Learn more about Search Results ボタン - Page 28

- You may be interested
- 「データサイエンスをマスターするための...
- 「生成AIの新たなフロンティア—クラウドか...
- 「2人の上院議員が、A.I.法律のための両党...
- MLOpsとは何ですか
- 「初心者のためのバイトペアエンコーディ...
- 「FAANGまたはスタートアップでキャリアを...
- A/Bテストを超えたアプローチで戦略を最適...
- 「2023年に使用するためのトップ9のデータ...
- 「暖かい抱擁の向こう側:ハグの奥深くに...
- 「DatabricksがMosaicMLとその他の最近のA...
- ビンガムトン大学の研究者たちは、社会的...
- Hugging Face Spacesでタンパク質を可視化...
- 「AIの力を解き放つ – VoAGIとMachi...
- 「Langchainの使い方:ステップバイステッ...
- 古い地図を使って、失われた地域の3Dデジ...

🤗 Hubでのスーパーチャージド検索
huggingface_hubライブラリは、ホスティングエンドポイント(モデル、データセット、スペース)を探索するためのプログラム的なアプローチを提供する軽量なインタフェースです。 これまでは、このインタフェースを介してハブでの検索は難しく、ユーザーは「知っているだけ」で慣れなければならない多くの側面がありました。 この記事では、huggingface_hubに追加されたいくつかの新機能を紹介し、ユーザーにJupyterやPythonインタフェースを離れずに使用したいモデルやデータセットを検索するためのフレンドリーなAPIを提供します。 始める前に、システムに最新バージョンのhuggingface_hubライブラリがない場合は、次のセルを実行してください: !pip install huggingface_hub -U 問題の位置づけ: まず、自分がどのようなシナリオにいるか想像してみましょう。テキスト分類のためにハブでホストされているすべてのモデルを見つけたいとします。これらのモデルはGLUEデータセットでトレーニングされ、PyTorchと互換性があります。 https://huggingface.co/models を単に開いてそこにあるウィジェットを使用することもできます。しかし、これによりIDEを離れて結果をスキャンする必要がありますし、必要な情報を得るためにはいくつかのボタンクリックが必要です。 もしもIDEを離れずにこれを解決する方法があったらどうでしょうか?プログラム的なインタフェースであれば、ハブを探索するためのワークフローにも簡単に組み込めるかもしれません。 ここでhuggingface_hubが登場します。 このライブラリに慣れている方は、すでにこの種のモデルを検索できることを知っているかもしれません。しかし、クエリを正しく取得することは試行錯誤の痛ましいプロセスです。 それを簡略化することはできるでしょうか?さあ、見てみましょう! 必要なものを見つける まず、HfApiをインポートします。これはHugging Faceのバックエンドホスティングと対話するのに役立つクラスです。モデル、データセットなどを通じて対話することができます。さらに、いくつかのヘルパークラスもインポートします:ModelFilterとModelSearchArguments from huggingface_hub import HfApi, ModelFilter,…

機械学習の専門家 – マーガレット・ミッチェル
みなさん、こんにちは!Machine Learning Expertsへようこそ。私は司会のBritney Mullerです。今日のゲストは、マーガレット・ミッチェル(通称メグ)です。メグはGoogleのEthical AIグループの創設者兼共同リーダーであり、機械学習の分野でのパイオニアであり、50以上の論文を発表しているだけでなく、Ethical AIの分野でのリーディングリサーチャーでもあります。 メグがエシカルAIの重要性に気づいた瞬間(素晴らしいストーリー!)、MLチームが有害なデータバイアスにより意識的になる方法、およびMLにおける包括性と多様性の力(およびパフォーマンスの利点)について話すことができます。 このパワフルなエピソードをご紹介できることをとても楽しみにしています!こちらがメグ・ミッチェルとの対談です: 転写: 注:転写はわかりやすい読みやすさを提供するためにわずかに修正/再フォーマットされています。 あなたの経歴とHugging Faceへの経緯について少し共有していただけますか? Dr. マーガレット・ミッチェルの経歴: Reed Collegeで言語学の学士号を取得 – NLPに取り組んだ 学士号取得後、補助および補完技術に取り組み、修士課程中も同様に研究 ワシントン大学で計算言語学の修士号を取得 コンピュータサイエンスの博士号を取得 メグ:私はJohns Hopkinsでポスドクとして統計的な研究を行い、その後、Microsoft Researchに移り、ビジョンから言語生成に取り組み、盲目の人々が世界をより簡単に移動できるようにするSeeing…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

Gradio 3.0 がリリースされました!
