Learn more about Search Results 24 - Page 277

- You may be interested
- 「HybridGNetによる解剖学的セグメンテー...
- 効果的なマーケティングのためのポップア...
- 「中国人がマイクロソフトのクラウドをハ...
- 商務省は、「米国人工知能安全研究所」を...
- ツール・ド・フランスは、ChatGPTとデジタ...
- 「スロープ・トランスフォーマーに出会っ...
- GLM-130B:オープンなバイリンガル事前訓...
- 「機械学習チートシートのためのScikit-le...
- ディープラーニングのためのラストバーン...
- GPT2からStable Diffusionへ:Hugging Fac...
- 「キャリアのために右にスワイプ:仕事の...
- リトリーバル オーグメンテッド ジェネレ...
- ルーターLangchain:Langchainを使用して...
- このAI論文では、「ビデオ言語計画(VLP)...
- 『LLMWareの紹介:生成AIアプリケーション...
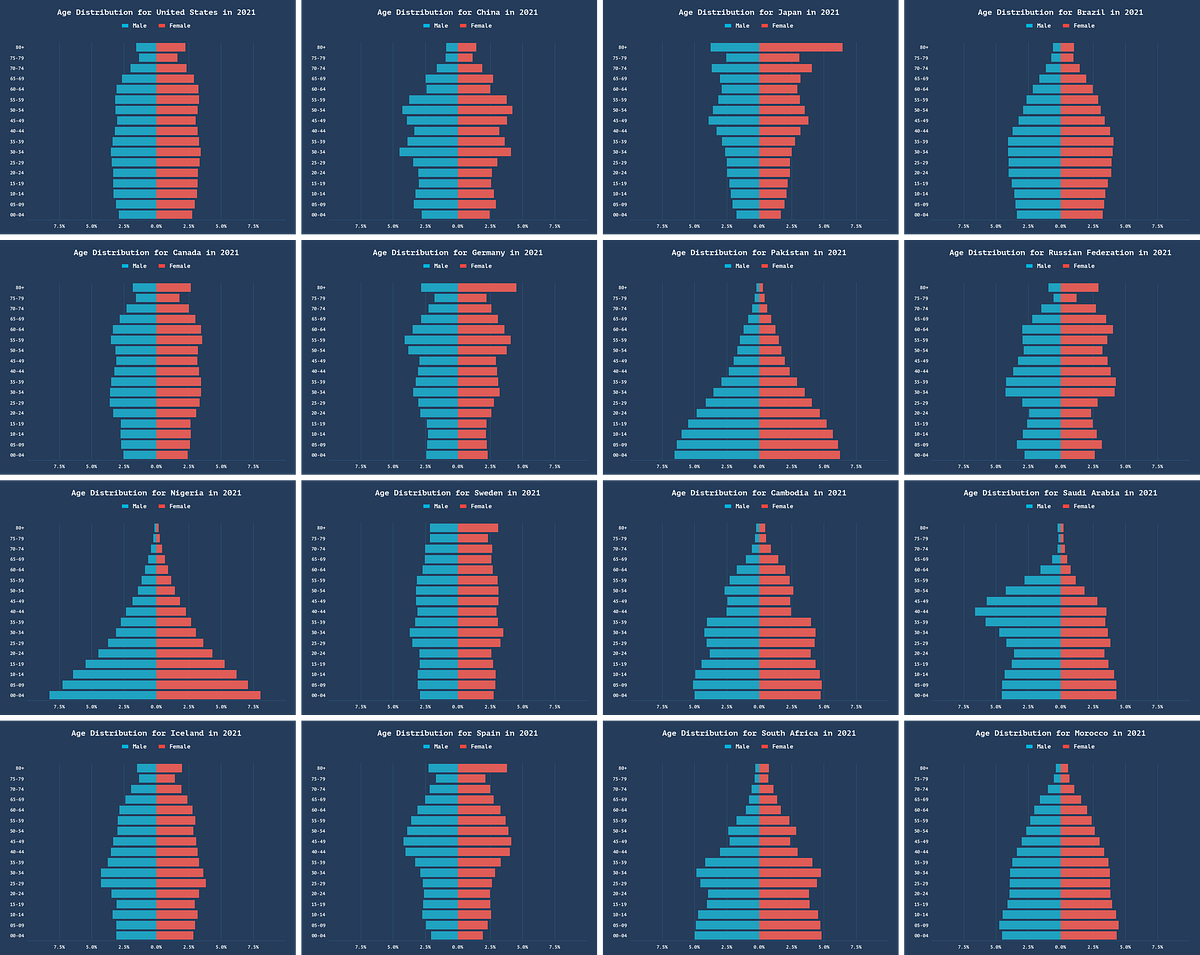
SeabornとMatplotlibを使用して美しい年齢分布グラフを作成する方法(アニメーションを含む)
今日は、matplotlibとseabornを使って上記のような美しい年齢分布グラフを作成する方法を紹介したいと思います年齢分布グラフは、人口統計の視覚化に優れています...

