Learn more about Search Results 24 - Page 279

- You may be interested
- Hugging Face Unity APIのインストールと...
- ネットワークフローアルゴリズムの探求:...
- テキストのポテンシャルを引き出す:プリ...
- 「Microsoft AI Researchは、Pythonで直接...
- 「GoogleはニュースのためのAIを宣伝し、...
- ドメイン特化の大規模言語モデルの6つの例
- 「サンゴ礁の衰退を転換する:CUREEロボッ...
- USCの研究者は、新しい共有知識生涯学習(...
- 「NVIDIAのAIが地球を気候変動から救う」
- BYOL(Bootstrap Your Own Latent)— コン...
- 「Wall-Eのための経路探索アルゴリズムの...
- このチューリング賞を受賞した研究者は、...
- ミストラルAIの最新のエキスパート(MoE)...
- この AI ペーパーでは、X-Raydar を発表し...
- 「あなたのLLMパイプラインは目標を達成し...
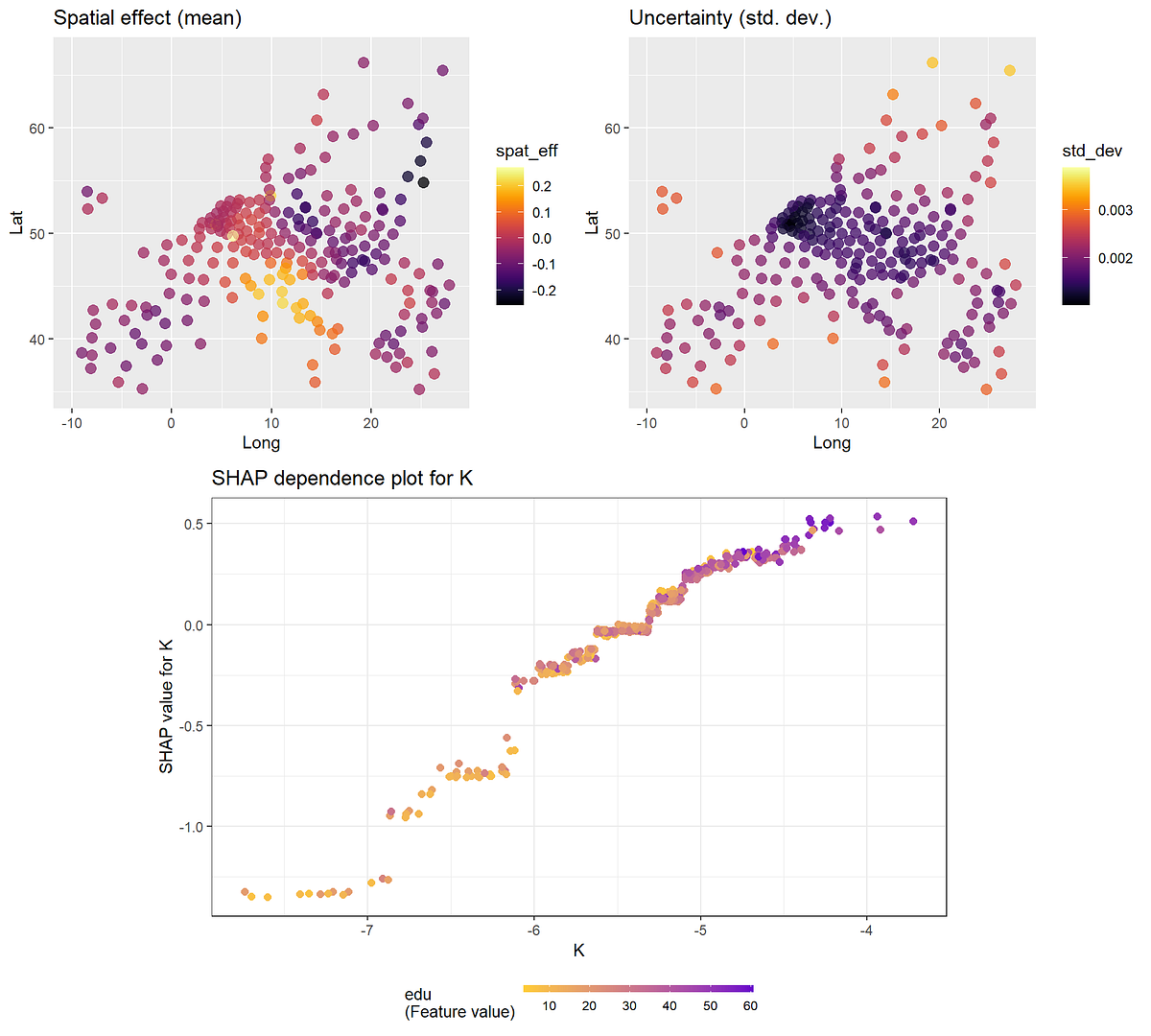
グループ化および空間計量データの混合効果機械学習におけるGPBoost
GPBoostを用いたグループ化されたおよび地域空間計量データの混合効果機械学習 - ヨーロッパのGDPデータを用いたデモ
PythonからJuliaへ:基本的なデータ操作とEDA
統計計算の領域でエマージングなプログラミング言語として、Julia は近年ますます注目を集めています他の言語に優る2つの特徴があります...