機械学習デモ 機械学習デモは、モデルのリリースにおいてますます重要な役割を果たしています。デモを使用することで、MLエンジニアに限らず誰でもブラウザ上でモデルを試し、予測にフィードバックを提供し、モデルがうまく機能する場合にはモデルへの信頼を築くことができます。 2019年の初版以来、Gradioライブラリを使用して600,000以上のMLデモが作成されています。そして今日、私たちはうれしいことに、Gradio 3.0の発表をお知らせできます!Gradioライブラリの完全な再設計です🥳 Gradio 3.0の新機能 🔥 Gradioユーザーからのフィードバックに基づいた、フロントエンドの完全な再設計: Gradioフロントエンドの構築には、Svelteなどの最新技術を使用しています。その結果、ペイロードが非常に小さく、ページの読み込みも非常に高速になりました! また、よりクリーンなデザインにも取り組んでおり、Gradioデモが視覚的により多くの設定に適合するようになりました(ブログ記事に埋め込まれるなど)。 CSVファイルをドラッグアンドドロップしてDataframeに入力するなど、既存のコンポーネントであるDataframeをよりユーザーフレンドリーに改良し、Galleryなどの新しいコンポーネントを追加して、モデルに適したUIを構築できるようにしました。 新たにTabbedInterfaceクラスを追加しました。これにより、関連するデモを1つのWebアプリケーション内の複数のタブとしてグループ化することができます。 すべての使用可能なコンポーネントについては、(再設計された)ドキュメントをご覧ください🤗! 🔥 Pythonで複雑なカスタムWebアプリを構築できる新しい低レベル言語Gradio Blocksを作成しました: なぜBlocksを作成したのでしょうか?Gradioデモは非常に簡単に構築できますが、デモのレイアウトやデータのフローに対してより細かい制御をしたい場合はどうでしょうか?たとえば、以下のようなことができるようになります: 入力を左側にまとめ、出力を右側にまとめるデモのレイアウトを変更する 1つのモデルの出力を次のモデルの入力とするような、マルチステップのインターフェースを持つか、一般的にはより柔軟なデータフローを持つ ユーザーの入力に基づいてコンポーネントのプロパティ(例:ドロップダウンの選択肢)や表示状態を変更する 低レベルのBlocks APIを使用すると、すべての操作をPythonで実行できます。 次に、2つのシンプルなデモを作成し、タブを使用してそれらをグループ化するBlocksデモの例を示します: import…
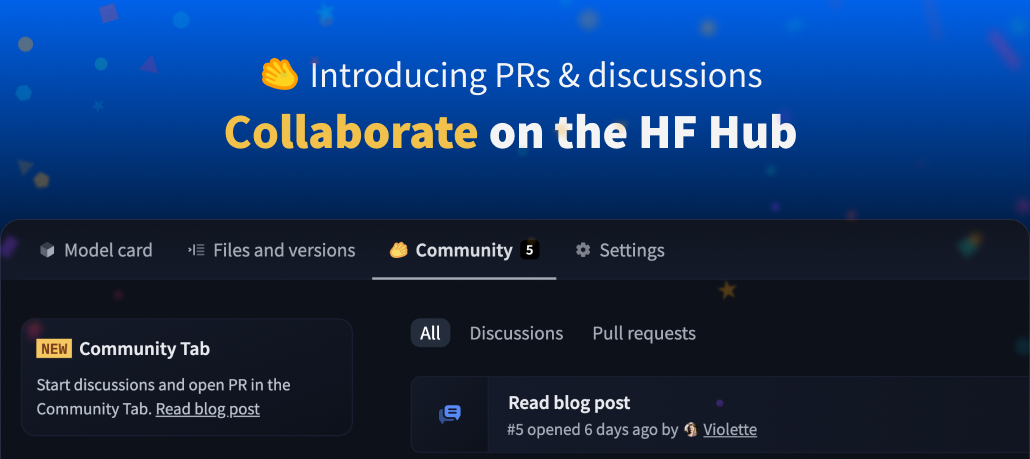
プルリクエストとディスカッションの紹介 🥳
私たちは、Hugging Face Hubでの最新の共同作業機能、プルリクエストとディスカッションのリリースを大いに喜んでお知らせします! プルリクエストとディスカッションは、モデル、データセット、およびスペースのすべてのリポジトリタイプのコミュニティタブの下で今日から利用可能です。コミュニティのメンバーは、ディスカッションとプルリクエストを作成し、参加することができます。これにより、チーム内だけでなく、コミュニティの他のすべての人とも協力が可能になります! これは、Hubで行われた最大のアップデートであり、コミュニティメンバーがそれを使って協力を始めるのを楽しみにしています 🤩。 新しい「コミュニティ」タブは、これまでの倫理的な機械学習の提案とも一致しています。フィードバックとイテレーションは、倫理的な機械学習ソフトウェアの開発において中心的な役割を果たします。私たちは、それをコミュニティのツールセットに持っていることで、ML、コラボレーション、進歩に新しい種類のポジティブなパターンが生まれると本当に信じています。 ディスカッションとプルリクエストの例としては、次のようなものがあります: 倫理的なバイアスの開示を改善するためのモデルカードへの提案を行う。 