Learn more about Search Results 認証 - Page 27

- You may be interested
- スキット-ラーンのカスタムスコアリング関数
- AWS Inferentia2は、AWS Inferentia1をベ...
- 「世界は誰も知らない60年前のコードに依...
- サイバーエキスパートたちは、2024年の米...
- ビジュアルトランスフォーマー(ViT)モデ...
- ChatGPT CLI コマンドラインインターフェ...
- Hugging Faceを使用してWav2Vec2を英語音...
- 需要を駆動するための新しいAIパワード広...
- スマートデバイスのサイバーセキュリティ...
- 「Pythonを使って現実世界のデータにおけ...
- 「Python Rayは、分散コンピューティング...
- UCバークレーの研究者たちは、Gorillaとい...
- 2023年の最高のオープンソースインテリジ...
- Pythonコード生成のためのLlama-2 7Bモデ...
- パンダの文字列操作を高速化する

ChatGPTは自己を規制するための法律を作成する
コスタリカは、人工知能(AI)の規制において興味深い一歩を踏み出しました。法的な専門知識の源泉として予想外の存在であるChatGPTを活用し、AIに関する新しい法律の起草に協力を仰ぎました。このAI搭載のチャットボットは、「弁護士のように考える」という驚異的な能力を持ち、コスタリカの憲法に合致した法案の作成を担当しました。AIの規制の未来を形作るこの非凡な取り組みの詳細について探ってみましょう。 また読む:米国議会が行動を起こす:人工知能の規制を提案する2つの新法案 AI法制度の専門知識において、議会がChatGPTを頼る コスタリカの政治家たちは、急速に進化する人工知能の分野を規制する緊急の必要性を認識しています。包括的な法律を作成するという複雑な課題に直面し、彼らはOpenAIが開発した知識と自然言語処理能力を備えたChatGPTの支援を求めました。国の憲法に基づく法案の起草をChatGPTに指示しました。 また読む:ChatGPTの偽の法的研究に騙された弁護士 AI規制における独自のアプローチが具体化 コンスタンサ・ヴァネッサ・カストロ議員の指導のもと、コスタリカにおけるAIの規制を目指す取り組みが勢いを増しています。ChatGPTの役割は重要であり、完全かつ緻密に作成された文書を提供し、提案法の基礎となりました。提案法の導入は好意的な意見と批判的な意見の両方を引き出し、AI規制におけるこの画期的な一歩の重要性が浮き彫りになりました。 また読む:中国が生成AIサービスを規制する大胆な一歩を踏み出す AI制御の重要な推奨事項 ChatGPTの専門知識により、コスタリカにおけるAIシステムの統治に必要な一連の重要な推奨事項が生まれました。チャットボットは、AI技術を監督する独立した規制機関の設立を提案しました。この機関は、説明責任、説明可能性、バイアスの防止、人権の保護などの重要な原則に基づいて運営されることが想定されています。これらの価値観を取り入れることで、提案法はコスタリカで倫理的かつ責任あるAIの使用を確保します。 また読む:OpenAIとDeepMindが英国政府と協力してAIの安全性と研究を進める 実施への道 提案法は、5月に正式に提出され、コスタリカのAI規制への道の重要な節目となっています。ただし、この法案は現在、さまざまな関係者からの意見と見解を集めるために公開討論のフェーズを経ています。このプロセスにより、法案は議会のさらなる検討と改善のための委員会に到達する前に、改訂と追加の討論が容易になります。 人間の介入は依然として重要 AIは驚異的な能力を示していますが、コンスタンサ・ヴァネッサ・カストロ議員は、立法における人間の介入の重要性を強調しています。この取り組みは、人工知能が人間の意思決定を補完するツールとして見るべきであり、それを置き換えるものではないということを示しています。コスタリカのAI規制のアプローチは、技術の進歩と人間の判断に必要な倫理的な考慮事項をバランスさせることを目指しています。 異なる視点と批判 コスタリカは、AI規制を検討するラテンアメリカ諸国の中で増え続ける数の一つです。AIのガバナンスに広範な支持はありますが、提案された法律に対してすべての立法者が同じ意見を持っているわけではありません。コスタリカの国会議員であるヨハナ・オバンドは、提案法が実質的な内容を欠き、「良い願いのリスト」を示しているだけだとして、法案に対する懸念を表明しました。オバンドは、ChatGPTが国家憲法から条文を作成することで、提案法の正確性と信頼性に疑問が投げかけられると考えています。 また読む:法律部門におけるAI革命:裁判所でチャットボットが中心に 国際基準に基づく展開 オバンドは、AI規制を基本的な権利と国際的な協定に基づいて策定することの重要性を強調しています。ただし、現在議論中の法案には、これらの権利と協定への具体的な言及がなく、改善の余地があります。ラテンアメリカでは、EUのAI法が参考とされており、生体認証の監視でのAIの使用の禁止や、AIによる情報の透明性を義務付けるなどのガイドラインが適用されています。 また読む:EU、ディープフェイクとAIコンテンツの特定策を求める ラテンアメリカにおける倫理的AIフレームワークへの取り組み この地域の立法者たちは、AI利用に関する倫理的な枠組みの開発に積極的に取り組んでいます。たとえば、メキシコは3月に個人情報と人権の保護に焦点を当てた倫理的な枠組みの確立を奨励する法案を導入しました。同様に、ペルーの議会は最近、デジタルセキュリティと倫理の原則を強調した最初のAIに関する法律を承認しました。これらの立法の努力は、AIの利用が倫理的で透明性があり、持続可能な環境を創造することを目指しています。 また読む:倫理的なAIの統治:非倫理的なAIを防ぐ規則と法規制…