Gmailを効率的なメールソリューションに変える6つのAI機能
GoogleのGmailは、人工知能(AI)の力を活用してユーザーエクスペリエンスを向上させることに最前線で取り組んでいます。AIをプラットフォームに統合する歴史を持ち、Gmailは進化を続け、電子メールの管理を簡素化し、コミュニケーションを効率化する機能を提供しています。この記事では、Gmailを世界中のユーザーにとって必須のツールにする6つのAI機能を探究します。 1. 「書き方を教えて」: Gmailの最新機能である「書き方を教えて」機能は、シンプルなプロンプトに基づいて完全なメールの下書きを生成し、ユーザーが簡単にメールを作成することができるようにします。Workspace Labsプログラムを介してアクセスできるこの機能により、生成的AI言語モデルを活用して、ユーザーは自分の好みに応じてメールを磨き、カスタマイズ、調整することができます。また、このツールは、以前の会話から詳細を抽出し、文脈に沿ったアシストを提供することもできます。 2. Smart Compose: Smart Composeは、ユーザーがタイプする間に文言のオプションを提案することで、メール作成を革命化します。 Tensor Processing Units (TPUs) 上で動作するこのハイブリッド言語生成モデルにより、ユーザーは「Tab」ボタンを1回タップするだけで提案されたフレーズや文章を自分の下書きに組み込むことができます。効率性を向上させるだけでなく、Smart Composeは新しい英語、スペイン語、フランス語、イタリア語のフレーズを提示することによって言語学習者を支援します。 3. Smart Reply: GmailのSmart Reply機能は、受信したメッセージに対して文脈に沿った最大3つの返信を提供することで、メールのコミュニケーションを加速します。深層ニューラルネットワークを含む高度な機械学習技術によって動作するSmart Replyは、単純な「はい」または「いいえ」の回答を超えた微妙なオプションを提供します。ユーザーは迅速に適切な返信を選択して送信することができ、時間と労力を節約することができます。Smart Replyは、ユーザーのコミュニケーションスタイルに適応し、パーソナライズを向上させます。 4.…

TRACE(トレース)に会おう:グローバル座標トラッキングを使用した正確な3D人体姿勢および形状推定のための新しいAIアプローチ
多くの分野が、3D人間姿勢と形状(HPS)の最近の進歩を利用し、活用することができます。しかし、ほとんどのアプローチは一度に単一のフレームしか考慮せず、カメラに対する人間の位置を推定します。さらに、これらの技術は個人を追跡できず、その世界的な移動経路を取得することができません。ほとんどの手持ちのビデオは、カメラが揺れ動くジャイロスコープで撮影されるため、この問題はより複雑になります。 これらの問題を解決するために、哈爾濱工業大学、京東探索院、マックスプランク知能システム研究所、HiDream.aiの研究者たちは、5D表現(空間、時間、アイデンティティ)を使用して、状況における人物に関する新しいエンドツーエンドの推論を実装しました。提案されたTRACE技術には、さまざまな革新的なアーキテクチャ機能があります。特に、2つの新しい「Maps」を使用して、カメラの視点と世界の視点の両方から、人々の3Dモーションについて推論することができます。第2のメモリモジュールの助けを借りて、長期の不在の後も個人を追跡することができます。TRACEは、移動するカメラからグローバル座標の3D人間モデルを単一のステップで回復し、同時にその動きを追跡します。 彼らの目的は、各人のグローバル座標、3D位置、形状、アイデンティティ、およびモーションを同時に再構成することでした。これを行うために、TRACEは、まず、専用のブレーンネットワークを使用して、各サブタスクをデコードする前に、時間情報を抽出します。まず、TRACEは、ビデオとモーションを別々の特徴マップにエンコードするために2つの並列軸を使用し、1つは時間的な画像(F’i)用で、もう1つはモーション(Oi)用です。これらのフィーチャを使用して、検出およびトラッキングサブツリーが複数の対象を追跡して、カメラ座標内の3D人間のモーションを再構成します。 推定された3Dモーションオフセットマップは、2つのフレーム間の各被写体の相対的な空間移動を示します。