Light & WonderがAWS上でゲーミングマシンの予測保守ソリューションを構築した方法
この記事は、ライトアンドワンダー(L&W)のアルナ・アベヤコーン氏とデニス・コリン氏と共同執筆したものですライトアンドワンダーは、ラスベガスを拠点とするクロスプラットフォームゲーム会社であり、ギャンブル製品やサービスを提供していますAWSと協力して、ライトアンドワンダーは最近、業界初の安全なソリューション「Light & Wonder Connect(LnW Connect)」を開発しました[…]

ロボットは人間と同じく植物を育てることができますが、より少ない量の水を使用します
カリフォルニア大学バークレー校の研究者たちは、人間と同じように植物を育てることができ、より多くの水を節約することができるロボット園芸家を開発しました

ジョン・イサザ弁護士、FAI氏によるAIとChatGPTの法的な土壌を航行する方法
私たちは、Rimon LawのパートナーであるJohn Isaza, Esq., FAIに感謝しています彼は、法的な景観の変化、プライバシー保護とイノベーションの微妙なバランス、そしてAIツールを統合する際に生じる独特の法的な意義など、多岐にわたる側面で自身の物語と貴重な洞察を共有してくれましたJohnは、AIに関連する課題や考慮事項について貴重な観点を提供しています...John Isaza, Esq., FAI がAIとChatGPTの法的景観を航海するための記事を読む»

アルトコインへの投資:暗号市場の包括的ガイド
アルトコインとは、ビットコインの後に登場した他の暗号通貨のことですこれらのデジタル通貨は、分散型ブロックチェーン技術を介して運営され、先駆的な暗号通貨であるビットコインとは異なる用途を提供しています 「アルトコイン」という用語は、暗号空間で数年間使用されており、ビットコインを除く多数の暗号通貨を指します… アルトコインへの投資:暗号市場の包括的ガイド 詳細はこちら»

医薬品探索の革新:機械学習モデルによる可能性のある老化防止化合物の特定と、将来の複雑な疾患治療のための道筋を開拓する
老化やがん、2型糖尿病、骨関節炎、ウイルス感染などの他の病気は、細胞老化をストレス反応として含んでいます。老化細胞のターゲット化された除去は人気を博していますが、その分子標的がよりよく理解される必要があるため、senolyticsはほとんど知られていません。ここでは、科学者たちは、以前に発表されたデータのみで教育された比較的安価な機械学習アルゴリズムを使用して、3つのsenolyticを発見することを説明しています。さまざまなタイプの細胞老化を経験する人間の細胞株で、彼らは複数の化学ライブラリの計算スクリーニングを使用して、ginkgetin、periplocin、およびoleandrinのsenolytic作用を確認しました。これらの化学物質は、よく確立された分析法と同様に効果的であり、oleandrinは、そのターゲットに対して現在のゴールドスタンダードよりも効果的であることを示しています。この方法により、数百倍の薬剤スクリーニング費用が削減され、AIが限られた種類の薬剤スクリーニングデータを最大限に活用できることが示されています。これにより、薬剤探索の初期段階において、新しいデータ駆動型の方法が可能になりました。 senolyticsは、マウスの多くの疾患の症状を緩和することが示されていますが、その除去は、傷口治癒や肝臓機能などのプロセスの障害を引き起こすことも関連しています。有望な発見があるにもかかわらず、senolytic作用を持つ2つの薬剤しか臨床研究で有効性が示されていません。 過去には優れた分析法が開発されていますが、一般的に健康な細胞に有害です。現在、スコットランドのエディンバラ大学の研究者たちは、健康な細胞を傷つけることなく、これらの不良細胞を除去できる化学化合物を特定する革新的なアプローチを開発しました。 彼らは、senolyticの特性を持つ化合物を特定するための機械学習モデルを構築し、それを教育する方法を開発しました。広範囲に承認された薬剤または臨床段階の薬剤を含む2つの既存の化学ライブラリからの化学物質は、学習モデルのトレーニングに使用された各種のソースからのデータと結合されました(アカデミック論文や商業特許など)。