Learn more about Search Results ML - Page 289

- You may be interested
- 注目すべきプラグイン:データ分析を自動...
- 「良い説明がすべてです」
- 「ヒュメインが革命的なAIパワードウェア...
- 「生成AIの新たなフロンティア—クラウドか...
- Google AIは、アクティブノイズキャンセリ...
- 「ソフトウェア開発者のための機械学習フ...
- Google AIは、埋め込みモデルのスケーラビ...
- 統計分析入門ガイド | 5つのステップと例
- Amazon AlexaのAI研究者がQUADRoを発表:Q...
- VoAGIニュース、8月2日:ChatGPTコードイ...
- 「データサイエンスのデータ管理原則」
- 「Lab Sessions 実験的なAIの新しいコラボ...
- 「変化の風を操る:2024年の主要なテクノ...
- SAPシステムとのデータ統合のマスタリング...
- 忙しい生活を管理するためにAIツールを利...
プロンプトエンジニアリング:AIを騙して問題を解決する方法
「これは、実践的な大規模言語モデル(LLM)の使用に関するシリーズの第4回目の記事ですここでは、プロンプトエンジニアリング(PE)について説明し、それを使用してLLM対応のアプリケーションを構築する方法について話しますまずは、...」

「NTU SingaporeのこのAI論文は、モーション表現を用いたビデオセグメンテーションのための大規模ベンチマーク、MeVISを紹介しています」
言語にガイドされたビデオセグメンテーションは、自然言語の記述を使用してビデオ内の特定のオブジェクトをセグメント化およびトラッキングすることに焦点を当てた発展途上の領域です。ビデオオブジェクトを参照するための現行のデータセットは通常、目立つオブジェクトに重点を置き、多くの静的属性を持つ言語表現に依存しています。これらの属性により、対象のオブジェクトを単一のフレームで特定することができます。しかし、これらのデータセットは、言語にガイドされたビデオオブジェクトセグメンテーションにおける動きの重要性を見落としています。 https://arxiv.org/abs/2308.08544 研究者は、私たちの調査を支援するために、Motion Expression Video Segmentation(MeViS)と呼ばれる新しい大規模データセットであるMeVISを紹介しました。 MeViSデータセットは2,006のビデオ、8,171のオブジェクト、および28,570のモーション表現で構成されています。上記の画像は、MeViSの表現を表示しており、これらの表現は主にモーションの属性に焦点を当てており、単一のフレームだけで対象のオブジェクトを特定することはできません。たとえば、最初の例では似たような外観を持つ3羽のオウムが特徴であり、対象のオブジェクトは「飛び去る鳥」と特定されます。このオブジェクトは、ビデオ全体のモーションをキャプチャすることでのみ認識できます。 MeVISデータセットがビデオの時間的なモーションに重点を置くようにするために、いくつかの手順があります。 まず、静的属性だけで説明できる孤立したオブジェクトを持つビデオを除外し、モーションと共存する複数のオブジェクトを含むビデオコンテンツを注意深く選択します。 次に、ターゲットオブジェクトをモーションの単語のみで曖昧さなく説明できる場合、カテゴリ名やオブジェクトの色などの静的な手がかりを含まない言語表現を優先します。 MeViSデータセットの提案に加えて、研究者はこのデータセットがもたらす課題に対処するためのベースラインアプローチであるLanguage-guided Motion Perception and Matching(LMPM)を提案しています。彼らのアプローチでは、言語によるクエリの生成を行い、ビデオ内の潜在的な対象オブジェクトを識別します。これらのオブジェクトはオブジェクト埋め込みを使用して表現され、オブジェクトの特徴マップと比較してより堅牢で計算効率の良いものです。研究者はこれらのオブジェクト埋め込みに対してMotion Perceptionを適用し、ビデオのモーションダイナミクスの時間的な文脈を捉え、ビデオ内の瞬間的なモーションと持続的なモーションの両方を把握することができます。 