Learn more about Search Results arXiv - Page 27

- You may be interested
- バード:新しいChatGPTの競争相手
- 磁気センサーがGPUクリプトジャッキング攻...
- Pythonを使用した探索的データ分析(EDA)...
- 重要なデータサイエンスのスキルを習得す...
- 「Quip Python APIs を使用して Quip スプ...
- 「PolarsによるEDA:集計と分析関数のステ...
- 「目を閉じると見える光の『地図』が改善...
- 激しい天候に対するスマートな緊急対応
- 「Intuitivoは、AWS InferentiaとPyTorch...
- 人工ニューラルネットワークのパフォーマ...
- デヴオプスにおけるジェネレーティブAI:...
- 「スピークAI転写ソフトウェアのレビュー...
- AIがフィンテックを向上させる方法:追跡...
- 「AIオートメーションエージェンシーのリ...
- フィーチャーストアアーキテクチャとその...

単一モダリティとの友情は終わりました – 今やマルチモダリティが私の親友です:CoDiは、合成可能な拡散による任意から任意への生成を実現できるAIモデルです
ジェネレーティブAIは、今ではほぼ毎日聞く用語です。私はジェネレーティブAIに関する論文をどれだけ読んでまとめたか覚えていません。彼らは印象的で、彼らがすることは非現実的で魔法のようであり、多くのアプリケーションで使用できます。テキストプロンプトを使用するだけで、画像、動画、音声などを生成できます。 近年のジェネレーティブAIモデルの大幅な進歩により、以前は不可能と考えられていたユースケースが可能になりました。テキストから画像へのモデルで始まり、信じられないほど素晴らしい結果が得られたことがわかった後、複数のモダリティを扱うことができるAIモデルの需要が高まりました。 最近は、任意の入力の組み合わせ(例:テキスト+音声)を取り、様々な出力の組み合わせ(例:ビデオ+音声)を生成できるモデルの需要が急増しています。これを対処するためにいくつかのモデルが提案されていますが、これらのモデルは、共存し相互作用する複数のモダリティを含む現実世界のアプリケーションに関して制限があります。 モダリティ固有の生成モデルを多段的なプロセスでつなげることは可能ですが、各ステップの生成力は本質的に限定されるため、手間がかかり、遅いアプローチとなります。また、独立に生成された単一モダルストリームは、組み合わせるときに一貫性や整合性が欠けることがあり、後処理の同期が困難になる場合があります。 任意の入力モダリティの混合を処理し、任意の出力の組み合わせを柔軟に生成するためのモデルをトレーニングするには、膨大な計算およびデータ要件が必要です。可能な入力-出力の組み合わせの数は指数関数的に増加し、多数のモダリティグループに対して整列したトレーニングデータはまれまたは存在しないためです。 ここで、この課題に取り組むために提案されたCoDiというモデルを紹介しましょう。 CoDiは、任意のモダリティの任意の組み合わせを同時に処理および生成することを可能にする新しいニューラルアーキテクチャです。 CoDiの概要。出典:https://arxiv.org/pdf/2305.11846.pdf CoDi は、入力条件付けおよび生成拡散ステップの両方で複数のモダリティを整列させることを提案しています。さらに、対照的な学習のための「ブリッジングアライメント」戦略を導入し、線形数のトレーニング目標で指数関数的な入力-出力の組み合わせを効率的にモデル化できるようにしています。 CoDi の主要なイノベーションは、潜在的な拡散モデル(LDM)、多モダル条件付けメカニズム、およびクロスアテンションモジュールの組み合わせを利用して、任意の-to-任意の生成を処理することができる能力にあります。各モダリティ用に別々のLDMをトレーニングし、入力モダリティを共有特徴空間に射影することで、CoDi は、このような設定の直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを生成できます。 CoDiの開発には、包括的なモデル設計と多様なデータリソースでのトレーニングが必要です。最初に、テキスト、画像、動画、音声などの各モダリティに対して潜在的な拡散モデル(LDM)をトレーニングします。これらのモデルは独立して並行してトレーニングでき、モダリティに固有のトレーニングデータを使用して、卓越した単一モダリティ生成品質を確保します。音声+言語のプロンプトを使用して画像を生成する場合の条件付きクロスモダリティ生成では、入力モダリティを共有の特徴空間に射影し、出力LDMは入力特徴の組み合わせに注意を払います。この多モダル条件付けメカニズムにより、拡散モデルは直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを処理できるようになります。 CoDiモデルの概要。出典:https://arxiv.org/pdf/2305.11846.pdf トレーニングの第2ステージでは、CoDiは、任意の出力モダリティの任意の組み合わせを同時に生成する多対多の生成戦略を処理します。これは、各ディフューザーにクロスアテンションモジュールを追加し、環境エンコーダーを追加して、異なるLDMの潜在変数を共有潜在空間に投影することによって実現されます。このシームレスな生成能力により、CoDiは、すべての可能な生成組み合わせでトレーニングすることなく、任意のモダリティのグループを生成できるため、トレーニング目標の数を指数関数から線形関数に減らすことができます。 (※以下、原文のHTMLコードを保持します) In the second stage of training, CoDi…
AIがトランスコミュニティに与える悪影響を明らかにする
AIがトランスジェンダーに失敗している方法ジェンダー認識ソフトウェアの危険性、不適切な医療モデル、トランスフォビックなコンテンツの増幅
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