革新的なメモリユニットは、推定された3D検出と3Dモーションオフセットを使用して、被写体のアイデンティティを抽出し、カメラ座標内で人間の軌跡を構築します。小説のWorldブランチは、世界の座標系で被写体の軌跡を推定するために、世界のモーションマップを計算します。 堅牢な5D表現であっても、実際の世界のデータがないため、グローバルな人間の軌跡推定のトレーニングと評価の欠如が続いています。ただし、自然環境の動的カメラムービー(DCビデオ)のグローバル人間軌跡とカメラ姿勢をコンパイルすることは困難です。したがって、チームは、シミュレートされたカメラモーションを使用して、静止カメラで取得したワイルドフィルムをDCビデオに変換し、DynaCamという新しいデータセットを生成しました。 チームは、DynaCamデータセットと2つのマルチパーソンインザワイルドベンチマークを使用して、TRACEをテストしました。3DPWに関しては、TRACEがSOTAの結果を提供します。MuPoTS-3Dでは、TRACEが、長期の遮蔽下で人間を追跡するための既存の3D表現ベースのアプローチや検出によるトラッキング方法よりも優れた結果を達成します。調査結果は、DynaCamにおけるTRACEがGLAMRを上回ることを示しています。 チームは、将来、複雑な人間の動き、3Dシーン、およびカメラの動きを含むBEDLAMなどのトレーニングデータを使用した明示的なカメラモーション推定を調査することを提案しています。

ChatGPTのバイアスを解消するバックパック:バックパック言語モデルはトランスフォーマーの代替AI手法です
AI言語モデルは私たちの生活の中で不可欠なものになっています。情報にアクセスするために数十年間Googleを使用してきましたが、今では徐々にChatGPTに切り替えています。ChatGPTは簡潔な回答と明確な説明を提供し、必要な情報を見つけるのが通常よりも速くなります。 これらのモデルは、私たちが長年にわたって生み出したデータから学習します。その結果、私たちはAIモデルにバイアスを転送し、これは議論の対象となっています。注目されている特定のバイアスの1つは、代名詞の分布におけるジェンダーバイアスであり、モデルが文脈に基づいて「彼」「彼女」といったジェンダーに関連する代名詞を好む傾向があるというものです。 このジェンダーバイアスに対処することは、公正で包括的な言語生成を確保するために重要です。たとえば、「CEOは信じている…」という文章を始めると、モデルは彼と続け、CEOを看護師に置き換えると、次のトークンは彼女になります。この例は、バイアスを調べ、それらを緩和する方法を探るための興味深い事例研究として役立ちます。 実際には、文脈はこれらのバイアスを形成する上で重要な役割を果たします。CEOを、異なるジェンダーに一般的に関連付けられている職業に置き換えることで、観察されたバイアスを反転することができます。しかし、ここでの課題は、CEOが現れるすべての異なる文脈で一貫してデバイアスを実現することです。特定の状況に関係なく、信頼性が高く、予測可能な介入を望んでいます。言語モデルを理解し、改善するためには解釈性と制御が重要です。残念ながら、現在のTransformerモデルは、その性能に驚くべきものがあるにもかかわらず、これらの基準を完全に満たしていません。彼らの文脈表現は、手元の文脈に依存する複雑で非線形な効果を導入します。 では、これらの課題をどのように克服できますか?大規模言語モデルに導入したバイアスにどう対処すればよいのでしょうか?Transformerを改善するべきなのでしょうか、それとも新しい構造を考えるべきなのでしょうか?答えはBackpack Language Modelsです。 Backpack LMは、センスベクトルとして知られる文脈非依存の表現を利用して、代名詞分布のデバイアス化の課題に取り組みます。これらのベクトルは、単語の意味と異なる文脈での役割を捉え、単語に複数のパーソナリティを与えます。 Backpack LMの概要。 出典:https://arxiv.org/pdf/2305.16765.pdf Backpack LMsでは、予測はセンスベクトルとして知られる文脈非依存の表現の対数線形の組み合わせになります。語彙中の各単語は、異なる文脈での単語の潜在的な役割を表す複数のセンスベクトルで表されます。 これらのセンスベクトルは、特定の文脈で予測的に有用になるように専門化されます。シーケンス内の単語のセンスベクトルの加重和は、コンテキスト関数によって決定されるシーケンス全体に作用する文脈関数によって決定されるBackpack 表現を形成し、重みが決定されます。