Learn more about Search Results 認証 - Page 28

- You may be interested
- OpenAIのCEOであるSam Altman氏:AIの力が...
- 「欧州宇宙機関は、AIが衛星ナビゲーショ...
- 「Plotlyを使用したダイナミックなコロプ...
- 「500のゲームとアプリが現在RTXによって...
- トロント大学の研究者が、大規模な材料デ...
- 最新のデータを使ってファンデーションモ...
- DALLE-3の5つの使用例
- TensorFlowを使用したGANの利用による画像...
- ケンブリッジの研究者たちは、マシンラー...
- ラストでクロスプラットフォームのTFIDFテ...
- 新しいZeroscope v2モデルに会ってくださ...
- 即座のハッキングとLLMの誤用
- 「A.I.ツールが手術台で脳腫瘍を診断」
- 「ジェネラティブAI:2024年の人事におけ...
- ランナーの疲労検知のための時間系列分類 ...
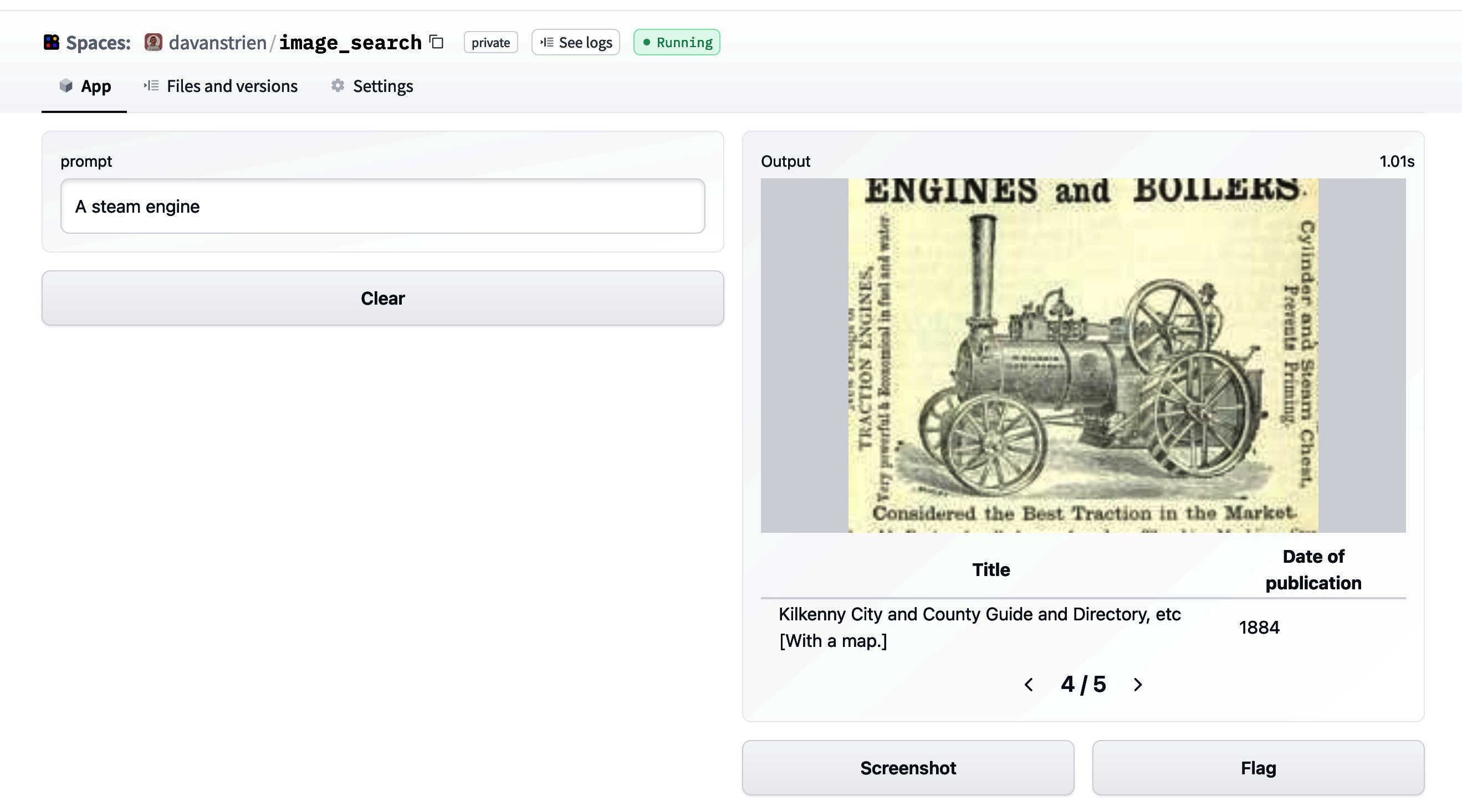
🤗データセットを使った画像検索
🤗 datasetsは、データセットに簡単にアクセスして共有することができるライブラリです。また、メモリに収まらないデータを効率的に処理することも容易にします。 datasetsが最初にリリースされた当初は、主にテキストデータと関連していました。しかし、最近では、datasetsは音声や画像に対するサポートを増やしています。特に、画像のためのdatasetsの機能タイプが追加されました。以前のブログ投稿では、datasetsと🤗 transformersを組み合わせて画像分類モデルのトレーニング方法を紹介しました。このブログ投稿では、datasetsと他のいくつかのライブラリを組み合わせて画像検索アプリケーションを作成する方法を見ていきます。 まず、datasetsをインストールします。画像を扱うために、pillowもインストールします。さらに、sentence_transformersとfaissも必要です。これらについては後ほど詳しく説明します。また、richもインストールします。ここでは簡単に使用するだけですが、非常に便利なパッケージなので、ぜひ詳しく探索してみてください! !pip install datasets pillow rich faiss-gpu sentence_transformers まずは、画像の特徴を見てみましょう。素晴らしいライブラリであるrichを使用して、Pythonオブジェクト(関数、クラスなど)を調べることができます。 from rich import inspect import datasets inspect(datasets.Image, help=True) ╭───────────────────────── <class 'datasets.features.image.Image'>…

