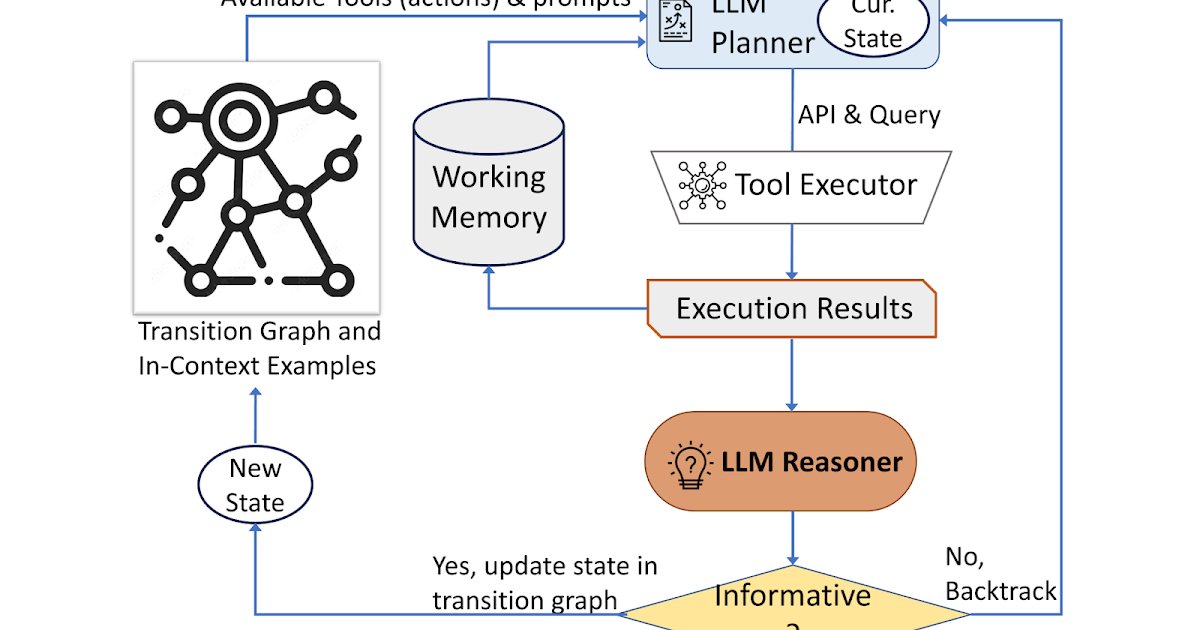
大規模な言語モデルを使用した自律型の視覚情報検索
Posted by Ziniu Hu, Student Researcher, and Alireza Fathi, Research Scientist, Google Research, Perception Team 大規模言語モデル(LLM)を多様な入力に適応させるための進展があり、画像キャプショニング、ビジュアルな質問応答(VQA)、オープンボキャブラリ認識などのタスクにおいても進展が見られています。しかし、現在の最先端のビジュアル言語モデル(VLM)は、InfoseekやOK-VQAなどのビジュアル情報検索データセットにおいて、外部の知識が必要な質問に対して十分な性能を発揮できません。 外部の知識が必要なビジュアル情報検索のクエリの例。画像はOK-VQAデータセットから取得されています。 「AVIS:大規模言語モデルによる自律型ビジュアル情報検索」という論文では、ビジュアル情報検索タスクにおいて最先端の結果を達成する新しい手法を紹介しています。この手法は、LLMと3種類のツールを統合しています:(i)画像からビジュアル情報を抽出するためのコンピュータビジョンツール、(ii)オープンワールドの知識と事実を検索するためのWeb検索ツール、および(iii)視覚的に類似した画像に関連するメタデータから関連情報を得るための画像検索ツール。AVISは、LLMパワードのプランナーを使用して各ステップでツールとクエリを選択します。また、LLMパワードの推論エンジンを使用してツールの出力を分析し、重要な情報を抽出します。ワーキングメモリコンポーネントはプロセス全体で情報を保持します。 難しいビジュアル情報検索の質問に回答するためのAVISの生成されたワークフローの例。入力画像はInfoseekデータセットから取得されています。 以前の研究との比較 最近の研究(例:Chameleon、ViperGPT、MM-ReAct)では、LLMにツールを追加して多様な入力を扱うことを試みています。これらのシステムは2つのステージのプロセスに従います:プランニング(質問を構造化プログラムや命令に分解する)および実行(情報を収集するためにツールを使用する)。基本的なタスクでは成功していますが、このアプローチは複雑な実世界のシナリオではしばしば失敗します。 また、LLMを自律エージェントとして適用することに関心が高まっています(例:WebGPT、ReAct)。これらのエージェントは環境と対話し、リアルタイムのフィードバックに基づいて適応し、目標を達成します。ただし、これらの方法では各ステージで呼び出すことができるツールに制限がなく、膨大な検索空間が生じます。その結果、現在の最先端のLLMでも無限ループに陥ったり、エラーを伝播させることがあります。AVISは、ユーザースタディからの人間の意思決定に影響を受けたガイド付きLLMの使用によってこれを解決します。 ユーザースタディによるLLMの意思決定への情報提供 InfoseekやOK-VQAなどのデータセットに含まれる多くのビジュアルな質問は、人間にとっても難しい課題であり、さまざまなツールやAPIの支援が必要とされます。以下にOK-VQAデータセットの例の質問を示します。私たちは外部ツールの使用時の人間の意思決定を理解するためにユーザースタディを実施しました。…

LangChainとPinecone Vector Databaseを使用したカスタムQ&Aアプリケーションの構築
