Learn more about Search Results - Page 26

- You may be interested
- AI カリキュラムの日が今こそ必要な時に会う
- 「シリコンバレーの大胆なSFの賭け:スマ...
- 「ランバード効果と聴覚障害への役立ち方」
- 「昨年のハイライトでODSC West 2023に向...
- 人間の嗅覚とAIが匂いの命名で競い合う
- GPT – 直感的かつ徹底的な解説
- 教育のためのHugging Faceをご紹介します 🤗
- なぜ便利なソフトウェアを書くのはいつも...
- Optimum+ONNX Runtime – Hugging Fa...
- 「データストーリーテリングとアナリティ...
- 「機械学習プロジェクトのための最高のGit...
- コンピュータビジョンシステムは、ビデオ...
- AIの未来を形作る ビジョン・ランゲージ・...
- 最適化ストーリー:ブルーム推論
- MicrosoftエンジニアのAIイノベーションと...
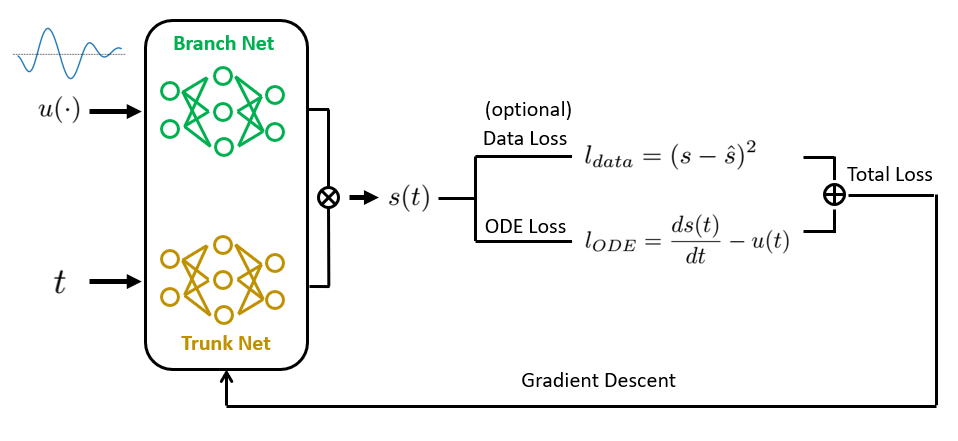
物理情報を組み込んだDeepONetによるオペレータ学習 ゼロから実装しましょう
普通微分方程式と偏微分方程式(ODEs / PDEs)は、物理学や生物学から経済学や気候科学まで、科学と工学の多くの分野の基礎ですそれらは...
OpenAIのモデレーションAPIを使用してコンテンツのモデレーションを強化する
プロンプトエンジニアリングの台頭や、言語モデルの大規模な成果により、私たちの問いに対する応答を生成する際の大変な成果を上げたLarge Language Modelsの注目すべき成果により、ChatGPTのようなチャットボットは私たちの日常生活の重要な一部となりつつあります...
