Learn more about Search Results - Page 27

- You may be interested
- あなたのVoAGIポスト-なぜPythonでリスト...
- 「ダークウェブを照らす」
- AIの聴覚スキルを革命化する:清華大学と...
- 「AIが執筆プロセスに民主化をもたらして...
- 「ログモジュールを使用してPythonスクリ...
- 「AIバイアス&文化的なステレオタイプ:...
- スマートインフラストラクチャのリスク評...
- 宇宙におけるAIの10の使用例
- 『究極の没入型視覚化とモデリング体験を...
- 『AI規制に関するEUの予備的な合意:ChatG...
- 「Azureのコストを最適化するための10の方...
- 「金融業界におけるAIの進出:自動取引か...
- 「最初のAIエージェントを開発する:Deep ...
- UTオースティンとUCバークレーの研究者が...
- 「NVIDIA H100 Tensor Core GPUを使用した...
なぜ仮説検定はハムレットからヒントを得るべきか
もし科学者またはデータ専門家である場合、あなたの仮説検定手順には、通常のコースワークから悲劇的に(あるいは悲喜劇的に?)省略される重要なステップが欠けている可能性があります...

AIを活用した言語学習アプリの構築:2つのAIチャットからの学習
新しい言語を学び始めるときは、私は「会話ダイアログ」の本を買うのが好きです私はそのような本が非常に役立つと思っていますそれらは、言語がどのように動作するかを理解するのに役立ちます単に…

近接度とコミュニティ:PythonとNetworkXによるソーシャルネットワークの分析—Part 3
PythonとNetworkXを使用して近接中心性を計算し、ネットワークグラフを可視化する方法を学び、社会ネットワーク分析を実施する方法を学びます