特定のスペースデモの懸念を引き起こす生成物をユーザーがフラグする。 モデルとデータセットの作成者がコミュニティメンバーと直接ディスカッションできる場を提供する。 他の人がリポジトリを改善できるようにする!例えば、ユーザーはTensorFlowのウェイトを提供したいかもしれません! ディスカッション ディスカッションでは、コミュニティメンバーが質問をしたり回答したり、アイデアや提案をリポジトリの所有者やコミュニティと直接共有したりすることができます。誰でもリポジトリのコミュニティタブでディスカッションを作成したり参加したりできます。 プルリクエスト プルリクエストでは、コミュニティメンバーがウェブサイトから直接プルリクエストを開いたりコメントしたりマージしたり閉じたりすることができます。プルリクエストを開く最も簡単な方法は、「ファイルとバージョン」タブの「共同作業」ボタンを使用することです。これにより、単一のファイルの貢献が非常に簡単に行えます。 裏側では、プルリクエストではフォークやブランチを使用せず、ソースリポジトリに直接保存されるカスタムの「ブランチ」であるrefsを使用しています。このアプローチにより、モデル/データセットの新バージョンごとにフォークを作成する必要がなくなります。 他のGitホストとの違いは何ですか 大まかに言うと、私たちは他のGitホスト(GitHubなど)のPRやIssueのよりシンプルなバージョンを構築することを目指しています: フォークは関与しません:投稿者はソースリポジトリに直接特別なrefブランチにプッシュします IssueとPRの明確な区別はありません:本質的に同じなので、同じリストに表示されます MLに最適化されています(つまり、モデル/データセット/スペースのリポジトリ)で、任意のリポジトリではありません 次は何ですか もちろん、これは始まりに過ぎません。私たちはコミュニティのフィードバックを聞きながら、将来的に新機能を追加し、コミュニティタブを改善していく予定です。フィードバックがあれば、こちらのディスカッションに参加することができます。今日が初めてディスカッションに参加し、プルリクエストを開く最高のタイミングです!…

ハブでの評価の発表
TL;DR : 今日はAutoTrainでパワードされた新しいツール、Evaluation on the Hubを紹介します。このツールを使用すると、コードを1行も書かずにHub上の任意のモデルを任意のデータセットで評価することができます! 全てのモデルを評価しましょう🔥🔥🔥! AIの進歩は驚くべきものであり、一部の人々はAIモデルが特定のタスクにおいて人間よりも優れているかもしれないと真剣に議論しています。しかし、この進歩は均等ではありませんでした。数十年前の機械学習者にとって、現代のハードウェアやアルゴリズムは驚くべきものに見えるかもしれませんし、利用可能なデータと計算能力の量も同様ですが、モデルの評価方法はほぼ同じままでした。 しかし、現代のAIは評価の危機に直面していると言っても過言ではありません。適切な評価には、多くのモデルを多くのデータセットで、複数の指標で測定する必要があります。しかし、これを行うことは不必要に手間がかかります。特に再現性に重点を置く場合、自己報告された結果は、偶発的なバグ、実装の微妙な違い、またはそれ以上の問題によって影響を受けている可能性があります。 私たちは、より良い評価が可能であると信じています。それには、私たちコミュニティがより良いベストプラクティスを確立し、障壁を取り除こうとすることが必要です。過去数か月間、私たちはEvaluation on the Hubに取り組んできました:ボタンをクリックするだけで、任意のモデルを任意のデータセットで任意のメトリックを使用して評価することができます。始めるには、いくつかの主要なデータセットで何百ものモデルを評価し、Hub上のモデルカードに新しい素敵なPull Request機能を使用して、検証済みのパフォーマンスを表示するための多くのPRを公開しました。