機械学習でパワーアップした顧客サービス
このブログ投稿では、実際の顧客サービスのユースケースをシミュレートし、Hugging Faceエコシステムの機械学習ツールを使用してそれに対処します。 強くお勧めするのは、このノートブックをテンプレート/例として使用して、あなた自身の実世界のユースケースを解決することです。 タスク、データセット、モデルの定義 実際のコーディングに取り掛かる前に、自動化または一部自動化したいユースケースの明確な定義を持つことが重要です。ユースケースの明確な定義は、最適なタスク、使用するデータセット、および適用するモデルを特定するのに役立ちます。 NLPタスクの定義 では、自然言語処理モデルを使用して解決したい仮想的な問題について考えてみましょう。私たちは製品を販売しており、顧客サポートチームはフィードバック、クレーム、質問を含む数千のメッセージを受け取っています。理想的には、これらのメッセージにすべて返答する必要があります。 すぐに明らかになるのは、顧客サポートがすべてのメッセージに返信することは不可能であるということです。したがって、私たちは最も不満な顧客にのみ返信し、これらのメッセージに100%回答することを決定します。それらは中立的なメッセージや肯定的なメッセージと比べて最も緊急性があると考えられるためです。 非常に不満な顧客のメッセージが全メッセージの一部であると仮定し、不満なメッセージを自動的にフィルタリングできるとすると、顧客サポートはこの目標を達成できるはずです。 不満なメッセージを自動的にフィルタリングするために、自然言語処理技術を適用する予定です。 最初のステップは、私たちのユースケース(不満なメッセージのフィルタリング)を機械学習タスクにマッピングすることです。 Hugging Face Hubのタスクページは、与えられたシナリオに最も適したタスクを確認するための素晴らしい場所です。各タスクには詳細な説明と潜在的な使用例があります。 最も不満な顧客のメッセージを見つけるタスクは、テキスト分類のタスクとしてモデル化できます。メッセージを次の5つのカテゴリのいずれかに分類します:非常に不満、不満、中立、満足、または非常に満足。 適切なデータセットの見つけ方 タスクを決定したら、次にモデルをトレーニングするためのデータを見つける必要があります。