2023年に知っておくべきトップ15のビッグデータソフトウェア
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の推進力となっているため、私たちは出会う膨大な情報を処理するための最先端のツールにアクセスすることが重要です。しかし、数多くのオプションがあるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかることがあります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の洞察力と厳選された必須のビッグデータツールのリストを提供することで、情報を基にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動型の世界の課題に取り組み、ビジネスの可能性を最大限に引き出すことができます。一緒にこの旅に乗り出し、意思決定を革新する可能性のあるビッグデータ科学ツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さにより、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化における高い効率と技術を示しています。それは、数多くのソースから得られた構造化、半構造化、非構造化データで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム 価値 速度 なぜビッグデータソフトウェアと分析を使用するのですか? 以下は、ビッグデータソフトウェアと分析を使用する一般的な理由です: 記述的、予測的、規定的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータ型の処理を容易にするため 組織に対する費用効果のあるソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客エクスペリエンスの向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…
「2023年に知っておくべきトップ15のビッグデータソフトウェア」
はじめに 今日の急速に進化する世界では、データが意思決定とビジネスの成長の原動力となるため、私たちは出会う膨大な情報を処理するための最新のツールにアクセスすることが重要です。しかし、数多くの選択肢があるため、完璧なビッグデータソフトウェアを見つけるのには多くの時間と労力がかかる場合があります。 そのため、私たちはこの重要なプロセスで貴重な支援を提供することの重要性を理解しています。私たちの目標は、最新の情報と厳選された必須のビッグデータツールのリストを提供し、情報を元にした意思決定を行えるようにすることです。 これらのリソースと推奨事項を活用することで、データ駆動の世界の課題に取り組み、ビジネスのフルポテンシャルを引き出すことができます。一緒にこの旅に出かけて、意思決定を革新することができるビッグデータサイエンスツールの領域を探索しましょう。 ビッグデータとは何ですか? その巨大なサイズ、多様性、複雑さから、それはビッグデータと呼ばれるようになりました。ビッグデータは、取得、処理、輸送、組織化のための高効率な技術を備えています。様々なソースから得られる構造化、半構造化、非構造化のデータで構成されています。ビッグデータには以下の5つのVが含まれます: 多様性 真実性 ボリューム バリュー 速度 なぜビッグデータソフトウェアと分析が必要なのですか? ビッグデータソフトウェアと分析を使用する一般的な理由は以下の通りです: 記述的、予測的、指示的な分析でデータの使用を活用するため 大量のデータを処理するため リアルタイムの更新と分析のため さまざまなデータタイプの処理を容易にするため 組織に費用対効果の高いソリューションを提供するため 意思決定の向上のため 競争力の向上のため 顧客体験の向上のため トップ15のビッグデータソフトウェアのリスト Apache Hadoop…

