Learn more about Search Results Ford - Page 26

- You may be interested
- 無料のオープンパスでODSC West Virtualに...
- 「大規模な言語モデルを使用した生成型AI...
- ニューヨーク市がAIに照準を合わせる
- 複数の時間軸での予測 天気データの例
- デジタルアイデンティティを保護する方法
- 『RAG パイプラインの落とし穴: 「テーブ...
- 『究極の没入型視覚化とモデリング体験を...
- 「時系列データにおける複数の季節性をモ...
- 「ChatGPT 3.5 Turboの微調整方法」
- 「ESGレポーティングとは何ですか?」
- 「iOSのための10の最高のデータ復旧ツール...
- タイムズネット:時系列予測の最新の進歩
- より良いOCRパフォーマンスを得るためのEa...
- 我々はまもなく独自のパーソナルAIムービ...
- 「Llama2とAmazon SageMakerを使用したLoR...

PyTorchを使った効率的な画像セグメンテーション:Part 2
これは、PyTorchを使用してディープラーニング技術を使ってゼロから画像セグメンテーションをステップバイステップで実装する4部作シリーズの第2部ですこの部分では、ベースライン画像の実装に焦点を当てます...
PyTorchを使用した効率的な画像セグメンテーション:Part 4
この4部構成のシリーズでは、PyTorchを使用した深層学習技術を使って、画像セグメンテーションをゼロからステップバイステップで実装しますこのパートでは、Vision Transformerをベースとしたモデルの実装に焦点を当てます

スタンフォード大学、コーネル大学、オックスフォード大学の新しいAI研究は、単一の画像のわずかなインスタンスからオブジェクトの固有性を発見する生成モデルを紹介しています
バラの本質は、その独特の形状、質感、および材料組成で構成されています。これを使用して、さまざまな位置で、さまざまな形状のバラをさまざまな照明効果で作成できます。各バラが独自のピクセル値セットを持っていても、それらを同じクラスのメンバーとして識別できます。 Stanford、Oxford、およびCornell Techの研究者たちは、単一の写真からのデータを使用して、異なる視点と照明から新しい形状と画像を生成できるモデルを作成することを望んでいます。 この問題を解決するためには、3つの障壁があります: トレーニングデータセットには1枚の画像しかなく、数百のインスタンスしかありません。 これらの数少ない状況には、幅広い可能なピクセル値があります。これは、姿勢も照明条件も記録されていないか、または不明であるためです。 どのバラも同じではなく、形状、質感、材料の分布をキャプチャする必要があります。したがって、推論されるオブジェクト固有量は確定的ではなく、確率的です。これは、静的なオブジェクトやシーンに対する現在のマルチビュー再構成またはニューラルレンダリングアプローチと比較して、重要な変更です。 提案されたアプローチは、モデル作成にバイアスを誘導するためにオブジェクト固有量を出発点としています。これらのルールには2つの部分があります: 提示されるインスタンスはすべて、同じオブジェクト固有量またはジオメトリ、質感、材料の分布を持つ必要があります。 固有の特性は、レンダリングエンジンによって定義され、最終的には物理世界によって定義された特定の方法で相互に関連しています。 より具体的には、彼らのモデルは、単一の入力画像を取り、インスタンスマスクのコレクションとインスタンスの特定のポーズ分布を使用して、オブジェクトの3D形状、表面反射率、および艶の分布のニューラル表現を学習し、姿勢と照明の変動の影響を排除します。この物理的に基礎づけられた明示的な分離は、彼らのインスタンスの簡単な説明を支援します。モデルは、単一の画像によって提供される疎な観測に過剰適合することなく、オブジェクト固有量を取得することができます。 研究者たちが言及するように、その結果得られたモデルによって、多くの異なる用途が可能になります。たとえば、学習されたオブジェクト固有量からランダムにサンプリングすることで、異なるアイデンティティを持つ新しいインスタンスを生成できます。外部要素を調整して、新しいカメラ角度や照明セットアップで合成インスタンスを再レンダリングすることができます。 チームは、モデルの改良された形状再構成と生成性能、革新的なビュー合成、およびリライト性能を示すために、徹底的なテストを実施しました。