これはユースケースのパフォーマンスにとって通常はモデルアーキテクチャを選ぶよりも重要です。モデルはトレーニングされたデータの質によってのみ優れた性能を発揮します。したがって、データセットの選択と作成には非常に注意が必要です。 不満なメッセージのフィルタリングという仮想的なユースケースを考えると、使用可能なデータセットを見てみましょう。 実際のユースケースでは、おそらくNLPシステムが処理する実際のデータを最もよく表す内部データがあるでしょう。したがって、そのような内部データをNLPシステムのトレーニングに使用するべきです。ただし、モデルの汎用性を向上させるために公開されているデータも含めることは役立ちます。 Hugging Face Hubの利用可能なデータセットをすべて見てみましょう。左側にはタスクカテゴリやより具体的なタスクに基づいてデータセットをフィルタリングできます。私たちのユースケースはテキスト分類 -> 感情分析に対応しているので、これらのフィルタを選択しましょう。このノートブックの執筆時点では、約80のデータセットが残ります。データセットを選ぶ際には、次の2つの側面を評価する必要があります:…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

Twitterでの感情分析を始める
センチメント分析は、テキストデータをその極性(ポジティブ、ネガティブ、ニュートラルなど)に基づいて自動的に分類するプロセスです。企業は、ツイートのセンチメント分析を活用して、顧客が自社製品やサービスについてどのように話しているかを把握し、ビジネスの意思決定に洞察を得ること、製品の問題や潜在的なPR危機を早期に特定することができます。 このガイドでは、Twitterでのセンチメント分析を始めるために必要なすべてをカバーします。コーダーと非コーダーの両方向けに、ステップバイステップのプロセスを共有します。コーダーの場合、Inference APIを使用してツイートのセンチメント分析を簡単なコード数行でスケールして行う方法を学びます。コーディング方法を知らない場合でも心配ありません!Zapierを使用してセンチメント分析を行う方法もカバーします。Zapierはツイートを収集し、Inference APIで分析し、最終的に結果をGoogle Sheetsに送信するためのノーコードツールです⚡️ 一緒に読んで興味があるセクションにジャンプしてください🌟: センチメント分析とは何ですか? コーディングを使用したTwitterセンチメント分析の方法は? コーディングを使用せずにTwitterセンチメント分析を行う方法は? 準備ができたら、楽しんでください!