https://arxiv.org/abs/2308.08544 上記の画像はLMLPのアーキテクチャを表示しています。彼らはTransformerデコーダを使用して、モーションに影響を受けた組み合わせられたオブジェクト埋め込みから言語を解釈し、オブジェクトの移動を予測するのに役立ちます。それから、言語特徴を投影されたオブジェクトの動きと比較して、表現で言及されるターゲットオブジェクトを見つけます。この革新的な方法は、言語理解とモーション評価を統合して、複雑なデータセットの課題を効果的に処理します。 この研究は、より高度な言語にガイドされたビデオセグメンテーションアルゴリズムの開発の基盤を提供しました。さらに、以下のようなより困難な方向に向けた道を開拓しました。 視覚的および言語的モダリティにおけるより良いモーション理解とモデリングのための新しい技術の探索。 冗長な検出されたオブジェクトの数を減らすより効率的なモデルの作成。 言語と視覚信号の相補的な情報を活用するための効果的なクロスモーダル融合手法の設計。 複数のオブジェクトと表現がある複雑なシーンを処理できる高度なモデルの開発。 これらの課題に取り組むには、言語によるビデオセグメンテーションの現在の最先端を推進するための研究が必要です。
「生成AIの組織化:データサイエンスチームから得た5つの教訓」
「経営陣が曖昧な約束をした後、新しいGen AIの機能が組織全体に組み込まれることを利害関係者に約束した後、あなたのタイガーチームはMVPを作成するためにスプリントしました」

「2023年の人工知能(AI)と機械学習に関連するサブレディットコミュニティ15選」
人工知能(AI)と機械学習の世界では、最新のトレンド、ブレイクスルー、議論について最新情報を得ることが重要です。インターネットの表紙であるRedditは、専門家や愛好家のための中心地として機能しています。以下は、2023年に追跡するためのトップAIおよび機械学習関連のサブレディットの厳選リストです。 r/MachineLearning このサブレディットは機械学習に焦点を当てており、定期的に技術的で興味深い投稿や議論が行われています。このサブレディットにはいくつかの基本的な行動ルールがあります。250万人以上のメンバーを持つこのグループは、ML愛好家にとって参加必須のグループです。 r/artificial r/artificialは、人工知能(AI)に関連するすべての問題に特化した最大のサブレディットです。16.7万人以上のメンバーがおり、最新のニュースや実践におけるAIの例、AIに取り組んでいる人々の議論や質問などが見つかります。AIは多岐にわたる分野であり、多くのサブフィールドも存在します。これらの多くもそれぞれ専用のサブレディットがあります。r/artificialはこれらすべてのことについてです。これは、どんな形でもAIについての知識と尊重に基づくディスカッションをするためのプラットフォームです。 r/ArtificialInteligence r/ArtificialInteligenceは、コンテンツのフレアを選択する必要がない最もトレンディングなAIのサブレディットの一つです。このサブレディットには8.8万人以上のメンバーがいます。このサブレディットに参加することで、トレンディングなAIのアップデートについて最新情報を得ることができます。 r/Machinelearningnews r/machinelearningnewsは、AIの応用に関する興味深いニュースや記事を共有する機械学習愛好家/研究者/ジャーナリスト/ライターのコミュニティです。スパムを防ぐために、日常的に投稿され、厳しくモデレートされていますので、ML/AI/CV/NLP分野の最新情報を見逃すことはありません。 r/Automate r/Automateは、自動化に焦点を当てた議論や投稿に参加している7.5万人以上のメンバーを擁しています。自動化、付加的な製造、ロボット、AI、そして人間の仕事を不要にするために開発された他のすべての技術に関する議論がr/Automateサブレディットで見つかります。 