Learn more about Search Results - Page 28

- You may be interested
- 「LLMの評価にLLMを使用する」
- 「Matplotlib チュートリアル:あなたの国...
- 実践におけるFew-shot学習:GPT-Neoと🤗高...
- 「Würstchenをご紹介します:高速かつ効率...
- カナダ政府、オンラインニュース法に関し...
- ファイル管理の効率化:サーバーまたはサ...
- NVIDIAのCEO、ヨーロッパの生成AIエグゼク...
- オープンAI GPTモデルの使用に関するベス...
- あなたのCopy-Paste ChatGPTカスタムの指...
- 「グラフアルゴリズムの探索:連結データ...
- 「FLM-101Bをご紹介します:1010億パラメ...
- 「AIが思考をテキストに変える」
- 「ChatGPTは、ソフトウェアエンジニアリン...
- 注釈の習得:LabelImgとのシームレスなDet...
- 自動チケットトライアジによる顧客サポー...
Word2Vec、GloVe、FastText、解説
コンピューターは我々と同じように単語を理解することができませんコンピューターは数字を扱うことが好きですですから、コンピューターが単語とその意味を理解するのを助けるために、私たちは「埋め込み」と呼ばれるものを使用しますこれらの埋め込みは…
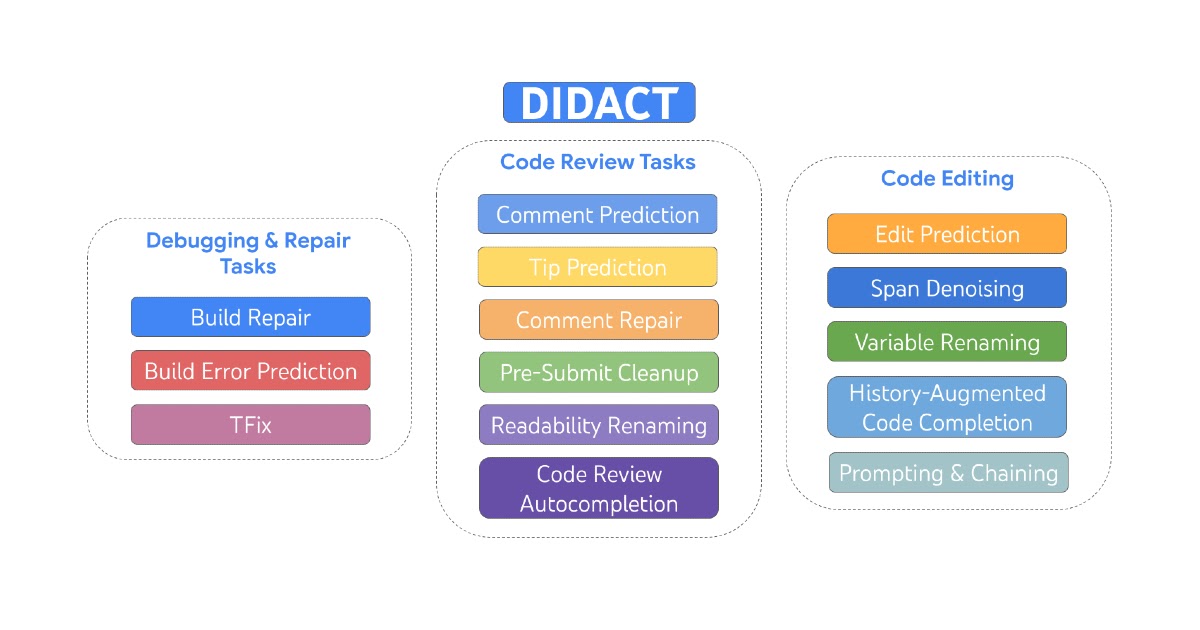
ソフトウェア開発活動のための大規模シーケンスモデル
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。 ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの実行、ビルドエラーの修正、コードレビューのアドレス、編集、リンターの合意、そしてより多くのエラーの修正など、少しずつ改善されていきます。ついには、コードリポジトリにマージするに十分な良い状態になります。ソフトウェアエンジニアリングは孤立したプロセスではなく、人間の開発者、コードレビュワー、バグ報告者、ソフトウェアアーキテクト、コンパイラ、ユニットテスト、リンター、静的解析ツールなどのツールの対話です。 今日、私たちは DIDACT(Dynamic Integrated Developer ACTivity)を説明します。これは、ソフトウェア開発の大規模な機械学習(ML)モデルをトレーニングするための方法論です。 DIDACT の新規性は、完成したコードの磨き上げられた最終状態だけでなく、ソフトウェア開発のプロセス自体をトレーニングデータのソースとして使用する点にあります。開発者が作業を行う際に見るコンテキストと、それに対するアクションを組み合わせて、モデルはソフトウェア開発のダイナミクスについて学び、開発者が時間を費やす方法により合わせることができます。私たちは、Google のソフトウェア開発の計装を活用して、開発者活動データの量と多様性を以前の作品を超えて拡大しました。結果は、プロのソフトウェア開発者にとっての有用性と、一般的なソフトウェア開発スキルを ML モデルに注入する可能性という2つの側面で非常に有望です。 DIDACT は、編集、デバッグ、修復、およびコードレビューを含む開発活動をトレーニングするマルチタスクモデルです。 私たちは DIDACT Comment…

プロンプトエンジニアリングの芸術:ChatGPTのデコード
OpenAIとDeepLearning.AIのコースを受講して、AIとの相互作用の原理と実践をマスターする
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.