機械学習システムにバイアスをかけないために、データセットにはsenolyticおよび非senolytic特性を持つ2,523の物質が含まれています。4,000以上の化合物のデータベースにアルゴリズムを適用した後、21の有望な候補が見つかりました。 テスト中に、ginkgetin、periplocin、およびoleandrinの3つの化合物は、健康な細胞に影響を与えずに老化細胞を除去することが示され、良好な候補物質となりました。結果は、oleandrinが3つの中で最も効果的であることを示しました。これらの3つは、ハーブ療法の一般的な成分です。 oleandrinの源はオウバイ(Nerium oleander)で、心不全や特定の不整脈(不整脈)の治療に使用される心臓薬digoxinと同等の効果を持つ物質です。oleandrinには抗がん、抗炎症、抗HIV、抗菌、抗酸化作用が観察されています。人間におけるoleandrinの治療的窓は狭く、治療用量を超えると高度に毒性があるため、食品添加物や医薬品としての販売や使用は違法です。 Linkedinもoleandrinと同様に、がん、炎症、微生物、神経系に対して有益な効果があり、抗酸化作用や神経保護特性があります。銀杏(Ginkgo biloba)は最も古い生きている樹種であり、その葉と種子は中国で数千年間、漢方薬として使用されています。この木はLinkedinの源です。この木の乾燥した葉を使用して処方箋なしで販売される銀杏エキスが作られています。これは、米国やヨーロッパでトップセラーのハーブサプリメントです。 研究者らは、彼らの結果が、以前の研究で特定されたsenolyticよりも同等またはそれ以上に効果的であることを示していると主張しています。彼らの機械学習ベースのアプローチは、製薬業界での通常のAIの使用とは異なるいくつかの新しい機能を備えています。 第1に、モデルトレーニングに公開されたデータのみを使用するため、内部でのトレーニング化合物の実験的な特性の追加費用は必要ありません。 第2に、senolysisは稀な分子特性であり、文献に報告されているsenolyticは少ないため、機械学習モデルは、通常はこの分野で考慮されるよりもはるかに小さなデータセットでトレーニングされました。この方法の効果は、文献データが通常予想されるよりも多様で限定的であるにもかかわらず、機械学習が文献データを最大限に活用できることを示しています。 第3に、標的非依存モデルトレーニングで薬理学的活性の表現型指標が使用されました。多くの状態は、重要な経済的および社会的負担を負っていますが、それらの状態のためには、少数またはまったくターゲットが知られていないため、表現型薬剤探索は、発見パイプラインを通じて進展する可能性のある化学の出発点の数を拡大する機会を提供します。

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…

音から視覚へ:音声から画像を合成するAudioTokenについて
ニューラル生成モデルは、私たちがデジタルコンテンツを消費する方法を変え、さまざまな側面を革命化しています。彼らは高品質の画像を生成し、長いテキストスパンでの一貫性を確保し、音声やオーディオを生成する能力を持っています。異なるアプローチの中でも、拡散ベースの生成モデルは注目を集め、さまざまなタスクで有望な結果を示しています。 拡散プロセス中、モデルは定義済みのノイズ分布を目標データ分布にマップする方法を学習します。各ステップで、モデルはノイズを予測し、目標分布から信号を生成します。拡散モデルは、生の入力や潜在表現など、さまざまな形式のデータ表現で動作できます。 Stable Diffusion、DALLE、Midjourneyなどの最先端のモデルは、テキストから画像合成のタスクに対して開発されています。最近ではX-to-Y生成に対する関心が高まっていますが、オーディオから画像へのモデルはまだ深く探究されていません。 テキストプロンプトではなくオーディオ信号を使用する理由は、動画のコンテキストでの画像と音声の相互接続にあります。一方、テキストベースの生成モデルは優れた画像を生成できますが、テキストの説明は画像と本質的に関連していません。つまり、テキストの説明は通常手動で追加されます。