これらのセンスベクトルを活用することで、Backpack モデルは、すべての文脈で予測可能な介入を実現します。 つまり、モデルに対して文脈非依存の変更を行っても、一貫してその振る舞いに影響を与えることができます。Transformerモデルに比べ、Backpack モデルはより透明性が高く、管理しやすいインターフェースを提供します。理解しやすく制御しやすい正確な介入を提供します。さらに、Backpack モデルは性能を犠牲にすることなく、Transformerモデルと同等の結果を実現します。 センスベクトルの例。 出典:https://backpackmodels.science/ Backpackモデルの意味ベクトルは、最新のトランスフォーマーモデルの単語埋め込みよりも豊富な単語の意味をエンコードしており、語彙の類似性タスクで優れた性能を発揮しています。さらに、職業に関する単語のジェンダーバイアスを減らすなど、意味ベクトルに介入することで、Backpackモデルが提供する制御機構が示されています。ジェンダーバイアスに関連する意味ベクトルを縮小することにより、限られた環境で文脈予測の不均衡を大幅に削減することができます。

単一モダリティとの友情は終わりました – 今やマルチモダリティが私の親友です:CoDiは、合成可能な拡散による任意から任意への生成を実現できるAIモデルです
ジェネレーティブAIは、今ではほぼ毎日聞く用語です。私はジェネレーティブAIに関する論文をどれだけ読んでまとめたか覚えていません。彼らは印象的で、彼らがすることは非現実的で魔法のようであり、多くのアプリケーションで使用できます。テキストプロンプトを使用するだけで、画像、動画、音声などを生成できます。 近年のジェネレーティブAIモデルの大幅な進歩により、以前は不可能と考えられていたユースケースが可能になりました。テキストから画像へのモデルで始まり、信じられないほど素晴らしい結果が得られたことがわかった後、複数のモダリティを扱うことができるAIモデルの需要が高まりました。 最近は、任意の入力の組み合わせ(例:テキスト+音声)を取り、様々な出力の組み合わせ(例:ビデオ+音声)を生成できるモデルの需要が急増しています。これを対処するためにいくつかのモデルが提案されていますが、これらのモデルは、共存し相互作用する複数のモダリティを含む現実世界のアプリケーションに関して制限があります。 モダリティ固有の生成モデルを多段的なプロセスでつなげることは可能ですが、各ステップの生成力は本質的に限定されるため、手間がかかり、遅いアプローチとなります。また、独立に生成された単一モダルストリームは、組み合わせるときに一貫性や整合性が欠けることがあり、後処理の同期が困難になる場合があります。 任意の入力モダリティの混合を処理し、任意の出力の組み合わせを柔軟に生成するためのモデルをトレーニングするには、膨大な計算およびデータ要件が必要です。可能な入力-出力の組み合わせの数は指数関数的に増加し、多数のモダリティグループに対して整列したトレーニングデータはまれまたは存在しないためです。 ここで、この課題に取り組むために提案されたCoDiというモデルを紹介しましょう。 CoDiは、任意のモダリティの任意の組み合わせを同時に処理および生成することを可能にする新しいニューラルアーキテクチャです。 CoDiの概要。出典:https://arxiv.org/pdf/2305.11846.pdf CoDi は、入力条件付けおよび生成拡散ステップの両方で複数のモダリティを整列させることを提案しています。さらに、対照的な学習のための「ブリッジングアライメント」戦略を導入し、線形数のトレーニング目標で指数関数的な入力-出力の組み合わせを効率的にモデル化できるようにしています。 CoDi の主要なイノベーションは、潜在的な拡散モデル(LDM)、多モダル条件付けメカニズム、およびクロスアテンションモジュールの組み合わせを利用して、任意の-to-任意の生成を処理することができる能力にあります。各モダリティ用に別々のLDMをトレーニングし、入力モダリティを共有特徴空間に射影することで、CoDi は、このような設定の直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを生成できます。 CoDiの開発には、包括的なモデル設計と多様なデータリソースでのトレーニングが必要です。最初に、テキスト、画像、動画、音声などの各モダリティに対して潜在的な拡散モデル(LDM)をトレーニングします。