🤗 センチメント分析とは何ですか? センチメント分析は、機械学習を使用して人々が特定のトピックについてどのように話しているかを自動的に識別する方法です。センチメント分析の最も一般的な用途は、テキストデータの極性(つまり、ツイートや製品レビュー、サポートチケットが何かについてポジティブ、ネガティブ、またはニュートラルに話しているかを自動的に識別すること)の検出です。 例として、@Salesforceをメンションしたいくつかのツイートをチェックして、センチメント分析モデルによってどのようにタグ付けされるかを確認してみましょう: “The more I use @salesforce the more I dislike it. It’s…
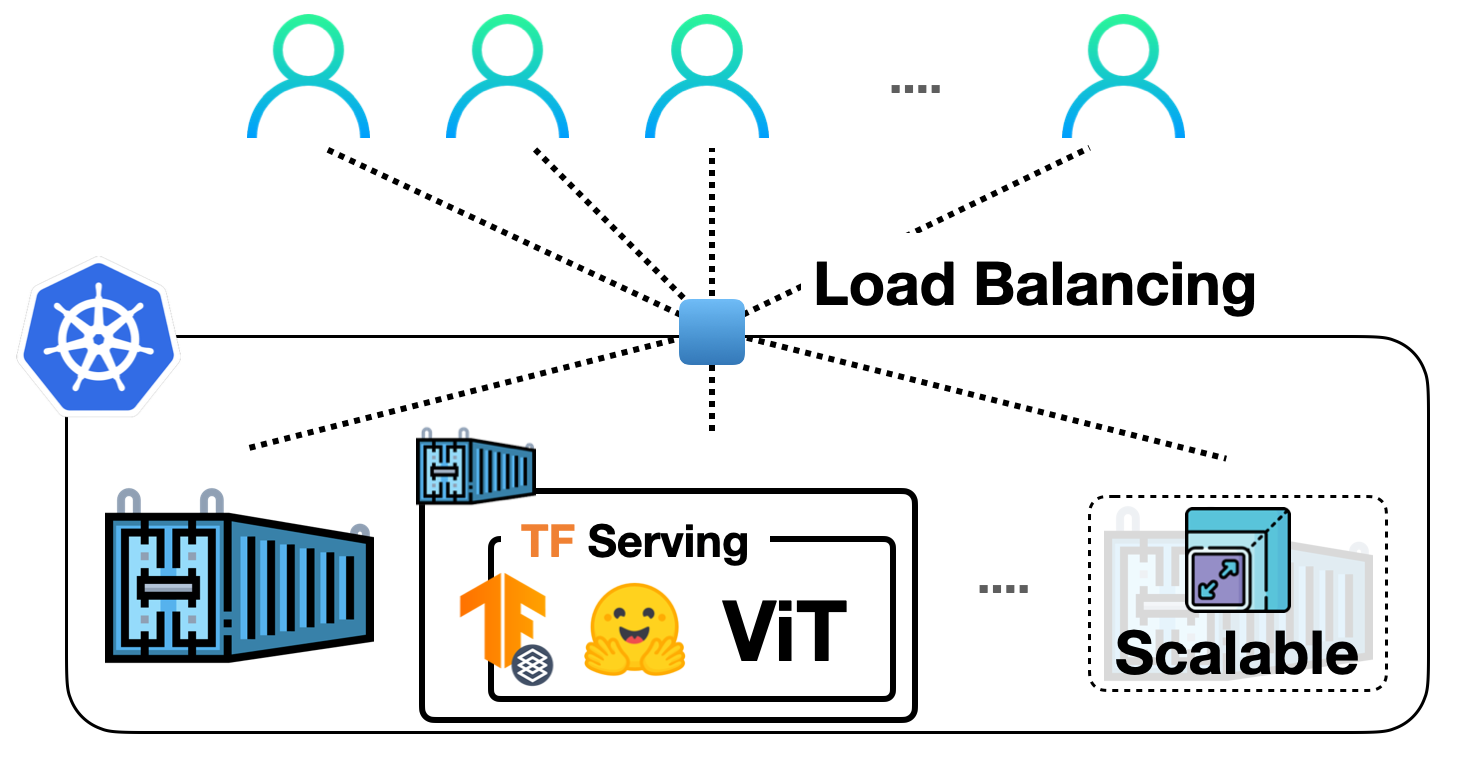
TF Servingを使用してKubernetes上に🤗 ViTをデプロイする
前の投稿では、TensorFlow Servingを使用して🤗 TransformersからVision Transformer(ViT)モデルをローカルに展開する方法を示しました。ビジョントランスフォーマーモデル内での埋め込み前処理および後処理操作、gRPCリクエストの処理など、さまざまなトピックをカバーしました! ローカル展開は、有用なものを構築するための優れたスタート地点ですが、実際のプロジェクトで多くのユーザーに対応できる展開を実行する必要があります。この投稿では、前の投稿のローカル展開をDockerとKubernetesでスケーリングする方法を学びます。したがって、DockerとKubernetesに関する基本的な知識が必要です。 この投稿は前の投稿に基づいていますので、まずそれをお読みいただくことを強くお勧めします。この投稿で説明されているコードは、このリポジトリで確認することができます。 私たちの展開をスケールアップする基本的なワークフローは、次のステップを含みます: アプリケーションロジックのコンテナ化:アプリケーションロジックには、リクエストを処理して予測を返すサービスモデルが含まれます。コンテナ化するために、Dockerが業界標準です。 Dockerコンテナの展開:ここにはさまざまなオプションがあります。最も一般的に使用されるオプションは、DockerコンテナをKubernetesクラスターに展開することです。Kubernetesは、展開に便利な機能(例:自動スケーリングとセキュリティ)を提供します。ローカルでKubernetesクラスターを管理するためのMinikubeのようなソリューションや、Elastic Kubernetes Service(EKS)のようなサーバーレスソリューションを使用することもできます。 