また、オーディオ信号には、同じ楽器の異なるバリエーション(例:クラシックギター、アコースティックギター、エレキギターなど)や、同一のオブジェクトの異なる視点(例:スタジオで録音されたクラシックギターとライブショーでのクラシックギター)など、複雑なシーンやオブジェクトを表す能力があります。異なるオブジェクトのこのような詳細な情報の手動注釈は労力がかかり、拡張性が低下するため、スケーラビリティに課題があります。 以前の研究では、主にGANを使用してオーディオ録音に基づいて画像を生成することに焦点を当てた方法が提案されています。ただし、彼らの作業と提案された方法の間には顕著な違いがあります。一部の方法では、MNIST数字の生成にのみ焦点を当て、一般的なオーディオサウンドを包括するアプローチには拡張しませんでした。その他の方法では、一般的なオーディオから画像を生成しましたが、低品質の画像に結果が出たものもありました。 これらの研究の制限を克服するために、オーディオから画像を生成するためのDLモデルが提案されました。その概要は、以下の図に示されています。 このアプローチは、事前にトレーニングされたテキストから画像を生成するモデルと、事前にトレーニングされたオーディオ表現モデルを活用して、それらの出力と入力の間の適応層マッピングを学習することを含みます。最近のテキスト反転の研究から、専用のオーディオトークンが導入され、オーディオ表現が埋め込みベクトルにマップされます。このベクトルは、新しい単語埋め込みを反映する連続表現として、ネットワークに転送されます。 オーディオエンベッダーは、事前トレーニングされたオーディオ分類ネットワークを使用して、オーディオの表現をキャプチャします。通常、識別的ネットワークの最後の層が分類目的に使用されますが、識別的なタスクとは関係のない重要なオーディオの詳細を見落とすことがよくあります。そのため、このアプローチでは、最後の隠れ層と以前の層を組み合わせて、オーディオ信号の時間埋め込みを生成します。 提供されたモデルによって生成されたサンプル結果は、以下に報告されています。 これが、新しいオーディオから画像(A2I)合成モデルであるAudioTokenの概要でした。興味がある場合は、以下のリンクでこの技術についてもっと学ぶことができます。

2023年の製品マネージャーにとって最高のAIツール
AI市場の急速な拡大は、製品マネージャーの生産性向上に加えて、新しい職種の出現を促進する可能性があることに多くの人々が驚嘆しています。しかし、数千ものツールがアクセス可能で、毎週さらに多くのツールが登場すると、圧倒されてしまうことが簡単です。 ClickUp ClickUpは、あらゆる規模やセクターのチーム間のコミュニケーションを促進するオールインワンのプロジェクト管理ツールです。製品の作成や計画などのタスクに対して、使いやすく、適応性が高いため、製品管理の解決策として、ClickUpは主要な位置を占めています。多数のプレメイドの製品チームテンプレートを備えた高度に柔軟なプラットフォームであり、ClickUpの適応性と有用なツールにより、どのチームでもプラットフォームを自分たちのニーズやワークフローのニュアンスに合わせてカスタマイズできます。 Jam JamGPTは、製品マネージャーが問題を理解し、エンジニアリングチームに伝えることができる潜在的な修正箇所を見つけるのを支援する最新のAIツールです。生産性が向上し、技術的な議論にアクセスできるようになります。製品マネージャーが非技術的な背景でもコンテキストを提供できるJamGPTの容量は、各レベルでの機能の展開を容易にするものです。ClickUp、Slack、またはGithubなどのプロジェクト管理ツールに、インテリジェントなAIアシスタントと主要なバグレポート機能で収集された貴重なデータを統合することで、製品の改善の共有と作業がスムーズになります。 Motion Motionは、AIを利用して、ミーティング、タスク、プロジェクトを考慮した日々のスケジュールを作成する賢明なツールです。計画の手間を省いて、より生産的な生活を始めましょう。 ChatGPT ほとんどの質問に適切な回答を提供することで、検索エンジンクエリーよりも優れた体験を製品マネージャーに提供することで、ChatGPTは最も人気のある自然言語処理(NLP)ツールの1つになりました。