r/singularity このサブレディットは、人工知能が人間の知能を超える優れた知能の度合いに発展し、文明を根本的に変える仮説的な時期の熟慮された研究に捧げられています。16.1万人以上のメンバーを持つこのサブレディットには、優れた品質と関連性のある投稿があります。これは技術的シンギュラリティおよびそれに関連するテーマ、人工知能(AI)、人間の拡張などのすべての側面を包括しています。 r/agi このサブレディットは、約1.25万人のメンバーを持つ人工一般知能に焦点を当てています。人工一般知能(AGI)を持つ機械は、人間が行うことのできるすべての知的作業を実行できるものです。投稿は定期的で情報があり、クリエイティブな議論が行われています。 r/compsci 計算機科学者が魅了される情報を共有し議論することに興味のある人は、r/compsciサブレディットを訪れるべきです。これにはAIに関する投稿も多く含まれています。メンバーとしてのルールはいくつかあります。このサブレディットには210万人以上のメンバーがいます。 r/AIethics 倫理はAIにおいて基本的な要素です。r/AIethicsには、さまざまなAIツールを倫理的に使用および作成する方法に関する最新情報があります。ルールはシンプルです。3.2千人以上のメンバーがいます。このサブレディットでは、人工知能エージェントがどのように振る舞うべきか、私たちはそれらをどのように扱うべきかについての議論がされています。 r/cogsci 認知科学は広範な分野ですが、このサブレディットは科学的な観点から心の研究に何らかの関連性がある投稿を特集しており、最新のAIも取り上げています。これは哲学、心理学、人工知能、神経科学、言語学、人類学を包括した学際的な心と知性の研究を特集しています。ユーザーが守るべき幅広い行動ガイドラインがあり、10.7万人以上のメンバーがいます。 r/computervision コンピュータビジョンは、生の写真、ビデオ、センサーデータから有用な情報を抽出するアルゴリズムの作成に重点を置いたAI科学の分野です。このサブレディットには優れたコンピュータビジョンと人工知能のコンテンツがあります。約6.8万人のメンバーがいます。コンピュータサイエンス、機械学習、ロボティクス、数学などの分野の専門知識を持つこのコミュニティは、この学際的なトピックを開発および利用している学者やエンジニアの拠点です。 r/datascience…

「Googleは、Raspberry Pi向けにMediaPipeを導入し、デバイス内の機械学習のための使いやすいPython SDKを提供します」
組み込みシステムでの機械学習(ML)ツールへの需要が急速に増加するに伴い、研究者たちはRaspberry Piシングルボードコンピュータで作業する開発者を支援する革新的なソリューションを提案しました。新しいフレームワークであるMediaPipe for Raspberry Piは、さまざまなMLタスクを容易にするために特別に設計されたPythonベースのソフトウェア開発キット(SDK)を提供します。この開発は、オンデバイスMLの領域での重要な進歩であり、簡素化された効率的なツールの必要性に対応しています。 オンデバイス機械学習の登場により、開発者は資源の制約や複雑さに直面しています。ホビーユーザーやプロフェッショナルの間で人気のあるRaspberry Piは、プロジェクトで機械学習の力をシームレスに活用するための包括的なSDKが不足していました。アクセス可能なツールの不足は、使いやすいソリューションの必要性を促しました。 MediaPipe for Raspberry Piの導入前、開発者はしばしば一般的な機械学習フレームワークをRaspberry Piデバイスの能力に合わせて適応させることに苦労しました。このプロセスはしばしば複雑で、MLアルゴリズムとハードウェアの制約についての深い理解を求められました。この課題は、Raspberry Piエコシステムに明示的に対応するSDKの必要性によってさらに深刻化しました。 さまざまな機関の研究者たちは、これらの問題に対処する画期的なフレームワークを発表しました。MediaPipe for Raspberry Pi SDKは、オンデバイスML開発を合理化するための共同の取り組みから生まれました。