イントロダクション 大規模な言語モデルの登場は、現代における最もエキサイティングな技術の進展の一つです。これにより、人工知能の分野でさまざまな産業において実際の問題に対する解決策を提供する無限の可能性が開かれました。これらのモデルの魅力的な応用の一つは、個人や組織のデータソースから取得した情報をもとに、カスタムの質疑応答やチャットボットを開発することです。しかし、一般的なデータで訓練された大規模言語モデルは、常にエンドユーザーにとって特定の回答または有用な回答を提供するわけではありません。この問題を解決するために、LangChainなどのフレームワークを使用して、データに基づいた特定の回答を提供するカスタムチャットボットを開発することができます。この記事では、Streamlit Cloudでの展開を伴うカスタムQ&Aアプリケーションの構築方法について学びます。 学習目標 この記事に深く入る前に、主な学習目標を以下に概説しましょう: カスタムの質疑応答のワークフロー全体を学び、各コンポーネントの役割を理解する Q&Aアプリケーションの利点を知り、カスタムの言語モデルの微調整との比較を行う Pineconeベクトルデータベースの基礎を学び、ベクトルの保存と取得を行う OpenAIの言語モデル、LangChain、およびPineconeベクトルデータベースを使用してセマンティックサーチパイプラインを構築し、Streamlitアプリケーションを開発する この記事はData Science Blogathonの一部として公開されました。 Q&Aアプリケーションの概要 出典:ScienceSoft 質疑応答または「データに基づくチャット」は、LLMsとLangChainの広範なユースケースです。LangChainは、ユースケースに対して見つけることができるすべてのデータソースをロードするための一連のコンポーネントを提供しています。LangChainは多くのデータソースとトランスフォーマーをサポートし、ベクトルデータベースに保存するために文字列のシリーズに変換します。データがデータベースに保存されたら、リトリーバーと呼ばれるコンポーネントを使用してデータベースにクエリを送信することができます。さらに、LLMsを使用することで、ドキュメントを大量に参照することなく、チャットボットのような正確な回答を得ることができます。 LangChainは以下のデータソースをサポートしています。画像で確認できるように、様々なデータソースに接続するための120以上の統合が可能です。 出典:LangChain Docs Q&Aアプリケーションのワークフロー LangChainがサポートするデータソースについて学びました。これにより、LangChainで利用可能なコンポーネントを使用して、質疑応答パイプラインを開発することができます。以下に、ドキュメントのロード、保存、リトリーバル、LLMによる出力生成に使用されるコンポーネントを示します。 ドキュメントローダー:ユーザードキュメントをベクトル化および保存するためにロードするためのコンポーネント テキストスプリッター:これらは、ドキュメントを固定のチャンク長に変換して効率的に保存するドキュメントトランスフォーマーです ベクトル保存:入力テキストのベクトル埋め込みを保存するためのベクトルデータベースの統合 ドキュメントリトリーバル:データベースからユーザークエリに基づいてテキストを取得するためのコンポーネント。類似性検索技術を使用して取得します…

「Playwrightセレクタの理解:ガイド」
Playwrightは、開発者がWebブラウザをプログラムで制御し、信頼性のあるエンドツーエンドのテストを実施するための強力で多機能な自動化ライブラリですその核心には...