製品マネージャーが行ったテストでは、結果は彼らが尋ねた質問に敏感であることが示されました。 ChatGPTの適応性は、主要なセールスポイントです。製品の成長、顧客サービスなどを向上させるためにユニークな質問に回答することができます。製品マネージャーにとって役立つため、提出されたデータを分析して顧客の痛点を特定し、次に開発する製品のアイデアを提供し、感情分析を実行することができます。 Canva Canvaの無料の画像ジェネレーターは、製品マネージャーの日々の業務にどれだけ役立つかを簡単に確認できます。ステークホルダーミーティング、製品ローンチなどでプレゼンテーションやデッキに使用する適切なビジュアルを見つけることは常に難しかったです。しばしば、望むものを明確に心に描いているのに、利用可能なストック写真を修正する必要があります。CanvaのAI駆動エディタを使用すると、トピックをブレインストーミングし、入力に基づいて理想のビジュアルを見つけるための検索結果を微調整できます。 TLDV 正直に言いますと、製品マネージャーとしてのあなたの時間の多くはミーティングに費やされます。ステークホルダーに新しい製品機能を提示したり、エンジニアリングチームにそれを販売しようとしたりする場合には、強力なプレゼンテーションが不可欠です。TLDVは、ミーティングのノートを取り、それらを箇条書きにまとめて、より生産的になるためのAIプログラムです。ユーザーとのインタビューで最大限に活用するには、ノートを取ることに心を配る必要があります。TLDVは、そのような問題を解決します。 Notion 最も人気のあるノートアプリの1つであるNotionは、最新のAI機能でアップグレードされました。これにより、製品マネージャーは、ビジネスウィキや製品ロードマップを確立するための能力の高い人工知能の支援を受け、コミュニケーションを改善し、要約などの繰り返しの作業にかかる時間を削減することができます。 Otter.AI Otter.aiは、会議や議論を正確に記録し、転写するAI駆動プラットフォームです。AIを活用して、会話を瞬時に転写し、検索可能でアクセス可能で暗号化されたメモを簡単に共有できるようにします。 Otterは、自動的にZoom、Microsoft Teams、Google Meetミーティングに参加して録音することができます。キーポイントが強調され、タスクが割り当てられ、簡単に共有および呼び出せる要約が生成されます。ビジネス、教育、個人設定のユーザーが、iOS、Android、Chromeで時間を節約するのに役立つと感じています。多くのユーザーは、その精度、多様性(さまざまなスピーカーから転写できる)、時間を節約する自動スライドキャプチャ機能を称賛しています。 Collato あなたのチームが生成した書類の山から特定の製品情報を追跡できないですか?Collatoは、チームの人々が必要とする情報を追跡し、クリックひとつで簡単に利用できるようにする人工知能アシスタントです。製品マネージャーは、様々な技術をシングルビジュアルマップに同期し、統合することにより、情報のサイロを減らすことができます。製品ロードマップの重要な文書が紛失した際に毎回30分を無駄にする代わりに、必要なすべての情報に簡単にアクセスできるようになります。 Midjourney…

新たな能力が明らかに:GPT-4のような成熟したAIのみが自己改善できるのか?言語モデルの自律的成長の影響を探る
研究者たちは、AlphaGo Zeroと同様に、明確に定義されたルールで競争的なゲームに反復的に参加することによってAIエージェントが自己発展する場合、多くの大規模言語モデル(LLM)が人間の関与がほとんどない交渉ゲームでお互いを高め合う可能性があるかどうかを調査しています。この研究の結果は、遠い影響を与えるでしょう。エージェントが独立に進歩できる場合、少数の人間の注釈で強力なエージェントを構築することができるため、今日のデータに飢えたLLMトレーニングに対して対照的です。それはまた、人間の監視がほとんどない強力なエージェントを示唆しており、問題があります。この研究では、エジンバラ大学とAIアレン研究所の研究者が、顧客と売り手の2つの言語モデルを招待して購入の交渉を行うようにしています。 図1:交渉ゲームの設定。