このフレームワークは、オーディオ分類、テキスト分類、ジェスチャー認識など、さまざまな機械学習タスクを容易にするPythonベースのインターフェースを提供しています。その導入は、あらゆるバックグラウンドの開発者がRaspberry Piプロジェクトに機械学習をシームレスに統合するための重要な飛躍を意味しています。 MediaPipe for Raspberry Piは、組み込みシステム上での機械学習の実装の複雑さを処理する事前構築されたコンポーネントを提供することで、開発プロセスを簡素化します。SDKはOpenCVとNumPyとの統合によってその機能をさらに向上させます。フレームワークは、オーディオ分類、顔のランドマーク、画像分類など、さまざまなアプリケーションをカバーするPythonのサンプルを提供することで、プロジェクトを素早く始めることができます。さらに、開発者はRaspberry Piデバイス上での最適なパフォーマンスを確保するために、ローカルに保存されたMLモデルを使用することが推奨されています。…

「Amazon SageMaker プロファイラーのプレビューを発表します:モデルトレーニングのワークロードの詳細なハードウェアパフォーマンスデータを追跡および可視化します」
本日は、Amazon SageMaker Profilerのプレビューを発表できることを喜んでお知らせしますこれはAmazon SageMakerの機能の一部であり、SageMaker上でディープラーニングモデルのトレーニング中にプロビジョニングされるAWSのコンピューティングリソースの詳細なビューを提供しますSageMaker Profilerを使用すると、CPUとGPUのすべてのアクティビティをトラックできますCPUとGPUの利用率、GPU上でのカーネルの実行、CPU上でのカーネルの起動、同期操作、GPU間のメモリ操作、カーネルの起動と対応する実行とのレイテンシ、CPUとGPU間のデータ転送などが含まれますこの記事では、SageMaker Profilerの機能について詳しく説明します

「言語モデルにアルゴリズム的な推論を教える」
Posted by Hattie Zhou, MILAの大学院生、Hanie Sedghi, Googleの研究科学者 GPT-3やPaLMなどの大規模言語モデル(LLM)は、モデルとトレーニングデータのサイズを拡大することで、近年驚異的な進歩を遂げています。それにもかかわらず、LLMが象徴的に推論できるか(すなわち、論理的なルールに基づいて記号を操作できるか)という長年の議論がありました。たとえば、LLMは、数字が小さい場合には簡単な算術演算を実行できますが、数字が大きい場合は苦労します。これは、LLMがこれらの算術演算を実行するために必要な基本的なルールを学習していないことを示唆しています。 ニューラルネットワークはパターンマッチング能力に優れていますが、データ中の偶発的な統計的パターンに過学習しやすいです。これは、トレーニングデータが大きく多様であり、評価が分布内である場合には良いパフォーマンスに影響しません。ただし、加算などのルールベースの推論を必要とするタスクでは、LLMは分布外の一般化に苦労し、トレーニングデータの偶発的な相関は真のルールベースの解決策よりもはるかに容易に利用されることがしばしばあります。その結果、さまざまな自然言語処理タスクでの重要な進展にもかかわらず、加算などの簡単な算術タスクのパフォーマンスは依然として課題のままです。MATHデータセットでのGPT-4のささやかな改善にもかかわらず、エラーは主に算術と計算のミスによるものです。したがって、重要な問題は、LLMがアルゴリズム的な推論が可能かどうかということです。アルゴリズム的な推論は、アルゴリズムを定義する一連の抽象的なルールを適用してタスクを解決することを含みます。 「コンテキスト学習を通じたアルゴリズム的な推論の教育」では、コンテキスト学習を活用してLLMにアルゴリズム的な推論能力を可能にするアプローチについて説明しています。コンテキスト学習とは、モデルがモデルのコンテキスト内でそれに関するいくつかの例を見た後にタスクを実行できる能力を指します。タスクはプロンプトを使用してモデルに指定され、重みの更新は必要ありません。