Learn more about Search Results Tome - Page 27

- You may be interested
- MITによる新しい機械学習の研究は、大規模...
- 「オムニバースへ:Blender 4.0 アルファ...
- 物理情報を組み込んだDeepONetによるオペ...
- 「最も難しいPandas:ピボットテーブル、...
- 「VoAGI 30 for 30 Giveaway with O’Reill...
- 「ハッカソンが量子の可能性を垣間見せる」
- アマゾンは、革新的なAIスタートアップのA...
- 「MITのリキッドニューラルネットワークが...
- 深さ優先探索(DFS)アルゴリズム:グラフ...
- 「自動通話要約を通じて、エージェントの...
- 実践的なプロンプトエンジニアリング
- ユーザーに扱える以上を提供する
- 「医療機械学習におけるバイアスのある臨...
- (「AI ga hontōni watashitachi o zenmets...
- ディープマインドのこの機械学習研究は、...

「2023年にデータストラテジストになる方法」
イントロダクション データが持つ現実世界の課題に魅了されていますか?情報の力で隠れた洞察を明らかにし、ビジネスを変革することにワクワクしていますか?もしそうなら、データストラテジストになることが正しいキャリアパスです。大量のデータセットをゲームチェンジングな戦略に変える能力を持った組織のヒーローになることを想像してください。あなたは秘密を解き明かし、ビジネスを前例のない成功に導くための頼りにされる人物になります。この記事では、どのようにデータストラテジストになるかについて説明します! データストラテジストとは何ですか? データストラテジストは、データに基づく組織の意思決定を形成する重要な役割を果たす熟練した専門家です。彼らはステークホルダーとの協力、要件とデータソースに関する貴重な洞察の獲得、革新的なデータ駆動型ソリューションの作成に優れています。データの重要性がますます高まるにつれて、企業は効率的かつ効果的なデータ管理のためにデータストラテジストの欠かせない価値を認識しています。彼らの専門知識により、ビジネスは自信を持ってデータの海を航海し、成長と成功の未開拓の可能性を引き出すことができます。 なぜデータストラテジストが必要ですか? データに基づく意思決定を支援する。 データアセットから最大の価値を提供できる機会を特定する。 組織のビジョンと目標に到達するための戦略的計画を支援する。 非効率を最小限に抑えるためにデータシステムとテクノロジーを統合する。 データストラテジストは、品質、データのセキュリティ、拡張性などのデータに関連する課題に関心を持っています。 職務内容 データストラテジストの職務内容は以下の通りです。 デジタルセクターにおけるマーケティングデータ活用のユースケースを定義する。 トランザクション、マーケティング、商業データなどの消費者およびプロフェッショナルのエコシステムとデータモデルを理解する。 データアーキテクチャの設計に関わり、その管理を監督する。 プロジェクトのタイムラインを管理する。 部門間の相互作用と行動を維持する。 データ収集、分析、実践の普及により、機関のデータ容量を洗練させる。 効果的なメトリックの設計に貢献する。 データの可視化と分析に取り組む。 TableauやPower BI、SQL Serverなどのダッシュボードツールやビジネスインテリジェンスプラットフォームを使用する。 戦略的な意思決定を支援する。…
「データの中で最も異常なセグメントを特定する」
「アナリストはしばしば、「興味深い」と思われるセグメントを見つけるというタスクがありますつまり、最大の潜在的な影響を得るために私たちの努力を集中させることができるセグメントです例えば、次のようなことを判断することは興味深いかもしれません...」
アップリフトモデリング—クレジットカード更新キャンペーンの最適化ガイド データサイエンティストのための
新進のデータサイエンティストとして、私の学術的なバックグラウンドは正確さを成功したプロジェクトの兆候として尊重するように教えてくれました一方、産業界は短期間でお金を生み出し、節約することに関心を持っています...
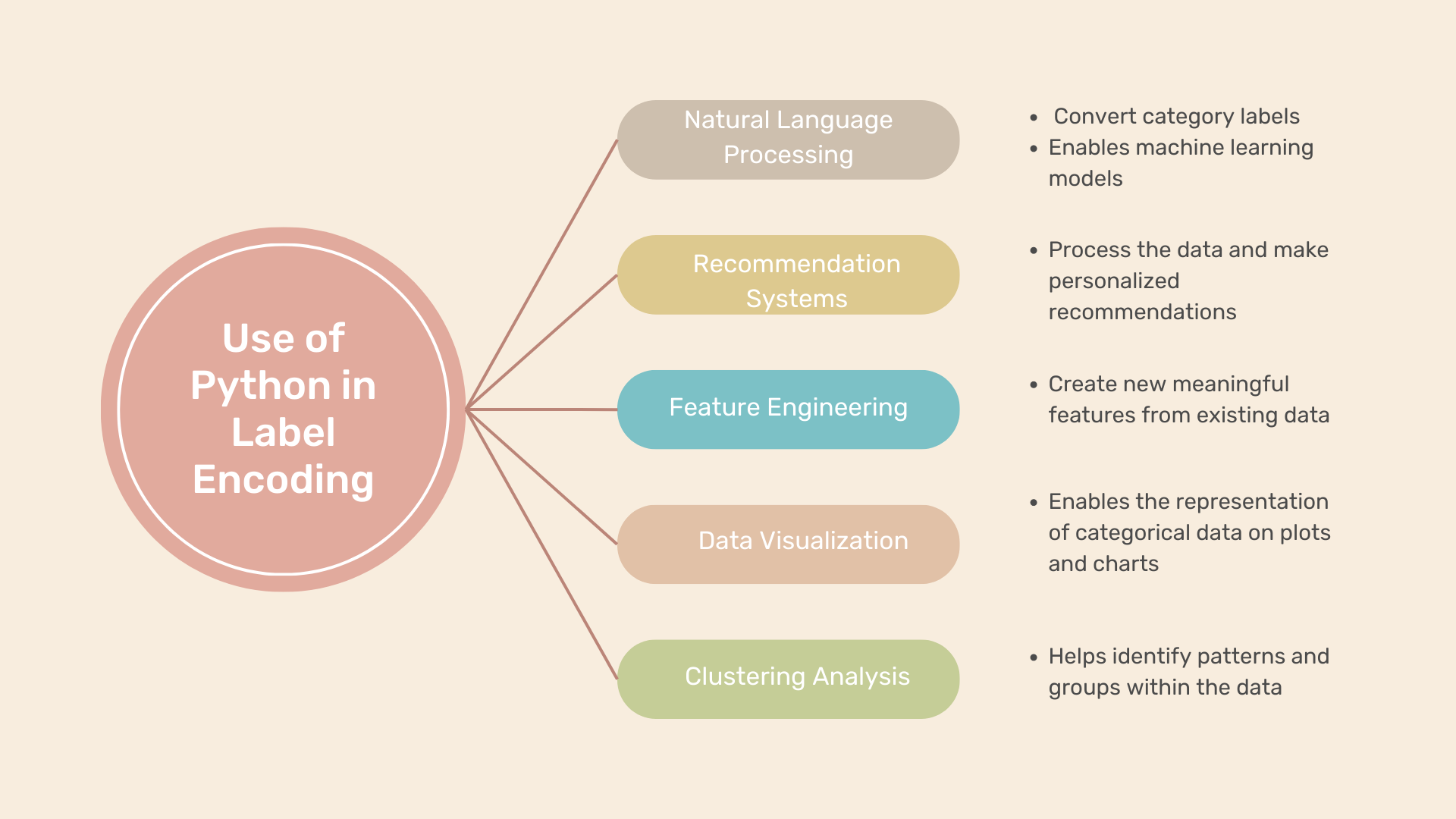