LLMの巨人たちの戦い:Google PaLM 2 vs OpenAI GPT-3.5
2023年5月10日、GoogleはOpenAIのGPT-4に対する見事な対抗策としてPaLM 2をリリースしました最近のI/Oイベントで、Googleは最小から最大までの魅力的なPaLM 2モデルファミリーを発表しました
特徴量が多すぎる?主成分分析を見てみましょう
次元の呪いは、機械学習における主要な問題の1つです特徴量の数が増えると、モデルの複雑さも増しますさらに、十分なトレーニングデータがない場合、それは...
チャットGPTの潜在能力を引き出すためのプロンプトエンジニアリングのマスタリング
プロンプトエンジニアリングは、ChatGPTやその他の大規模言語モデルのおかげで、風のように私たちの生活の一部にすぐになりました完全に新しい分野ではありませんが、現在...
Google Researchにおける責任あるAI 社会的善のためのAI
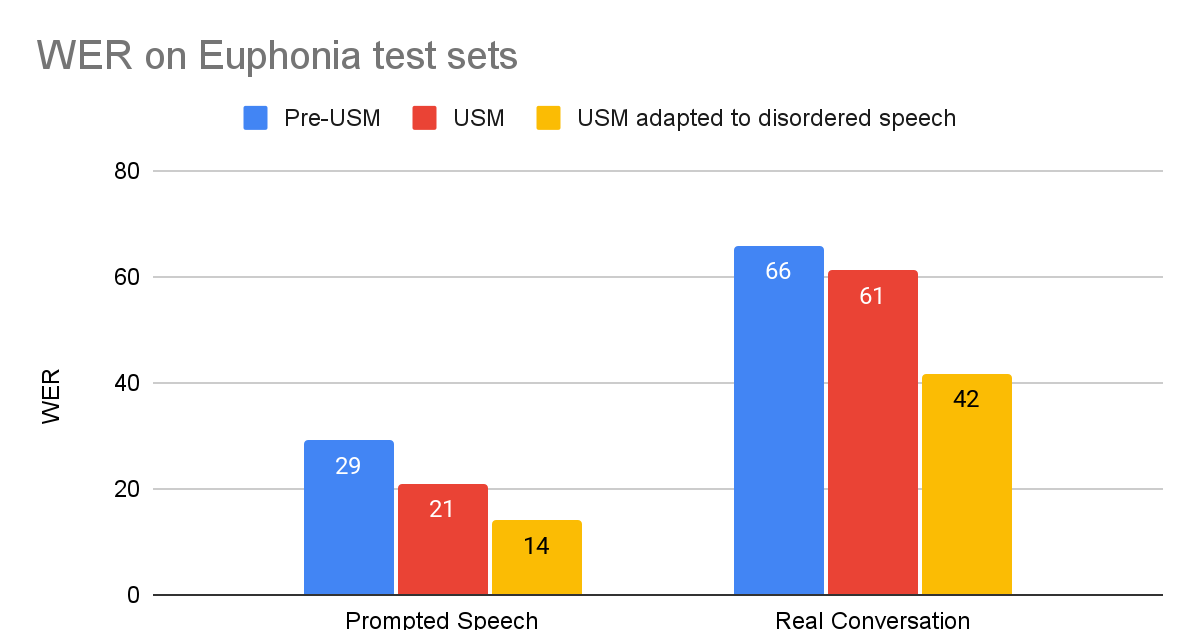
Google Research、AI for Social GoodのソフトウェアエンジニアであるJimmy TobinとKatrin Tomanekが投稿しました。 GoogleのAI for Social Goodチームは、研究者、エンジニア、ボランティア、その他のメンバーが、ポジティブな社会的インパクトに焦点を合わせたチームです。私たちの使命は、公衆衛生、アクセシビリティ、危機対応、気候とエネルギー、自然と社会の各分野で、現実世界での価値を実現することによって、AIの社会的な利益を示すことです。私たちは、未開発なコミュニティに対してポジティブな変化をもたらす最良の方法は、変化をもたらす人々やその組織と協力することだと信じています。 このブログ記事では、AI for Social Good内のチームであるProject Euphoniaが行った作業について説明します。このチームは、障害のある人々のための自動音声認識(ASR)の改善を目的としています。通常の発話を持つ人々にとって、ASRモデルの単語エラー率(WER)は10%未満になることがありますが、吃音、失語症、失行症などの障害のある人々の場合、エチオロジーと重症度に応じてWERは50%または90%に達することがあります。この問題に対処するために、私たちは1,000人以上の参加者と協力して、1,000時間以上の障害のある音声サンプルを収集し、個人化されたASRが障害のある人々のパフォーマンスギャップを埋めるための実現可能な道であることを示しました。私たちは、レイヤー凍結技術を使用して、3〜4分のトレーニング音声で個人化が成功することを示しました。 この作業は、個人化された音声モデルを必要とする人々にとって有益であるProject Relateの開発につながりました。GoogleのSpeechチームと共同で構築されたProject Relateは、典型的な音声の理解が難しい人々が自分自身のモデルをトレーニングできるようにするものです。人々はこれらの個人化されたモデルを使用して、より効果的にコミュニケーションを取り、より独立した生活を送ることができます。ASRをよりアクセス可能で使いやすくするために、デジタルアシスタント技術、ディクテーションアプリ、および会話で使用するために、GoogleのUniversal Speech Model(USM)を調整する方法について説明します。 課題に対処する Project Relateのユーザーと緊密に連携して作業を行うことで、個人化されたモデルは非常に有用であることが明らかになりましたが、多くのユーザーにとって、数十または数百の例を記録することは困難です。さらに、個人化されたモデルは、自由形式の会話では常にうまく機能しなかったこともわかりました。…
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…

LlamaIndex インデックスと検索のための究極のLLMフレームワーク
LlamaIndex(以前はGPT Indexとして知られていました)は、データ取り込みを容易にする必須ツールを提供することで、LLMを使用したアプリケーションの構築を支援する注目すべきデータフレームワークです
Amazon SageMaker 上で MPT-7B を微調整する
毎週新しい大規模言語モデル(LLM)が発表され、それぞれが前任者を打ち負かして評価のトップを狙っています最新のモデルの1つはMPT-7Bです
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.