AIが迷走するとき:現実世界での注目すべき機械学習のミスハップ
人工知能(AI)と機械学習の変革的な可能性は、しばしばニュースで話題になっており、様々な分野でのポジティブな影響についての報告がたくさんあります

このAI研究では、詳細な全身のジオメトリと高品質のテクスチャを持つ、リアルな3Dの服を着た人物を、単一の画像から再構築するためのテクノロジー(TeCH)を提案します
ハイフィデリティ ゲーム、ソーシャルネットワーキング、教育、eコマース、没入型テレプレゼンスなど、多くの拡張現実と仮想現実のアプリケーションにおいて、3Dデジタル人物は不可欠です。多くの手法は、野生の写真から簡単にデジタル人物を作成するために、単一の写真から3Dの服を着た人物の姿を再構築することに注力しています。しかし、非可視領域の観測の欠如により、これは以前の技術の進展にもかかわらず、この問題が不適切に見えるようになりました。色や法線推定などの明らかな視覚的手がかりを使用して、見えない部分(背面など)を予測することに失敗し、ぼやけたテクスチャと滑らかなジオメトリを生じさせました。その結果、さまざまな視点からこれらの再構築を見ると、不一致が現れます。マルチビュースーパービジョンは、この問題に対する有効な答えです。ただし、入力として単一の画像を使用しても可能でしょうか?この点で、彼らはTeCHを潜在的な解決策として提案しています。過去の研究とは異なり、TeCHは入力画像から取得したテキスト情報をカスタマイズされたテキストから画像への拡散モデルであるDreamBoothと組み合わせて再構築プロセスをガイドします。これまでの研究では、主に明らかな正面信号と非視覚領域との関係を研究してきました。 彼らは、特に単一の入力画像からセマンティック情報を主題の独自で詳細な外観に分離します。これは言葉で正確に説明することが難しいです: 1)衣服の解析モデル(SegFormer)と事前学習済みのビジュアル言語VQAモデル(BLIP)を使用して、入力画像から記述的なセマンティックプロンプトの明示的な解析を行います。これらのプロンプトには、色、服のスタイル、ヘアスタイル、顔の特徴の具体的な説明が含まれます。 2)カスタマイズされたテキストから画像への拡散モデルは、言葉で説明できない外観情報を埋め込みます。これにより、主題の独特な外観と詳細な特徴が暗黙的に決定されます。彼らは、マルチビュースコア蒸留サンプリング(SDS)、オリジナルの観測に基づく再構築損失、棚卸しの法線推定器から得られる正則化を使用して、これらの情報源に基づいて3D人間を最適化します。これにより、再構築された3D人間モデルの忠実度が向上し、元のアイデンティティが保持されます。 図1は、TeCHが単一の写真からリアルな、3Dの服を着た人物を作成できることを示しています。 浙江大学、マックスプランク知能システム研究所、モハメド・ビン・ザイード人工知能大学、北京大学の研究者たちは、DMTetに基づくハイブリッド3D表現を提案し、合理的な価格で高解像度のジオメトリを表現します。一般的な体の形を正確に描写するために、ハイブリッド3D表現は明示的な四面体グリッドと暗黙のRGBおよび符号化距離関数(SDF)フィールドを組み合わせています。最初に、この四面体グリッドを最適化し、メッシュとして表現されるジオメトリを抽出し、次に、テクスチャを2段階の最適化手法で最適化します。Techにより、統一されたカラースキームとパターンを持つ正確な3Dモデルの再現が可能になります。 その結果、キャラクターアニメーション、新しい視点のレンダリング、形状とテクスチャの操作を含む多くの下流アプリケーションが容易になります。3D服を着た人間のデータセット(CAPE)および衣装(THuman2.0)を対象とした定量的なテストでは、Techはレンダリングの品質においてSOTA手法を上回ることが証明されています。また、実世界の写真と知覚的な研究に基づく定性的な評価によると、Techはレンダリング品質においてSOTA手法を上回っています。このコードは研究目的で公開されます。