SRGANs:低解像度と高解像度画像のギャップを埋める
イントロダクション あなたが古い家族の写真アルバムをほこりっぽい屋根裏部屋で見つけるシナリオを想像してください。あなたはすぐにほこりを取り、最も興奮してページをめくるでしょう。そして、多くの年月前の写真を見つけました。しかし、それでも、あなたは幸せではないです。なぜなら、写真が薄く、ぼやけているからです。写真の顔や細部を見つけるために目をこらします。これは昔のシナリオです。現代の新しいテクノロジーのおかげで、私たちはスーパーレゾリューション・ジェネレーティブ・アドバーサリ・ネットワーク(SRGAN)を使用して、低解像度の画像を高解像度の画像に変換することができます。この記事では、私たちはSRGANについて最も学び、QRコードの強化のために実装します。 出典: Vecteezy 学習目標 この記事では、以下のことを学びます: スーパーレゾリューションと通常のズームとの違いについて スーパーレゾリューションのアプローチとそのタイプについて SRGAN、その損失関数、アーキテクチャ、およびそのアプリケーションについて深く掘り下げる SRGANを使用したQRエンハンスメントの実装とその詳細な説明 この記事は、データサイエンスブログマラソンの一環として公開されました。 スーパーレゾリューションとは何ですか? 多くの犯罪捜査映画では、証拠を求めて探偵がCCTV映像をチェックする典型的なシナリオがよくあります。そして、ぼやけた小さな画像を見つけて、ズームして強化してはっきりした画像を得るシーンがあります。それは可能ですか?はい、スーパーレゾリューションの助けを借りて、それはできます。スーパーレゾリューション技術は、CCTVカメラによってキャプチャされたぼやけた画像を強化し、より詳細な視覚効果を提供することができます。 ………………………………………………………………………………………………………………………………………………………….. ………………………………………………………………………………………………………………………………………………………….. 画像の拡大と強化のプロセスをスーパーレゾリューションと呼びます。それは、対応する低解像度の入力から画像またはビデオの高解像度バージョンを生成することを目的としています。それによって、欠落している詳細を回復し、鮮明さを向上させ、視覚的品質を向上させることができます。強化せずに画像をズームインするだけでは、以下の画像のようにぼやけた画像が得られます。強化はスーパーレゾリューションによって実現されます。写真、監視システム、医療画像、衛星画像など、さまざまな領域で多くの応用があります。 ……….. スーパーレゾリューションの従来のアプローチ 従来のアプローチでは、欠落しているピクセル値を推定し、画像の解像度を向上させることに重点を置いています。2つのアプローチがあります。補間ベースの方法と正則化ベースの方法です。 補間ベースの方法 スーパーレゾリューションの初期の日々には、補間ベースの方法に重点が置かれ、欠落しているピクセル値を推定し、その後画像を拡大します。隣接するピクセル値が類似しているという仮定を使用して、これらの値を使用して欠落している値を推定します。最も一般的に使用される補間方法には、バイキュービック、バイリニア、および最近傍補間があります。しかし、その結果は満足できないものでした。これにより、ぼやけた画像が生じました。これらの方法は、基本的な解像度タスクや計算リソースに制限がある状況に適しているため、効率的に計算できます。 正則化ベースの手法 一方で、正則化ベースの手法は、画像再構成プロセスに追加の制約や先行条件を導入することで、超解像度の結果を改善することを目的としています。これらの技術は、画像の統計的特徴を利用して、再構築された画像の精度を向上させながら、細部を保存します。これにより、再構築プロセスにより多くの制御が可能になり、画像の鮮明度と細部が向上します。しかし、複雑な画像コンテンツを扱う場合には、過度の平滑化を引き起こすため、いくつかの制限があります。 これらの従来のアプローチにはいくつかの制限があるにもかかわらず、超解像度の強力な手法の出現への道を示しました。…
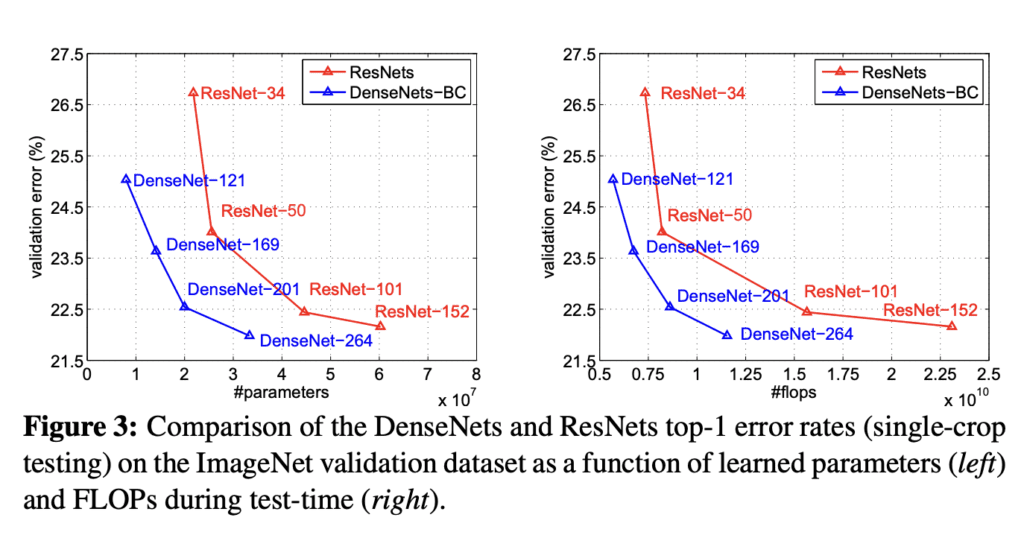
FLOPsとMACsを使用して、Deep Learningモデルの計算効率を計算する
この記事では、その定義、違い、およびPythonパッケージを使用してFLOPsとMACsを計算する方法について学びます

あちこち行って… RAPIDSの物語
このブログ投稿では、RapidsAI cuDFを使用して、十分なデータを取得するための課題と、バイアスがかかったデータセットによって課せられる制限について探求します
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.