SagemakerやVertex AIのような、MLデプロイメント固有の機能をすぐに利用できる時代に、なぜこのような明示的なセットアップを使用するのか疑問に思うかもしれません。それは考えるのは当然です。 上記のワークフローは、業界で広く採用され、多くの組織がその恩恵を受けています。長年にわたってすでに実戦投入されています。また、複雑な部分を抽象化しながら、展開に対してより細かな制御を持つことができます。 この投稿では、Google Kubernetes Engine(GKE)を使用してKubernetesクラスターをプロビジョニングおよび管理することを前提としています。GKEを使用する場合、請求を有効にしたGCPプロジェクトが既にあることを想定しています。また、GKEで展開を行うためにgcloudユーティリティを構成する必要があります。ただし、Minikubeを使用する場合でも、この投稿で説明されているコンセプトは同様に適用されます。 注意:この投稿で表示されるコードスニペットは、gcloudユーティリティとDocker、kubectlが構成されている限り、Unixターミナルで実行できます。詳しい手順は、付属のリポジトリで入手できます。 サービングモデルは、生のイメージ入力をバイトとして処理し、前処理および後処理を行うことができます。 このセクションでは、ベースのTensorFlow Servingイメージを使用してそのモデルをコンテナ化する方法を示します。TensorFlow Servingは、モデルをSavedModel形式で消費します。前の投稿でSavedModelを取得した方法を思い出してください。ここでは、SavedModelがtar.gz形式で圧縮されていることを前提としています。万が一必要な場合は、ここから入手できます。その後、SavedModelは<MODEL_NAME>/<VERSION>/<SavedModel>という特別なディレクトリ構造に配置する必要があります。これにより、TensorFlow Servingは異なるバージョンのモデルの複数の展開を同時に管理できます。 Dockerイメージの準備…

Skopsの紹介
Skopsの紹介 Hugging Faceでは、オープンソースの機械学習に関するさまざまな問題に取り組んでおり、モデルの安全なホスティングや公開、再現性、説明可能性、コラボレーションなどを可能にしています。私たちは、新しいライブラリ「Skops」をご紹介できることを大変嬉しく思っています!Skopsを使用すると、scikit-learnモデルをHugging Face Hubにホストしたり、モデルのドキュメント用のモデルカードを作成したり、他の人と共同作業したりすることができます。 