「IoTエッジデバイスのためのクラウドベースのAI/MLサービスの探索」
AIとMLは、自動運転車、ウェブ検索、音声認識などの進歩を可能にしましたIoTデバイスのAIとMLの探求に興味がある場合、お手伝いできます

「人工知能がゼロトラストを強化する方法」
「技術は絶えず進化し、産業の運営方法を変えていますゼロトラストセキュリティは、サイバーセキュリティの世界で大きな影響を与えています多くの企業が迅速にこの慣行を採用し、従業員が安全にどこからでも作業できるように安心感を持つようにしましたゼロトラストセキュリティには、効果的に運用するために堅牢な技術が必要であり、人工知能(AI)の台頭とともに...」

「ゼロトラストネットワークアクセス(ZTNA)の統合によるサイバーセキュリティの強化」
現在の急速に進化するサイバーセキュリティの景観の中で、組織は従来のセキュリティモデルに挑戦するますます洗練された脅威に直面していますこれらのリスクに対抗するために、より堅牢で効果的なアプローチである「ゼロトラストネットワークアクセス(ZTNA)」と呼ばれるパラダイムシフトが進行中ですZTNAは積極的なセキュリティフレームワークとして重要性を増しており、...
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
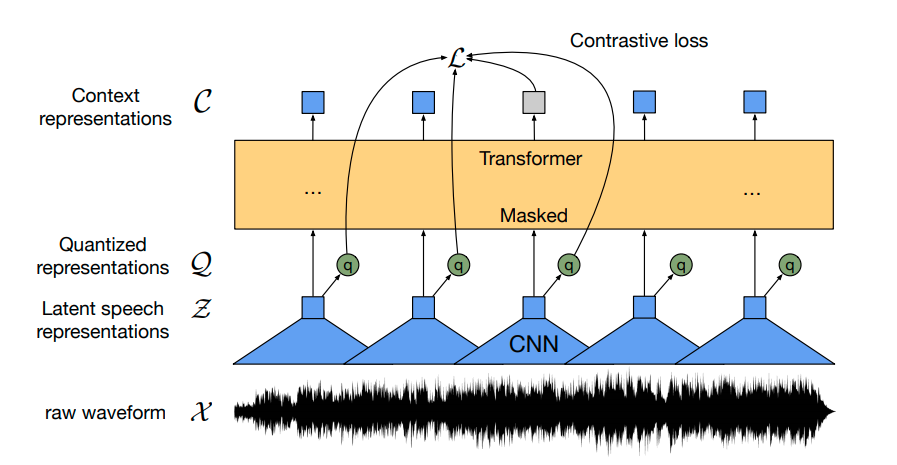
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

Pythonを使用した感情分析の始め方
感情分析は、データを感情に基づいてタグ付けする自動化されたプロセスです。感情分析により、企業はデータをスケールで分析し、洞察を検出し、プロセスを自動化することができます。 過去には、感情分析は研究者、機械学習エンジニア、または自然言語処理の経験を持つデータサイエンティストに限定されていました。しかし、AIコミュニティは最近、機械学習へのアクセスを民主化するための素晴らしいツールを開発しました。今では、わずか数行のコードを使って感情分析を行い、機械学習の経験が全くなくても利用することができます!🤯 このガイドでは、Pythonを使用した感情分析の始め方についてすべてを学びます。具体的には以下の内容です: 感情分析とは何か? Pythonで事前学習済みの感情分析モデルを使用する方法 独自の感情分析モデルを構築する方法 感情分析でツイートを分析する方法 さあ、始めましょう!🚀 1. 感情分析とは何ですか? 感情分析は、与えられたテキストの極性を特定する自然言語処理の技術です。感情分析にはさまざまなバリエーションがありますが、最も広く使用されている技術の1つは、データを「ポジティブ」、「ネガティブ」、または「ニュートラル」のいずれかにラベル付けするものです。たとえば、次のようなツイートを見てみましょう。@VerizonSupportをメンションしているものです: “dear @verizonsupport your service is straight 💩 in dallas.. been with y’all over…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.