評価結果は、モデルカードのメタデータに直接エンコードされ、Hub上のすべてのモデルに対してフォーマットが適用されます。DistilBERTのモデルカードをチェックしてみてください! On the Hub Hub上の評価は、非常に興味深いユースケースを提供します。データサイエンティストやエグゼクティブがどのモデルを展開するかを決定する必要がある場合や、新しいデータセットで論文の結果を再現しようとする学者、展開のリスクをよりよく理解したい倫理学者などにとって、これは非常に役立ちます。最初の3つの主要なユースケースシナリオを挙げると、次のようなものがあります: タスクに最適なモデルを見つける 自分のタスクが明確であり、その仕事に適したモデルを見つけたいとします。タスクを代表するデータセットのリーダーボードをチェックできます。素晴らしいですね!もし興味のある新しいモデルが、そのデータセットのリーダーボードにまだ掲載されていない場合は、Hubを離れずに評価を実行することができます。 新しいデータセットでモデルを評価する 新しく作成したデータセットでベースラインを実行したい場合はどうでしょう?Hubにアップロードして、それに対して評価したいモデルを何個でも評価することができます。コードは不要です。さらに、自分のデータセットでこれらのモデルを評価する方法が、他のデータセットで評価された方法とまったく同じであることを確信することができます。 自分のモデルを他の関連する多くのデータセットで評価する また、SQuADでトレーニングされた全く新しい質問応答モデルがあるとしましょう。評価するためのさまざまな質問応答データセットが何百もあります…

Twitterでの感情分析を始める
センチメント分析は、テキストデータをその極性(ポジティブ、ネガティブ、ニュートラルなど)に基づいて自動的に分類するプロセスです。企業は、ツイートのセンチメント分析を活用して、顧客が自社製品やサービスについてどのように話しているかを把握し、ビジネスの意思決定に洞察を得ること、製品の問題や潜在的なPR危機を早期に特定することができます。 このガイドでは、Twitterでのセンチメント分析を始めるために必要なすべてをカバーします。コーダーと非コーダーの両方向けに、ステップバイステップのプロセスを共有します。コーダーの場合、Inference APIを使用してツイートのセンチメント分析を簡単なコード数行でスケールして行う方法を学びます。コーディング方法を知らない場合でも心配ありません!Zapierを使用してセンチメント分析を行う方法もカバーします。Zapierはツイートを収集し、Inference APIで分析し、最終的に結果をGoogle Sheetsに送信するためのノーコードツールです⚡️ 一緒に読んで興味があるセクションにジャンプしてください🌟: センチメント分析とは何ですか? コーディングを使用したTwitterセンチメント分析の方法は? コーディングを使用せずにTwitterセンチメント分析を行う方法は? 準備ができたら、楽しんでください!🤗 センチメント分析とは何ですか? センチメント分析は、機械学習を使用して人々が特定のトピックについてどのように話しているかを自動的に識別する方法です。センチメント分析の最も一般的な用途は、テキストデータの極性(つまり、ツイートや製品レビュー、サポートチケットが何かについてポジティブ、ネガティブ、またはニュートラルに話しているかを自動的に識別すること)の検出です。 例として、@Salesforceをメンションしたいくつかのツイートをチェックして、センチメント分析モデルによってどのようにタグ付けされるかを確認してみましょう: “The more I use @salesforce the more I dislike it. It’s…

文のトランスフォーマーを使用してプレイリスト生成器を構築する