BITEとは 1枚の画像から立ち姿や寝そべりのようなポーズなど、困難なポーズでも3D犬の形状とポーズを再構築する新しい手法
生物学や保全、エンターテインメントや仮想コンテンツの開発など、多くの分野で3D動物の形状や態度を捕捉してモデリングすることは有益です。動物を静止させたり、特定の姿勢を維持したり、観察者と物理的接触をしたり、協力的な何かをする必要はないため、カメラは動物を観察するための自然なセンサーです。Muybridge氏による有名な「馬の運動」の連続写真のように、写真を使用して動物を研究する歴史は長いです。しかし、以前の3D人間の形状や態度に関する研究とは異なり、最近では動物の独特な形状と位置に変化できる表現豊かな3Dモデルが開発されています。ここでは、単一の写真から3D犬再構築の課題に焦点を当てます。 犬は、四肢のような関節の変形が強く、品種間の広い形状変化があるため、モデル種として選ばれます。犬は定期的にカメラに捉えられます。したがって、様々な姿勢、形状、および状況が簡単に利用できます。人と犬をモデリングすることには同様の困難があるかもしれませんが、それらは非常に異なる技術的障壁を持っています。多くの3Dスキャンとモーションキャプチャデータがすでに利用可能であり、SMPLやGHUMのような堅牢な関節モデルを学習することが可能になっています。 それに対して、動物の3D観察を収集することは困難であり、現在は、すべての想定される形状と位置を考慮に入れた同様に表現豊かな3D統計モデルを学習するためにより多くのデータが必要です。SMALは、おもちゃのフィギュアから学習された、四足動物のパラメトリックモデルであり、犬を含む動物を写真から3Dで再現することが現在可能になりました。しかし、SMALは、猫からカバまで多くの種に対して一般的なモデルであり、さまざまな動物の多様な体型を描写できますが、大きな耳の範囲などの犬の品種の独特で微細な詳細を描写することはできません。この問題を解決するために、ETH Zurich、Max Planck Institute for Intelligent Systems、Germany、IMATI-CNR、Italyの研究者たちは、正しく犬を表現する最初のD-SMALパラメトリックモデルを提供しています。 また、人と比較して、犬は比較的少量のモーションキャプチャデータしか持っておらず、そのデータのうち座ったり寝そべったりする姿勢はめったにキャプチャされません。そのため、現在のアルゴリズムでは、特定の姿勢で犬を推測することが困難です。たとえば、歴史的データから3Dポーズの事前に学習すると、立ち上がったり歩いたりする姿勢に偏ってしまいます。一般的な制約を使用することで、この事前情報を弱めることができますが、ポーズの推定は非常に未解決となります。この問題を解決するために、彼らは、(地形)動物をモデリングする際に見落とされていた物理的タッチに関する情報を利用しています。つまり、重力の影響を受けるため、地面に立ったり、座ったり、寝転がったりすることができます。 複雑な自己遮蔽のある困難な状況では、彼らは地面接触情報を使用して複雑な犬のポーズを推定する方法を示しています。人間のポーズ推定において地面面制限が使用されてきましたが、四足動物にとっては潜在的な利点が大きいです。四本足は、より多くの地面接触点、座ったり寝そべったりしたときにより多くの体部位が隠れ、より大きな非剛体変形を示唆しています。以前の研究のもう一つの欠点は、再構築パイプラインがしばしば2D画像で訓練されていることです。対応する2D画像と共に3Dデータを収集することは困難です。そのため、再投影すると視覚的証拠に近くなりますが、視野方向に沿って歪んでいる位置や形状を予測することがあります。 異なる角度から見ると、3D再構築が誤った場合があります。対応するデータがないため、遠くまたは隠れた体の部分をどこに配置すべきかを決定するための十分な情報がないためです。彼らは再び、地面接触のシミュレーションが有益であることを発見しました。結合された2Dと3Dデータを手動で再構築(または合成)する代わりに、より緩い3D監視方法に切り替えて、地面接触ラベルを取得します。アノテーターには、犬の下の地面が平らかどうかを指示し、平らである場合は3D動物の地面接触点を追加で注釈するように求めます。これは、アノテーターに実際の写真を提示することで実現されます。 図1 は、BITEが単一の入力画像から犬の3D形状と姿勢を推定できるようになったことを示しています。このモデルは、様々な品種やタイプ、そして訓練ポーズの範囲外である困難なポーズ、たとえば地面に座ったり寝そべったりすることができます。 彼らは、単一の画像から表面を分類し、接点をかなり正確に検出するようにネットワークを教育できることがわかりました。これらのラベルはトレーニングだけでなく、テスト時にも使用できます。最新の最先端モデルであるBARCに基づいて、再構築システムはBITEと呼ばれています。彼らは、新しいD-SMAL犬モデルを初期の荒い適合ステップとして使用してBARCを再トレーニングします。その後、結果の予測を最近作成したリファインメントネットワークに送信し、接地損失を使用してカメラの設定と犬のスタンスの両方を改善するためにトレーニングします。テスト時にも接地損失を使用して、テスト画像に完全に自律的に適合を最適化することができます(図1を参照)。これにより、再構築の品質が大幅に向上します。BARCポーズ事前に対するトレーニングセットにそのようなポーズが含まれていなくても、BITEを使用して(局所的に平面的な)地面に正しく立つ犬を取得したり、座ったり横たわったりといった姿勢で現実的に再構築したりすることができます。3D犬再構築に関する先行研究は、主観的な視覚評価または写真に戻って2D残差を評価することによって評価されており、深度に関連する不正確さを投影しています。彼らは、客観的な3D評価の欠如を克服するために、実際の犬をさまざまな視点から3Dスキャンして、3D真実値を持つ半合成データセットを開発しました。彼らは、この新しいデータセットを使用して、BITEとその主要な競合他社を評価し、BITEがこの分野の新しい標準を確立することを示しています。 彼らの貢献の要約は以下の通りです: 1. SMALから開発された、新しい、犬種固有の3DポストureおよびフォームモデルであるD-SMALを提供します。 2.同時に地面の局所平面を評価するためのニューラルモデルであるBITEを作成します。BITEは、信じられる地面接触を促進します。 3.モデルを使用する前に、(必然的に小さい)先行モデルでエンコードされたものとは非常に異なる犬の位置を回復することが可能であることを示します。 4. StanfordExtraデータセットを使用して、単眼カメラによる3Dポストure推定の最先端を改善します。 5.実際の犬のスキャンに基づく半合成3Dテストコレクションを提供し、真の3D評価への移行を促進します。

