Learn more about Search Results 同期 - Page 26

- You may be interested
- 自動チケットトライアジによる顧客サポー...
- 音声合成、音声認識、そしてSpeechT5を使...
- 中国の研究者たちは、複雑な現実世界の課...
- 「スパースなデータセットの扱い方に関す...
- 「教科書で学ぶ教師なし学習:K-Meansクラ...
- 「カーンアカデミーがジェネラティブAI学...
- 「WavJourneyをご紹介します:大規模な言...
- 「データサイエンスは循環経済をどのよう...
- 「データ分析での創発的AIの解放」
- 「このAI論文は、超人的な数学システムの...
- 「検索強化生成(RAG) 理論からLangChain...
- ソウル国立大学の研究者たちは、ディフュ...
- このAI論文は、「MATLABER:マテリアルを...
- LoftQをご紹介します:大規模言語モデルの...
- より良いOCRパフォーマンスを得るためのEa...

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

人間のフィードバックからの強化学習(RLHF)の説明
この記事は以下の言語に翻訳されています:中国語(簡体字)とベトナム語。他の言語に翻訳に興味がありますか?nathan at huggingface.co までお問い合わせください。 言語モデルは、過去数年間に人間の入力プロンプトから多様で魅力的なテキストを生成する能力を示してきました。しかし、「良い」テキストとは何かは、主観的で文脈に依存するため、本質的に定義するのは難しいです。創造性を求める物語の執筆などの多くのアプリケーションでは、真実であるべき情報の断片、または実行可能なコードのスニペットなどが必要です。 これらの属性を捉えるための損失関数を作成することは困難であり、ほとんどの言語モデルはまだ単純な次のトークン予測の損失(例:クロスエントロピー)で訓練されています。損失自体の欠点を補うために、人々はBLEUやROUGEなど、人間の優先順位をより適切に捉えるように設計されたメトリクスを定義しています。これらのメトリクスは、パフォーマンスを測定する上で損失関数自体より適しているものの、生成されたテキストを単純なルールで参照テキストと比較するだけなので、制約もあります。生成されたテキストに対する人間のフィードバックをパフォーマンスの指標として使用するか、さらに進んでそのフィードバックを損失としてモデルを最適化することができれば、素晴らしいことではないでしょうか?それが「人間のフィードバックによる強化学習(RLHF)」のアイデアです。強化学習の手法を使用して、言語モデルを人間のフィードバックで直接最適化するのです。RLHFにより、言語モデルは一般的なテキストデータのコーパスで訓練されたモデルを複雑な人間の価値に合わせることができるようになりました。 RLHFの最近の成功例は、ChatGPTでの使用です。ChatGPTの印象的な能力を考慮して、RLHFについて説明してもらいました: それは驚くほどうまくいっていますが、すべてをカバーしているわけではありません。それらのギャップを埋めましょう! 人間のフィードバックによる強化学習(RL from human preferencesとも呼ばれます)は、複数のモデルのトレーニングプロセスと異なる展開の段階を伴うため、難しい概念です。このブログ記事では、トレーニングプロセスを次の3つの主要なステップに分解します: 言語モデル(LM)の事前トレーニング データの収集と報酬モデルのトレーニング 強化学習によるLMの微調整 まず、言語モデルの事前トレーニングについて見ていきましょう。 言語モデルの事前トレーニング RLHFの出発点として、クラシカルな事前トレーニング目標で既に事前トレーニングされた言語モデルを使用します(詳細については、このブログ記事を参照してください)。OpenAIは、最初の人気のあるRLHFモデルであるInstructGPTに対して、より小さなバージョンのGPT-3を使用しました。Anthropicは、このタスクのためにトレーニングされた1,000万から520億のパラメータを持つトランスフォーマーモデルを使用しました。DeepMindは、2800億のパラメータモデルGopherを使用しました。 この初期モデルは、追加のテキストや条件で微調整することもできますが、必ずしも必要ではありません。たとえば、OpenAIは「好ましい」とされる人間が生成したテキストを微調整し、Anthropicは彼らの「助けになり、正直で無害な」基準に基づいて元のLMを蒸留することで、RLHFのための初期LMを生成しました。これらは共に、私が高価な増強データと呼ぶものの一部ですが、RLHFを理解するために必要なテクニックではありません。 一般的に、「どのモデル」がRLHFの出発点として最適かは明確な答えがありません。このブログ記事では、RLHFのトレーニングにおけるオプションの設計空間が完全に探索されていないという共通のテーマになります。 次に、言語モデルが必要なデータを生成して、人間の優先順位がシステムに統合される「報酬モデル」をトレーニングする必要があります。 報酬モデルのトレーニング 人間の優先順位に合わせてキャリブレーションされた報酬モデル(RM、優先モデルとも呼ばれます)を生成することは、RLHFの比較的新しい研究の出発点です。その基本的な目標は、テキストのシーケンスを受け取り、数値で人間の優先順位を表すべきスカラー報酬を返すモデルまたはシステムを取得することです。システムはエンドツーエンドのLMであるか、報酬を出力するモジュラーシステム(例:モデルが出力をランク付けし、ランキングが報酬に変換される)である場合があります。出力がスカラーの報酬であることは、既存のRLアルゴリズムが後のRLHFプロセスにシームレスに統合されるために重要です。 報酬モデリングのためのこれらの言語モデルは、別の微調整された言語モデルまたは好みのデータでスクラッチからトレーニングされた言語モデルのいずれかです。例えば、Anthropicは、これらのモデルを事前トレーニング(好みモデルの事前トレーニング、PMP)の後に初期化するために専門の微調整方法を使用しています。彼らは、これが微調整よりもサンプル効率が高いと結論付けましたが、報酬モデリングのバリエーションの中で明確な最良の選択肢はありません。…