「説明的なデータの可視化の技術を取り入れる」
データの可視化は、読者に複雑なデータを表現するための強力なツールですさらに一歩進んで、ナラティブの可視化は情報を一連の物語に変換するデータストーリーを作り出すことを可能にします…

PDFとのチャット | PythonとOpenAIによるテキストの対話力の向上
イントロダクション 情報に満ちた世界で、PDFドキュメントは貴重なデータを共有および保存するための必須アイテムとなっています。しかし、PDFから洞察を抽出することは常に簡単ではありませんでした。それが「Chat with PDFs」が登場する理由です。この革新的なプロジェクトは、私たちがPDFと対話する方法を変革します。 この記事では、言語モデルライブラリ(LLM)のパワーとPyPDFのPythonライブラリの多様性を組み合わせた「Chat with PDFs」という魅力的なプロジェクトを紹介します。このユニークな融合により、PDFドキュメントと自然な会話を行うことができ、質問をすることや関連のある回答を得ることが容易になります。 学習目標 言語モデルライブラリ(LLM)についての洞察を得る。これは人間の言語パターンを理解し、意味のある応答を生成する高度なAIモデルです。 PyPDFを探求し、PDFの操作におけるテキスト抽出、マージ、分割などの機能を理解する。 言語モデルライブラリ(LLM)とPyPDFの統合により、PDFとの自然な会話を可能にする対話型チャットボットの作成方法を認識する。 この記事はData Science Blogathonの一環として公開されました。 言語モデルライブラリ(LLM)の理解 「Chat with PDFs」の中心にあるのは、言語モデルライブラリ(LLM)です。これは大量のテキストデータで訓練された高度なAIモデルです。これらは言語の専門家のような存在であり、人間の言語パターンを理解し、意味のある応答を生成することができます。 私たちのプロジェクトでは、LLMは対話型チャットボットの作成において重要な役割を果たしています。このチャットボットは、あなたの質問を処理し、PDFから必要な情報を理解することができます。PDFに隠された知識を活用して、役立つ回答と洞察を提供することができます。 PyPDFs – あなたのPDFスーパーアシスタント PyPDFは、PDFファイルとのやり取りを簡素化する多機能なPythonライブラリです。テキストの抽出、結合、分割など、さまざまな機能を利用できます。このライブラリは、PDFの処理と分析を効率化するために私たちのプロジェクトにおいて重要な役割を果たしています。 PyPDFを使用することで、PDFファイルをロードし、そのテキストを抽出することができます。これにより、効率的な処理と分析の準備が整いました。この強力なアシスタントを使用して、PDFとの対話をスムーズに行うことができます。…

組合せ最適化によるニューラルネットワークの剪定