大規模言語モデルに関するより多くの無料コース
大規模言語モデルについて学びたいですか? DeepLearning.AI、Google Cloud、Udacityなどの無料のコースで、すぐに始めましょう
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...

RedPajamaプロジェクト:LLMの民主化を目指すオープンソースイニシアチブ
アクセス可能な大規模言語モデルを通じてコミュニティを強化するプロジェクトのリーダーシップを担っています
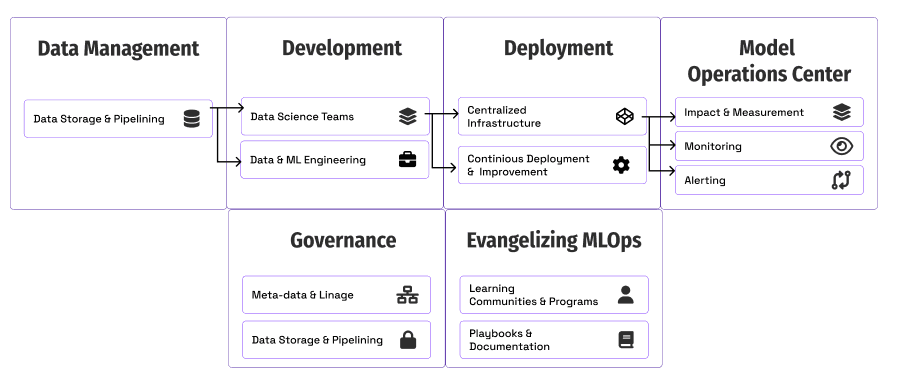
MLOpsを拡張するためのプレイブック
MLOpsチームは、AIを拡大するための能力を向上させるように圧力を受けています私たちはフォード・モーターと協力して、組織内でMLOpsを拡大する方法や、どのように始めるかを探ることにしました
あなたの究極のチャットGPTおよびその他の略語ガイド
ChatGPTについて、誰もが熱狂しているようですこれは文化現象になりましたまだChatGPTの利用者でない場合、この記事はこの革新に対する文脈と興奮をよりよく理解するのに役立つかもしれません
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.