また、より困難な算術問題においてプロンプトで見られるものよりも強力な一般化を実現するための革新的なアルゴリズム的プロンプティング技術を提案しています。最後に、適切なプロンプト戦略を選択することで、モデルが分布外の例でアルゴリズムを信頼性を持って実行できることを示しています。 アルゴリズム的プロンプトを提供することで、コンテキスト学習を通じてモデルに算術のルールを教えることができます。この例では、LLM(単語予測)は、簡単な加算の質問(例:267 + 197)をプロンプトとして入力すると正しい答えを出力しますが、桁数の長い類似の加算の質問に対しては失敗します。ただし、より困難な質問に加算のアルゴリズム的プロンプトを追加すると(単語予測の下に表示される青いボックスと白い+)、モデルは正しく答えることができます。さらに、モデルは一連の加算計算を合成することによって乗算アルゴリズム( X )をシミュレートすることができます。 アルゴリズムをスキルとして教える モデルにアルゴリズムをスキルとして教えるために、アルゴリズムプロンプトを開発します。これは、他の根拠に基づいたアプローチ(スクラッチパッドや思考の連鎖など)を基に構築されます。アルゴリズムプロンプトは、LLMからアルゴリズム的な推論能力を抽出し、他のプロンプトアプローチと比較して2つの注目すべき特徴があります。 1)アルゴリズミックな解決策に必要な手順を出力してタスクを解決し、2)LLMによる誤解釈の余地がないように、各アルゴリズミックな手順を十分な詳細で説明します。 アルゴリズム的なプロンプトの直感を得るために、2つの数字の加算のタスクを考えてみましょう。スクラッチパッドスタイルのプロンプトでは、右から左に各桁を処理し、各ステップでキャリー値(現在の桁が9より大きい場合は次の桁に1を追加します)を追跡します。ただし、キャリーのルールはキャリー値の数例を見た後ではあいまいです。キャリーのルールを明示するために明示的な方程式を含めると、モデルは関連する詳細に焦点を当て、プロンプトをより正確に解釈することができることがわかります。この洞察を活用して、2つの数字の加算のためのアルゴリズム的なプロンプトを開発しました。計算の各ステップに対して明示的な方程式を提供し、曖昧さのない形式でさまざまなインデックス操作を説明します。 さまざまな加算のプロンプト戦略のイラスト。 答えの桁数が最大5桁までの加算のプロンプト例を3つだけ使用して、19桁までの加算のパフォーマンスを評価します。正確性は、答えの長さに均等にサンプリングされた合計2,000の例において測定されます。以下に示すように、アルゴリズムのプロンプトの使用により、プロンプトで見られる以上に長い質問に対しても高い正確性が維持されており、モデルが入力に関係ないアルゴリズムを実行することによってタスクを解決していることが示されています。 異なるプロンプトのメソッドによる加算問題のテスト正確性の長さの増加。 アルゴリズム的なスキルを道具として活用する モデルがより一般的な推論プロセスにおいてアルゴリズミックな推論を活用できるかどうかを評価するために、学校の数学のワードプロブレム(GSM8k)を使用してパフォーマンスを評価します。具体的には、GSM8kからの加算計算をアルゴリズミックな解決策で置き換える試みを行います。…
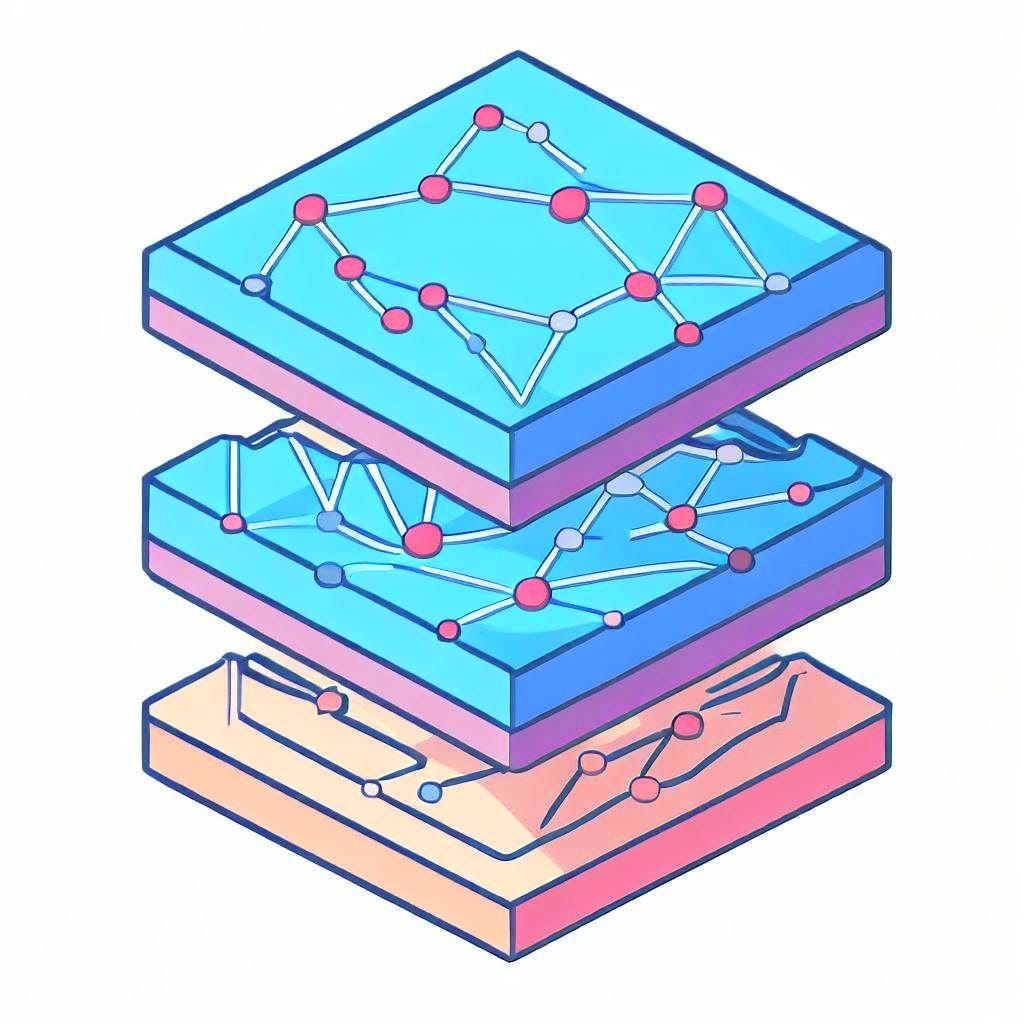
「エンティティ解決とグラフニューラルネットワークを用いた詐欺検知」
オンライン詐欺は、金融、電子商取引、およびその他の関連産業にとってますます深刻な問題ですこの脅威に対応するため、組織は機械学習と…に基づく詐欺検知メカニズムを使用します
開発者の皆さんへ:ダイアグラムはそんなに複雑である必要はありません
「図表は有用な情報を含んでいるだけでなく、読みやすいものでなければなりませんそして、作成するのも簡単で、楽しいことが望ましいです!」

バイオメディカルインサイトのための生成AI
OpenBIOMLとBIO GPTを利用したGenerative AIを探求し、Large Language Models (LLMs)を使用して疾患の理解と治療に新たなアプローチを取ることを目指しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.