「Pythonでのラベルエンコーディングの実行方法」
データ分析や機械学習では、しばしばカテゴリカル変数を含むデータセットに遭遇します。これらの変数は数値ではなく、質的属性を表します。しかし、多くの機械学習アルゴリズムでは数値の入力が必要です。ここでラベルエンコーディングが重要な役割を果たします。カテゴリデータを数値のラベルに変換することで、ラベルエンコーディングはさまざまなアルゴリズムで使用することができます。この投稿では、ラベルエンコーディングの説明と、Pythonでの応用例、そして人気のあるsci-kit-learnモジュールを使用したラベルエンコーディングの適用方法の例を示します。 Pythonにおけるラベルエンコーディングとは何ですか? Pythonでは、カテゴリカル変数をラベルエンコーディング技術を使用して数値のラベルに変換することができます。これにより、機械学習アルゴリズムがデータを効果的に解釈して分析することができます。ラベルエンコーディングの関数の使い方を学ぶために、いくつかの例を見てみましょう。 Pythonでのラベルエンコーディングの例 例1:顧客セグメンテーション 顧客セグメンテーションのデータセットを想定してみましょう。このデータセットには、顧客の人口統計的特徴に関するデータが含まれています。「性別」、「年齢層」、「婚姻状況」などの変数があります。これらの変数内の各カテゴリに複数のラベルを付けることで、ラベルエンコーディングを実行することができます。例えば: カテゴリカル変数にラベルエンコーディングを適用することで、顧客セグメンテーション分析に適した数値形式でデータを表現することができます。 例2:製品カテゴリ 製品カテゴリのデータセットを考えてみましょう。このデータセットには、「製品名」や「カテゴリ」などの変数が含まれています。ラベルエンコーディングを行うために、各カテゴリに数値のラベルを割り当てます: ラベルエンコーディングにより、製品カテゴリを数値のラベルで表現することができます。これにより、さらなる分析やモデリングのタスクが可能になります。 例3:感情分析 感情分析のデータセットでは、「感情」という変数があります。この変数は、テキストドキュメントに関連付けられた感情(例:positive、negative、neutral)を表します。この変数にラベルエンコーディングを適用することで、各感情カテゴリに数値のラベルを割り当てることができます: ラベルエンコーディングにより、感情カテゴリを数値のラベルに変換することができます。これにより、感情分析のタスクをより簡単に実行することができます。 これらの例は、ラベルエンコーディングが異なるデータセットと変数に適用され、カテゴリ情報を数値のラベルに変換することで、さまざまな分析および機械学習のタスクを可能にすることを示しています。 Pythonでのラベルエンコーディングの使用例 ラベルエンコーディングは、カテゴリデータを扱う際にさまざまなシナリオで使用することができます。以下にいくつかの例を示します: 自然言語処理(NLP): ラベルエンコーディングは、テキストの分類や感情分析などのNLPアプリケーションで、positive、negative、neutralなどのカテゴリラベルを数値表現に変換することができます。これにより、機械学習モデルがテキストデータを正しく理解して分析することができます。 レコメンデーションシステム: レコメンデーションシステムでは、ユーザの好みやアイテムのカテゴリを表すためにカテゴリカル変数を使用することがよくあります。これらの変数にラベルエンコーディングを行うことで、レコメンデーションアルゴリズムはデータを処理し、ユーザの好みに基づいて個別の推薦を行うことができます。 特徴エンジニアリング: ラベルエンコーディングは特徴エンジニアリングの重要なステップです。ここでは既存のデータから新しい意味のある特徴を作成します。カテゴリカル変数を数値のラベルにエンコードすることで、異なるカテゴリ間の関係を捉えた新しい特徴を作成し、モデルの予測力を向上させることができます。 データの可視化: ラベルエンコーディングはデータの可視化のためにも使用することができます。カテゴリカル変数をエンコードすることで、数値入力が必要なプロットやチャート上でカテゴリデータを表現することができます。カテゴリ変数をエンコードすることで、データに対する洞察を提供する意味のある可視化を作成することができます。…