これらのモデルは独立して並行してトレーニングでき、モダリティに固有のトレーニングデータを使用して、卓越した単一モダリティ生成品質を確保します。音声+言語のプロンプトを使用して画像を生成する場合の条件付きクロスモダリティ生成では、入力モダリティを共有の特徴空間に射影し、出力LDMは入力特徴の組み合わせに注意を払います。この多モダル条件付けメカニズムにより、拡散モデルは直接的なトレーニングなしで、任意のモダリティまたはモダリティの組み合わせを処理できるようになります。 CoDiモデルの概要。出典:https://arxiv.org/pdf/2305.11846.pdf トレーニングの第2ステージでは、CoDiは、任意の出力モダリティの任意の組み合わせを同時に生成する多対多の生成戦略を処理します。これは、各ディフューザーにクロスアテンションモジュールを追加し、環境エンコーダーを追加して、異なるLDMの潜在変数を共有潜在空間に投影することによって実現されます。このシームレスな生成能力により、CoDiは、すべての可能な生成組み合わせでトレーニングすることなく、任意のモダリティのグループを生成できるため、トレーニング目標の数を指数関数から線形関数に減らすことができます。 (※以下、原文のHTMLコードを保持します) In the second stage of training, CoDi…

AWSが開発した目的に特化したアクセラレータを使用することで、機械学習ワークロードのエネルギー消費を最大90%削減できます
従来、機械学習(ML)エンジニアは、モデルの学習と展開コストとパフォーマンスのバランスを取ることに焦点を当ててきました最近では、持続可能性(エネルギー効率)が顧客にとって追加の目標となっていますこれは重要なことであり、MLモデルのトレーニングを行い、トレーニングされたモデルを使用して予測(推論)を行うことは、非常にエネルギーを消費するタスクであるためです加えて、さらに...

20以上のスタートアップに最適なAIツール(2023年)
AIによって、職場の創造性、分析、意思決定が革命化されています。現在、人工知能の能力は、企業が拡大を急ぎ、内部プロセスをより良く管理するための絶大な機会を提供しています。人工知能の応用は、自動化や予測分析からパーソナライゼーションやコンテンツ開発まで多岐にわたります。以下は、若いビジネスに有利に働く最高の人工知能ツールの概要です。 AdCreative.ai AdCreative.aiは究極の人工知能ソリューションで、広告やソーシャルメディアのゲームを強化します。創造的な作業に数時間費やす必要がなく、数秒で生成される高変換率の広告やソーシャルメディア投稿に別れを告げましょう。今すぐAdCreative.aiで成功を最大化し、努力を最小限に抑えましょう。 DALL·E 2 OpenAIのDALLE 2は、単一のテキスト入力から独自かつ創造的なビジュアルを作成する最先端のAIアートジェネレーターです。AIモデルは、画像とテキストの説明の巨大なデータセットでトレーニングされており、書かれたリクエストに応じて詳細で視覚的に魅力的な画像を生成します。スタートアップはDALLE 2を使用して広告やウェブサイト、ソーシャルメディアページの画像を作成し、手動でグラフィックを作成する必要がなく、テキストから異なる画像を生成するこの方法で時間とお金を節約することができます。 Otter AI Otter.AIは人工知能を使用して、共有可能で検索可能、アクセス可能、安全なミーティングノートのリアルタイムトランスクリプションをユーザーに提供します。音声を記録し、ノートを書き、自動的にスライドをキャプチャし、要約を生成するミーティングアシスタントを手に入れましょう。 Notion Notionは、最新のAI技術を活用してユーザー数を増やすことを目指しています。最新機能であるNotion AIは、ノートの要約、ミーティングでのアクションアイテムの識別、テキストの作成と修正などのタスクをサポートする堅牢な生成AIツールです。 Notion AIは、煩雑なタスクを自動化し、ユーザーに提案やテンプレートを提供することで、ワークフローを合理化し、ユーザーエクスペリエンスを最適化することで、最終的に簡単で改善された体験を提供します。 Motion Motionは、ミーティング、タスク、プロジェクトを考慮した日々のスケジュールを作成するためにAIを使用する賢いツールです。計画の手間を省いて、より生産的な人生に別れを告げましょう。 