まず、モデルをトレーニングしてから、Skopsを使用してステップバイステップでsklearnを本番環境で活用する方法を見ていきましょう。 # ライブラリをインポートしましょう import sklearn from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split # データをロードして分割します…
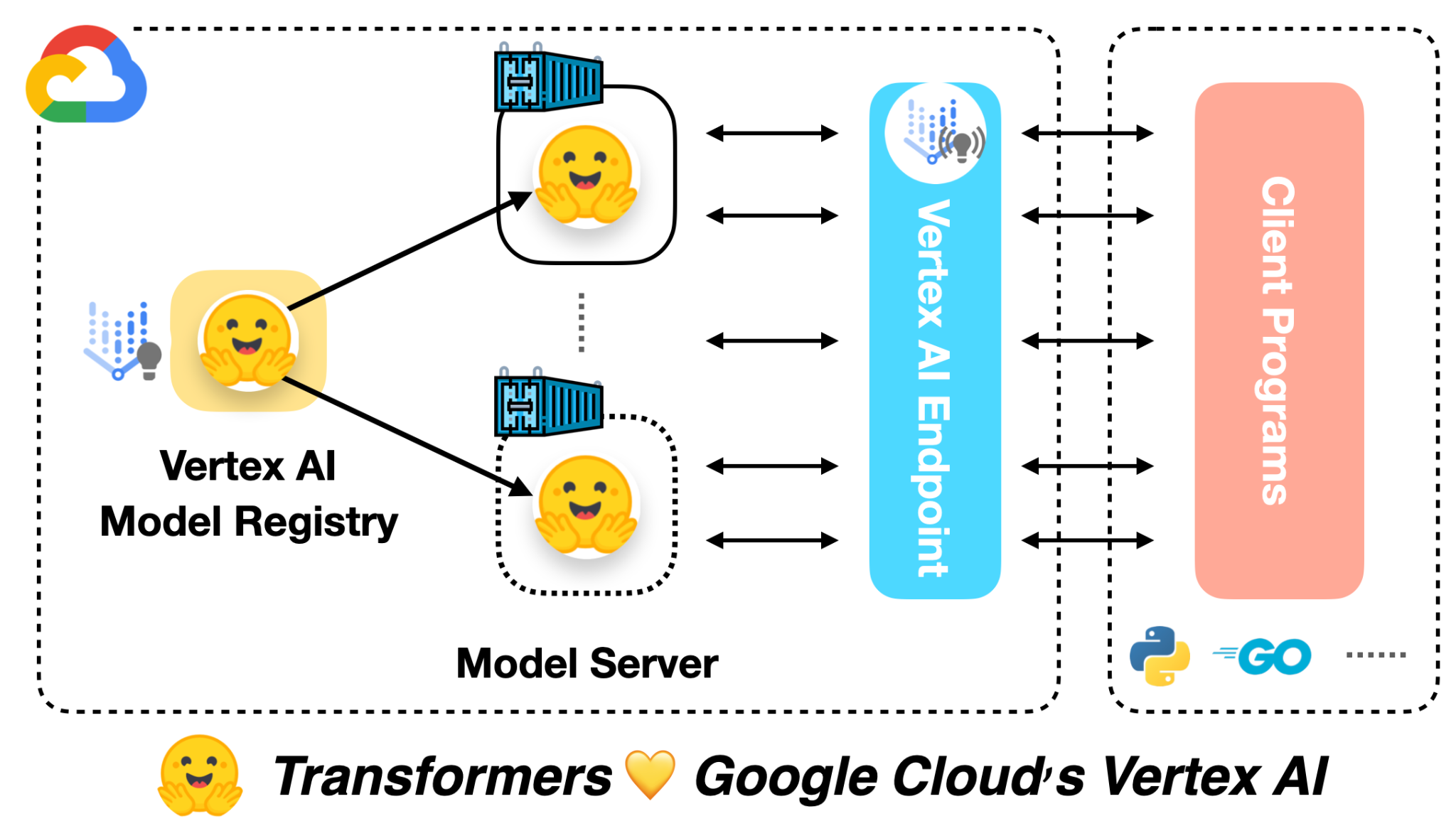
🤗 ViTをVertex AIに展開する
前の投稿では、Vision Transformers(ViT)モデルを🤗 Transformersを使用してローカルおよびKubernetesクラスター上に展開する方法を紹介しました。この投稿では、同じモデルをVertex AIプラットフォームに展開する方法を示します。Kubernetesベースの展開と同じスケーラビリティレベルを実現できますが、コードは大幅に簡略化されます。 この投稿は、上記にリンクされた前の2つの投稿を基に構築されています。まだチェックしていない場合は、それらを確認することをお勧めします。 この投稿の冒頭にリンクされたColab Notebookには、完全に作成された例があります。 Google Cloudによると: Vertex AIは、さまざまなモデルタイプと異なるレベルのMLの専門知識をサポートするツールを提供します。 モデルの展開に関しては、Vertex AIは次の重要な機能を統一されたAPIデザインで提供しています: 認証 トラフィックに基づく自動スケーリング モデルのバージョニング 異なるバージョンのモデル間のトラフィックの分割 レート制限 モデルの監視とログ記録 オンラインおよびバッチ予測のサポート TensorFlowモデルに対しては、この投稿で紹介されるいくつかの既製のユーティリティが提供されます。ただし、PyTorchやscikit-learnなどの他のフレームワークにも同様のサポートがあります。 Vertex AIを使用するには、請求が有効なGoogle Cloud…

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…
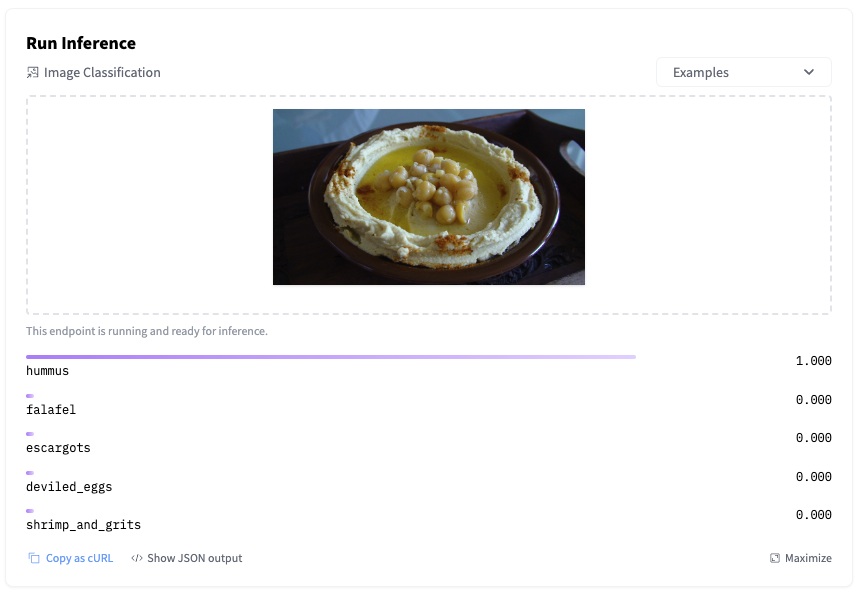
ハギングフェイス推論エンドポイントの始め方