DatabricksがMosaicMLとその他の最近のAIの買収を行いました
経済は非常にダイナミックであるにもかかわらず、AIはまだ熱い市場です過去数週間にいくつかの大規模な買収や合併があり、それぞれが近い将来に市場を再定義する可能性がありますでは、いくつかの最も注目すべきニュースメーカーを見てみましょう...
「Databricks、MosaicMLおよびその他の最近のAIの買収を発表」
経済は非常にダイナミックですが、AIはまだホットな市場です過去数週間にはいくつかの大規模な買収や合併があり、それぞれが近い将来の市場を再定義する可能性がありますそれでは、いくつかの最大のニュースメーカーを見てみましょう...
「DatabricksがMosaicMLとその他の最近のAIの買収を行う」
経済は非常にダイナミックであるにもかかわらず、AIはまだ注目の市場です過去数週間でいくつかの大規模な買収と合併が行われ、それぞれが近い将来の市場を再定義する可能性がありますでは、いくつかの最も注目すべきニュースメーカーを見てみましょう...
AIの台頭が犬食い犬のテック産業を牽引している
「テクノロジー業界が根本的な変革を遂げていることについては、私と同意していただけると思いますあなたもそれを見ることができますし、私も見ることができますAIを活用したソリューションの急速な開発が、...」

「これらの仕事はAIによって置き換えられると考える人もいる私たちは異論を唱えます」
「人工知能が仕事を置き換えるという議論は、ChatGPTや他の生成型AIツールが世界中で大流行するにつれてますます広がっていますしかし、信じるかどうかは別として、それだけが全てではありません実際、産業革命と同様に、AI革命も仕事を...」

Google Cloud上のサーバーレストランスフォーマーパイプラインへの私の旅
コミュニティメンバーのマクサンス・ドミニシによるゲストブログ投稿 この記事では、Google Cloudにtransformers感情分析パイプラインを展開するまでの道のりについて説明します。まず、transformersの簡単な紹介から始め、実装の技術的な部分に移ります。最後に、この実装をまとめ、私たちが達成したことについてレビューします。 目標 Discordに残された顧客のレビューがポジティブかネガティブかを自動的に検出するマイクロサービスを作成したかったです。これにより、コメントを適切に処理し、顧客の体験を向上させることができます。たとえば、レビューがネガティブな場合、顧客に連絡し、サービスの品質の低さを謝罪し、サポートチームができるだけ早く連絡し、問題を修正するためにサポートすることができる機能を作成できます。1か月あたり2,000件以上のリクエストは予定していないため、時間と拡張性に関してはパフォーマンスの制約を課しませんでした。 Transformersライブラリ 最初に.h5ファイルをダウンロードしたとき、少し混乱しました。このファイルはtensorflow.keras.models.load_modelと互換性があると思っていましたが、実際にはそうではありませんでした。数分の調査の後、ファイルがケラスモデルではなく重みのチェックポイントであることがわかりました。その後、Hugging Faceが提供するAPIを試して、彼らが提供するパイプライン機能についてもう少し調べました。APIおよびパイプラインの結果が素晴らしかったため、自分自身のサーバーでモデルをパイプラインを通じて提供することができると判断しました。 以下は、TransformersのGitHubページの公式の例です。 from transformers import pipeline # 感情分析のためのパイプラインを割り当てる classifier = pipeline('sentiment-analysis') classifier('We are very happy to include…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.