数時間前に、Sentence TransformersとGradioを使用して構築したプレイリスト生成器を公開しました。それに続いて、プロジェクトを効果的な学習体験として活用する方法について考察しました。しかし、実際にプレイリスト生成器をどのように構築したのでしょうか?この投稿では、そのプロジェクトを解説し、埋め込みの生成方法と多段階のGradioデモの構築方法について説明します。 以前のHugging Faceブログの記事でも探求したように、Sentence Transformers(ST)は文の埋め込みを生成するためのツールを提供するライブラリです。使用できる歌詞のデータセットにアクセスできたため、STの意味的検索機能を活用して与えられたテキストプロンプトからプレイリストを生成することにしました。具体的には、プロンプトから埋め込みを作成し、その埋め込みを事前生成された歌詞の埋め込みセット全体で意味的検索に使用し、関連するソングのセットを生成することでした。これはすべて、Hugging Face Spacesでホストされた新しいBlocks APIを使用したGradioアプリに包括されます。 Gradioのやや高度な使用方法について説明しますので、ライブラリに初めて取り組む方は、この投稿のGradio固有の部分に取り組む前に、Blocksの紹介を読むことをお勧めします。また、歌詞のデータセットは公開しませんが、Hugging Face Hubで歌詞の埋め込みを試すことができます。それでは、始めましょう! 🪂 Sentence Transformers:埋め込みと意味的検索 埋め込みはSentence Transformersの鍵です!以前の記事で埋め込みが何であり、どのように生成するかについて学びましたので、この投稿を続ける前にそれをチェックすることをお勧めします。 Sentence Transformersには、事前学習された埋め込みモデルの大規模なコレクションがあります!独自のトレーニングデータを使用してこれらのモデルを微調整するチュートリアルも用意されていますが、多くのユースケース(歌詞のコーパスを対象とした意味的検索など)では、事前学習されたモデルが問題なく機能します。ただし、利用可能な埋め込みモデルが非常に多いため、どれを使用するかをどのように知ることができるのでしょうか? STのドキュメントでは、多くの選択肢が強調されており、評価メトリックといくつかの使用ケースの説明も示されています。MS MARCOモデルはBing検索エンジンのクエリでトレーニングされていますが、他のドメインでも優れたパフォーマンスを発揮するため、このプロジェクトではこれらのいずれかを選択することができると判断しました。プレイリスト生成器に必要なのは、いくつかの意味的な類似性を持つ曲を見つけることであり、特定のパフォーマンス指標に達成することにはあまり興味がないため、sentence-transformers/msmarco-MiniLM-L-6-v3を任意に選びました。 STの各モデルには、設定可能な入力シーケンス長があります(最大値まで)。その後、入力は切り捨てられます。私が選んだモデルは最大シーケンス長が512ワードピースであり、これは歌を埋め込むのに十分ではないことがわかりました。幸いなことに、歌詞をモデルが解析できるように小さなチャンクに分割する簡単な方法があります。それは、詩です!歌を詩に分割し、各詩を埋め込んだ後、検索がはるかに優れた結果を示すことになります。 歌は詩に分割され、それぞれの詩は埋め込まれます。 実際に埋め込みを生成するには、Sentence Transformersモデルの.encode()メソッドを呼び出し、文字列のリストを渡すだけです。その後、埋め込みを好きな方法で保存できます。この場合は、pickle形式で保存することにしました。…

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.