機械学習モデルのトレーニングは非常に簡単になりました。特に、事前学習済みモデルと転移学習の台頭により、簡単なことが多いです。もちろん、時にはそれほど簡単ではないこともありますが、少なくとも、モデルのトレーニングはクリティカルなアプリケーションを壊すことはありませんし、お客様にサービス品質に不満を抱かせることもありません。しかし、モデルのデプロイメントは別ですね… はい、みんな経験があります。 モデルを本番環境でデプロイするには、通常、数々の手順を踏む必要があります。モデルをコンテナにパッケージ化し、インフラストラクチャをプロビジョニングし、予測APIを作成し、セキュリティを確保し、スケーリングし、監視するなどです。正直に言って、これらのプラミングを構築するのには実際の機械学習作業の貴重な時間が奪われてしまいます。残念なことに、うまくいかないこともあります。 私たちは、新しく発表されたHugging Face Inference Endpointsを使ってこの問題を解決しようと努めています。最新の状態を維持しつつ、機械学習をますます簡単にすることを目指して、Hugging Faceハブから直接機械学習モデルをお気に入りのクラウド上の管理されたインフラストラクチャに数回のクリックでデプロイできるサービスを構築しました。シンプルで安全でスケーラブルです。すべてが手に入ります。 では、これがどのように機能するかをご紹介します! Inference Endpointsでモデルをデプロイする Inference Endpointsがサポートしているタスクのリストを見て、最近AutoTrainでfood101データセット上で微調整したSwin画像分類モデルをデプロイすることにしました。このモデルの構築方法に興味がある場合は、このビデオで全体のプロセスを確認できます。 モデルページから、デプロイをクリックし、Inference Endpointsを選択します。 これにより、エンドポイントの作成ページに直接移動します。 最新のリビジョンのモデルを、eu-west-1リージョンのAWSでホストされる単一のGPUインスタンスにデプロイすることにしました。オプションで、オートスケーリングを設定することもできますし、カスタムコンテナにモデルをデプロイすることもできます。 次に、エンドポイントにアクセスできるユーザーを決定する必要があります。最もセキュアから最もセキュアまで、3つのオプションがあります: パブリック: エンドポイントはパブリックなHugging Faceサブネットで実行され、認証なしでインターネット上の誰でもアクセスできます。これを選択する前によく考えてください! プロテクテッド: エンドポイントはパブリックなHugging Faceサブネットで実行され、適切な組織トークンを持つインターネット上の誰でもアクセスできます。…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.