🤗 Transformersを使用してTensorFlowとTPUで言語モデルをトレーニングする
イントロダクション TPUトレーニングは有用なスキルです:TPUポッドは高性能で非常にスケーラブルであり、数千万から数百億のパラメータまで、どんなスケールでもモデルをトレーニングすることが容易です。GoogleのPaLMモデル(5000億パラメータ以上!)は完全にTPUポッドでトレーニングされました。 以前、TensorFlowを使用した小規模なTPUトレーニングと、TPUでモデルを動作させるために理解する必要がある基本的なコンセプトを紹介するチュートリアルとColabの例を作成しました。今回は、TensorFlowとTPUを使用してマスクされた言語モデルをゼロからトレーニングするためのすべての手順、トークナイザのトレーニングとデータセットの準備から最終的なモデルのトレーニングとアップロードまでを詳しく説明します。これはColabだけでなく、専用のTPUノード(またはVM)が必要なタスクであり、そこに焦点を当てます。 Colabの例と同様に、TensorFlowの非常にクリーンなTPUサポートであるXLAとTPUStrategyを活用しています。また、🤗 Transformers内のほとんどのTensorFlowモデルが完全にXLA互換であるという利点もあります。そのため、TPU上で実行するために必要な作業はほとんどありません。 ただし、この例はColabの例とは異なり、実際のトレーニングランに近いスケーラブルな例です。デフォルトではBERTサイズのモデルしか使用していませんが、いくつかの設定オプションを変更することで、コードをより大きなモデルとより強力なTPUポッドスライスに拡張することができます。 動機 なぜ今このガイドを書いているのでしょうか?実際、🤗 Transformersは何年もの間TensorFlowをサポートしてきましたが、これらのモデルをTPUでトレーニングすることはコミュニティにとって主要な問題でした。これは以下の理由によるものです: 多くのモデルがXLA互換ではなかった データコレクターがネイティブのTF操作を使用していなかった 私たちはXLAが将来の技術であると考えています。それはJAXのコアコンパイラであり、TensorFlowでの一流のサポートを受けており、PyTorchからも使用できます。そのため、私たちはコードベースをXLA互換にするために大きな取り組みを行い、XLAとTPUの互換性に立ちはだかるその他の障害を取り除きました。これにより、ユーザーは私たちのほとんどのTensorFlowモデルをTPUで煩わずにトレーニングできるはずです。 現在のLLM(言語モデル)と生成AIの最近の重要な進歩により、モデルのトレーニングに対する一般の関心が高まり、最新のGPUにアクセスすることが非常に困難になりました。TPUでのトレーニング方法を知っていると、超高性能な計算ハードウェアへのアクセスする別の方法を手に入れることができます。それは、eBayで最後のH100の入札戦に敗れてデスクで醜い泣きをするよりもずっと品位があります。あなたにはもっと良いものがふさわしいのです。そして経験から言えることですが、TPUでのトレーニングに慣れると、戻りたくなくなるかもしれません。 予想されること WikiTextデータセット(v1)を使用してRoBERTa(ベースモデル)をゼロからトレーニングします。モデルのトレーニングだけでなく、トークナイザをトレーニングし、データをトークン化してTFRecord形式でGoogle Cloud Storageにアップロードし、TPUトレーニングでアクセスできるようにします。コードはこのディレクトリにあります。ある種の人にとっては、このブログ投稿の残りをスキップして、コードに直接ジャンプすることもできます。ただし、しばらくお付き合いいただければ、コードベースのいくつかのキーポイントについて詳しく見ていきます。 ここで紹介するアイデアの多くは、私たちのColabの例でも触れられていましたが、それらをすべて組み合わせて実際に動作するフルエンドツーエンドの例をユーザーに示したかったのです。次の図は、🤗 Transformersを使用した言語モデルのトレーニングに関わる手順の概要を図解したものです。TensorFlowとTPUを使用しています。 データの取得とトークナイザのトレーニング 先述のように、WikiTextデータセット(v1)を使用しました。データセットの詳細については、Hugging Face Hubのデータセットページにアクセスして調べることができます。 データセットは既に互換性のある形式でHubに利用可能なので、🤗 datasetsを使用して簡単にロードして操作することができます。ただし、この例ではトークナイザをゼロから学習しているため、以下のような手順を踏んでいます:…
Hugging Face Unity APIのインストールと使用方法
Hugging Face Unity APIは、Hugging Face Inference APIの簡単に使用できる統合です。これにより、開発者はUnityプロジェクトでHugging Face AIモデルにアクセスして使用することができます。このブログ投稿では、Hugging Face Unity APIのインストールと使用方法について説明します。 インストール Unityプロジェクトを開きます Window -> Package Managerに移動します +をクリックし、Add Package from git URLを選択します https://github.com/huggingface/unity-api.gitを入力します…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…
実験追跡ツールの構築方法[Neptuneのエンジニアの学びから]
あなたのチームのMLOpsエンジニアとして、よくMLプラットフォームに機能を追加したり、データサイエンティストが利用するためのスタンドアロンツールを構築することで、彼らのワークフローを改善するように依頼されることがあります実験トラッキングはそのような機能の一つですそして、この記事を読んでいるのであれば、あなたがサポートしているデータサイエンティストはおそらく...