Jasper 先進的なAIコンテンツジェネレーターであるJasperは、その優れたコンテンツ製作機能でクリエイティブ業界で話題となっています。Jasperは、人間のライティングパターンを認識することから効率性が生まれ、グループが興味深いコンテンツを迅速に製作することができます。ランディングページや製品説明のコピーをより良く書くためにJasperをAIパワードのコンパニオンとして使用し、より魅力的で興味深いソーシャルメディア投稿を作成することができます。 Lavender リアルタイムAIメールコーチであるLavenderは、セールス業界でゲームチェンジャーとして広く認知されており、数千人のSDRs、AEs、およびマネージャーがメールのレスポンス率と生産性を向上させています。競争力のあるセールス環境では、効果的なコミュニケーションスキルが成功に不可欠です。スタートアップはLavenderを使用して、電子メールのレスポンス率を向上させ、見込み客とのより深い関係を構築することができます。 Speak AI…

Sealとは、大規模な3Dポイントクラウドに対して自己教示学習のための2Dビジョンファウンデーションモデルを活用し、「任意のポイントクラウドシーケンスをセグメント化する」AIフレームワークです
大規模言語モデル(LLMs)は、人工知能コミュニティで大きな話題となっています。 最近の影響力と驚異的なパフォーマンスは、ヘルスケア、ファイナンス、エンターテインメントなど、広範な産業に貢献しています。 GPT-3.5、GPT 4、DALLE 2、BERTなどのよく知られたLLMs、または基礎モデルは、短い自然言語プロンプトだけで独自のコンテンツを生成することにより、非常に優れたタスクを実行し、私たちの生活を簡素化しています。 SAM、X-Decoder、SEEMなどの最近のビジョン基礎モデル(VFMs)は、コンピュータビジョンの多くの進歩を遂げています。 VFMsは2D認識タスクで大きな進展を遂げていますが、3D VFM研究はまだ改善が必要です。 現在の2D VFMsを3D認識タスクに拡張することが必要であると研究者は提言しています。 重要な3D認識タスクの1つは、自動車用LiDARセンサによってキャプチャされたポイントクラウドのセグメンテーションであり、自動運転車の安全な運行に必要です。 既存のポイントクラウドセグメンテーション技術は、主にトレーニングのために注釈付けされた大規模なデータセットに依存しています。 ただし、ポイントクラウドのラベリングは時間がかかり、困難です。 すべての課題を克服するために、研究者チームは、自己教師あり表現学習をサポートするためにVFMsから意味的に豊かな知識を収集するSealというフレームワークを紹介しました。 クロスモーダル表現学習に着想を得て、Sealは、LiDARとカメラセンサの2D-3D関係を使用してクロスモーダル表現学習に高品質の対比的サンプルを開発することにより、自動車用ポイントクラウドでセルフサポート表現学習を実現します。 Sealには、拡張性、一貫性、汎用性の3つの重要な特性があります。 拡張性 – Sealは、VFMsを単にポイントクラウドに変換することで使用し、事前トレーニングの段階で2Dまたは3Dの注釈が必要なくなります。そのため、人間の注釈が必要な時間を削減するだけでなく、大量のデータを処理できます。 一貫性:アーキテクチャは、カメラからLiDARへのスペーシャルおよびテンポラルリンク、およびポイントからセグメントステージの両方でスペーシャルおよびテンポラルリンクを強制します。 Sealは、クロスモーダル相互作用をキャプチャすることにより、ビジョン、すなわちカメラとLiDARセンサのクロスモーダル相互作用を捕捉して、両モダリティから適切で一貫したデータを含む学習された表現を確実にします。 汎用性:Sealは、さまざまなポイントクラウドデータセットを含む下流アプリケーションに対する知識移転を可能にします。 それは、さまざまな解像度、サイズ、クリーン度、汚染レベル、実際のデータ、および人工データを持つデータセットを扱います。 研究チームが挙げた主な貢献のいくつかは次のとおりです。…

A.I.が建築家に職場デザインの変革をもたらす方法
より多くのハイブリッド労働者と新しいオフィスのニーズに対応するため、Zaha Hadid Architectsのような企業は解決策として人工知能に頼るようになっています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.