彼らは2つのLLMエージェントを招待して、値切りのゲームで売り手と買い手をプレイさせます。彼らの目標は、より高い値段で製品を販売または購入することです。彼らは第三のLLMであるAI批評家に、ラウンド後に向上させたいプレイヤーを指定してもらいます。その後、批判に基づいて交渉戦術を調整するようにプレイヤーに促します。これを数ラウンド繰り返すことで、モデルがどんどん上達するかどうかを確認します。 顧客は製品の価格を下げたいと思っていますが、売り手はより高い価格で販売するように求められています(図1)。彼らは第三の言語モデルに批評家の役割を担ってもらい、取引が成立した後にプレイヤーにコメントを提供させます。次に、批評家LLMからのAI入力を利用して、再度ゲームをプレイし、プレイヤーにアプローチを改善するように促します。彼らは交渉ゲームを選んだ理由は、明確に定義されたルールと、戦術的な交渉のための特定の数量化目標(より低い/高い契約価格)があるためです。ゲームは最初は単純に見えますが、モデルは次の能力を持っている必要があります。 交渉ゲームのテキストルールを明確に理解し、厳密に遵守すること。 批評家LLMによって提供されるテキストフィードバックに対応し、反復的に改善すること。 長期的にストラテジーとフィードバックを反映し、複数のラウンドで改善すること。 彼らの実験では、モデルget-3.5-turbo、get-4、およびClaude-v1.3のみが交渉ルールと戦略を理解し、AIの指示に適切に合致している必要があるという要件を満たしています。その結果、彼らが考慮したモデルすべてがこれらの能力を示さなかったことが示されています(図2)。初めに、彼らはボードゲームやテキストベースのロールプレイングゲームなど、より複雑なテキストゲームもテストしましたが、エージェントがルールを理解して遵守することがより困難であることが判明しました。彼らの方法はICL-AIF(AIフィードバックからのコンテキスト学習)として知られています。 図2:私たちのゲームで必要な能力に基づいて、モデルは複数の階層に分けられます(C2-交渉、C3-AIフィードバック、C4-継続的な改善)。私たちの研究は、gpt-4やclaude-v1.3などの堅牢で適切に合致したモデルだけが反復的なAI入力から利益を得て、常に発展することができることを明らかにしています。 彼らは、AI批評家のコメントと前回の対話履歴ラウンドをコンテキストに応じたデモンストレーションとして利用しています。これにより、プレイヤーの前回の実際の開発と批評家の変更アイデアが、次のラウンドの交渉のためのフューショットキューに変換されます。2つの理由から、彼らはコンテキストでの学習を使用しています:(1)強化学習を用いた大規模な言語モデルの微調整は、高額であるため、(2)コンテキストでの学習は、勾配降下に密接に関連していることが最近示されたため、モデルの微調整を行う場合には、彼らが引き出す結論がかなり一般的になることが期待されます(資源が許される場合)。 人間からのフィードバックによる強化学習(RLHF)の報酬は通常スカラーですが、ICL-AIFでは、フィードバックが自然言語で提供されます。これは、2つのアプローチの注目すべき違いです。各ラウンド後に人間の相互作用に依存する代わりに、よりスケーラブルでモデルの進歩に役立つAIのフィードバックを検討しています。 異なる責任を負うときにフィードバックを与えられた場合、モデルは異なる反応を示します。バイヤー役のモデルを改善することは、ベンダー役のモデルよりも難しい場合があります。過去の知識とオンライン反復的なAIフィードバックを利用して、get-4のような強力なエージェントが常に意味のある開発を続けることができるとしても、何かをより高く売る(またはより少ないお金で何かを購入する)ことは、全く取引が成立しないリスクがあります。彼らはまた、モデルがより簡潔であるがより綿密(そして最終的にはより成功する)交渉に従事できることを証明しています。全体的に、彼らは自分たちの仕事がAIフィードバックのゲーム環境での言語モデルの交渉を向上させる重要な一歩になると期待しています。コードはGitHubで利用可能です。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.