CVモデルの構築と展開:コンピュータビジョンエンジニアからの教訓
コンピュータビジョン(CV)モデルの設計、構築、展開の経験を3年以上積んできましたが、私は人々がこのような複雑なシステムの構築と展開において重要な側面に十分な注力をしていないことに気づきましたこのブログ投稿では、私自身の経験と、最先端のCVモデルの設計、構築、展開において得た貴重な知見を共有します...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...
.jpg)
好奇心だけで十分なのか? 好奇心による探索からの新たな振る舞いの有用性について
私たちは、単に好奇心を使って環境を探索したり特定のタスクのボーナス報酬として使用するだけでは、この技術の全ポテンシャルを引き出すことはできず、有用なスキルを見逃してしまいます代わりに、私たちは好奇心に基づく学習中に現れる行動を保持することに焦点を当てることを提案しますこれらの自己発見された行動は、関連するタスクを解決するためのエージェントのレパートリーとして有用なスキルを持っていると考えています
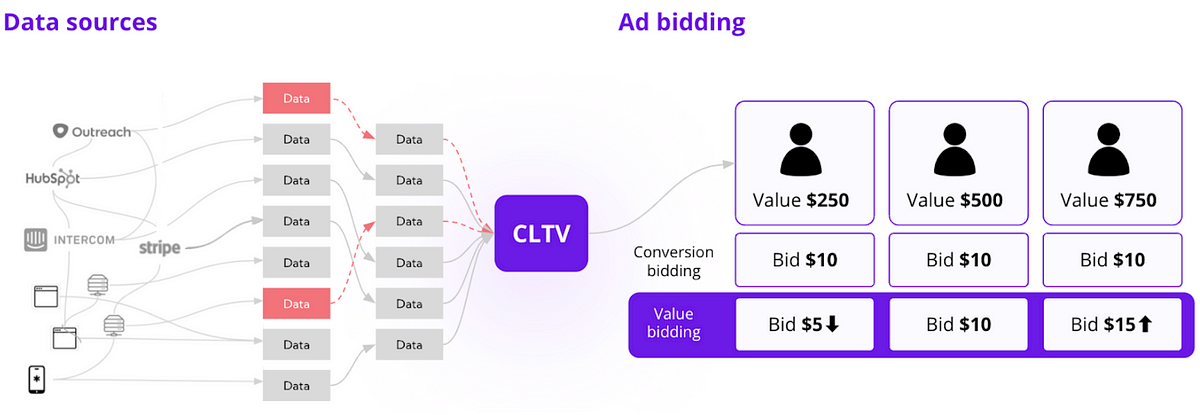
広告費用の収益率におけるデータ品質の問題の隠れたコスト
あなたのデータには、銀行口座になる顧客とならない顧客について多くの情報がありますB2B企業でライフサイクルマーケティングマネージャーとして働いているかどうかに関係なく、それは事実です
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.