Posted by Hussein Hazimeh、Athenaチームの研究科学者、およびMITの大学院生であるRiade Benbakiによる投稿 近代的なニューラルネットワークは、言語、数学的推論、ビジョンなど、さまざまなアプリケーションで印象的なパフォーマンスを達成しています。しかし、これらのネットワークはしばしば大規模なアーキテクチャを使用し、多くの計算リソースを必要とします。これにより、特にウェアラブルやスマートフォンなどのリソース制約のある環境では、このようなモデルをユーザーに提供することが実用的ではありません。事前学習済みネットワークの推論コストを軽減するための広く使用されている手法は、いくつかの重みを削除することによる枝刈りですが、これはネットワークの有用性にほとんど影響を与えない方法で行われます。標準的なニューラルネットワークでは、各重みは2つのニューロン間の接続を定義します。したがって、重みが剪定された後、入力はより小さな一連の接続を介して伝播し、より少ない計算リソースを必要とします。 元のネットワークと剪定されたネットワークの比較。 枝刈り手法は、ネットワークのトレーニングプロセスのさまざまな段階で適用できます。トレーニング後、トレーニング中、またはトレーニング前(つまり、重みの初期化直後)に適用できます。この投稿では、トレーニング後の設定に焦点を当てています。つまり、事前学習済みネットワークが与えられた場合、どの重みを剪定すべきかをどのように決定できるかという問題です。最も一般的な手法の1つは、マグニチュード剪定です。この手法では、最も小さい絶対値を持つ重みを削除します。効率的ではありますが、この手法は重みの削除がネットワークのパフォーマンスに与える影響を直接考慮しません。もう1つの一般的な手法は、最小化された損失関数に対する重みの影響度に基づいて重みを削除する最適化ベースの剪定です。概念的には魅力的ですが、既存の最適化ベースの手法の多くは、パフォーマンスと計算要件の間に深刻なトレードオフがあるようです。粗い近似を行う手法(例:対角ヘッシアン行列を仮定する)はスケーラブル性が高く、パフォーマンスは比較的低いです。一方、より少ない近似を行う手法はパフォーマンスが向上する傾向がありますが、スケーラブル性ははるかに低いようです。 「Fast as CHITA: Neural Network Pruning with Combinatorial Optimization」は、ICML 2023で発表された論文で、事前学習済みニューラルネットワークの剪定において、スケーラビリティとパフォーマンスのトレードオフを考慮した最適化ベースのアプローチを開発した方法について説明しています。CHITA(「Combinatorial Hessian-free Iterative Thresholding Algorithm」の略)は、高次元統計、組合せ最適化、およびニューラルネットワークの剪定など、いくつかの分野の進歩を活用しています。たとえば、CHITAはResNetの剪定において最先端の手法よりも20倍から1000倍高速であり、多くの設定で精度を10%以上向上させることができます。 貢献の概要 CHITAには、人気のある手法に比べて2つの注目すべき技術的改善点があります:…
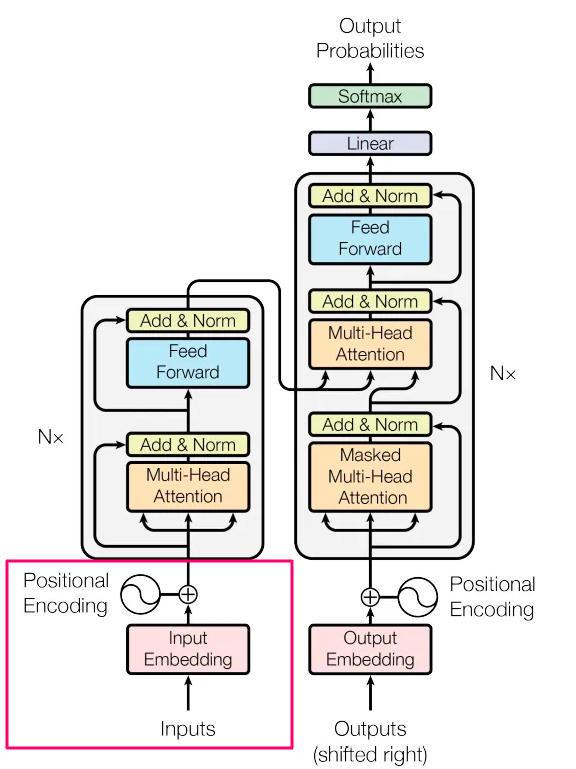
「トランスフォーマーの簡素化:理解できる単語を使った最先端の自然言語処理(NLP)-パート2- 入力」
ドラゴンは卵から孵り、赤ちゃんはおなかから飛び出し、AIに生成されたテキストは入力から始まります私たちはみんなどこかから始めなければなりません どんな種類の入力ですか?それは手元のタスクによりますもしもあなたが構築しているならば...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.