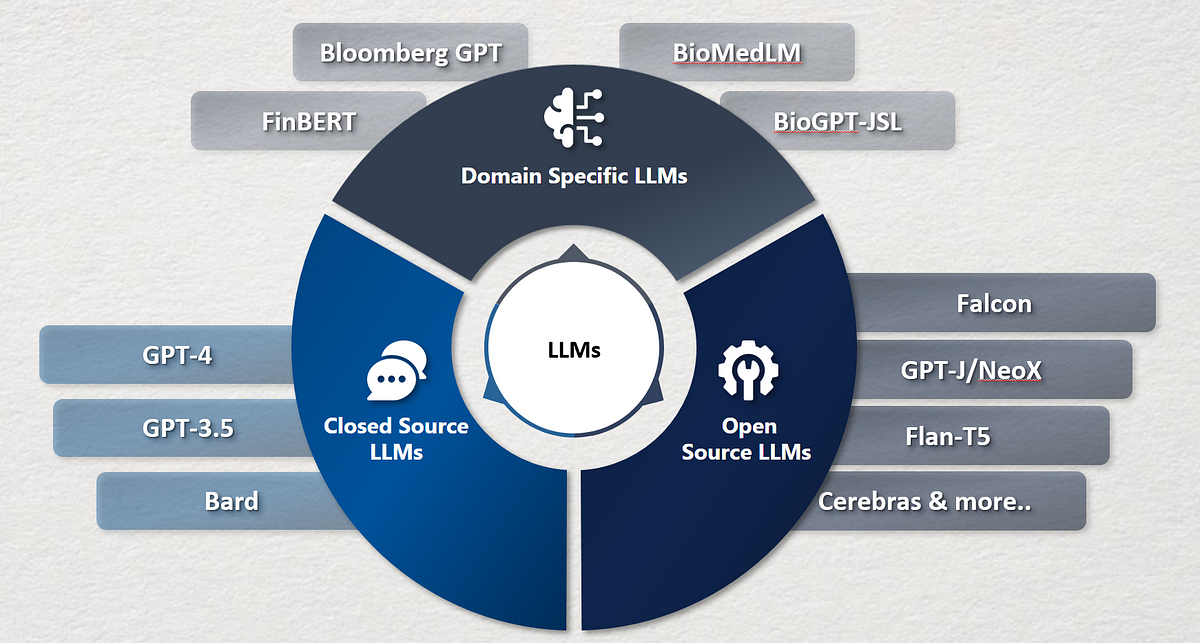
企業がOpenAIのChatGPTに類似した自社の大規模言語モデルを構築する方法
最近の数年間で、言語モデルは大きな注目を集め、自然言語処理、コンテンツ生成、仮想アシスタントなど、さまざまな分野を革新しました最も注目されているのは、
データモデリングの成功を解き放つ:3つの必須のコンテキストテーブル
データモデリングは、分析チームにとって課題となることがあります各組織には独自のビジネスエンティティが存在するため、それぞれのテーブルに適切な構造と詳細度を見つけることは限りなく難しいものですしかし、
LangChain:LLMがあなたのコードとやり取りできるようにします
生成モデルは皆の注目を集めています現在、多くのAIアプリケーションでは、機械学習の専門家ではなく、API呼び出しの実装方法を知っているだけで済むことが増えています最近の例としては、私は...
合成データのフィールドガイド
データを扱いたい場合、どのような選択肢がありますか?できるだけざっくりした回答をお伝えします実際のデータを入手するか、偽のデータを入手するかのどちらかです前回の記事では、私たちは...

ChatGPTから独自のプライベートなフランス語チューターを作成する方法
議論された外国語チューターのコードは、私のGitHubページの同梱リポジトリで見つけることができます非商業利用に限り、自由に使用することができます長い間延期していたので、私は...
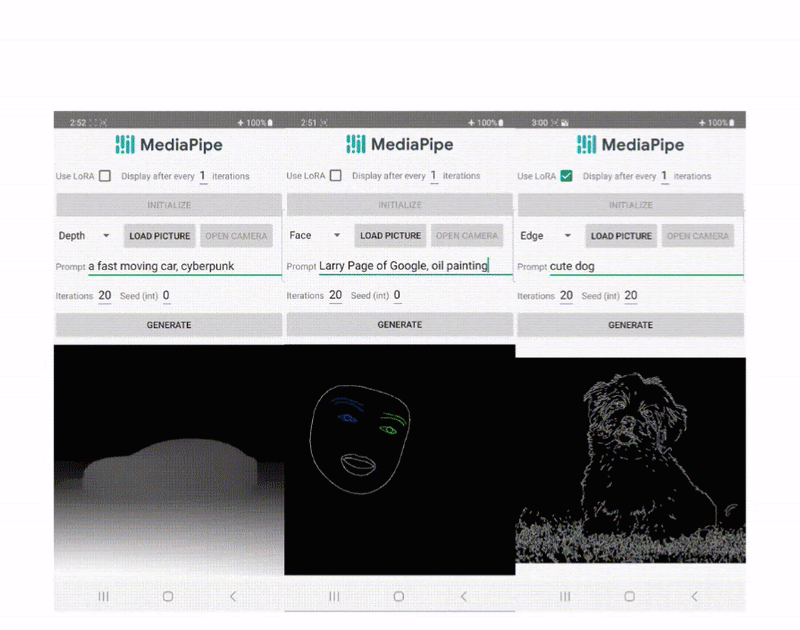
デバイス上での条件付きテキストから画像生成のための拡散プラグイン
Yang ZhaoとTingbo Houによる投稿、ソフトウェアエンジニア、Core ML 近年、拡散モデルはテキストから画像を生成する際に非常に成功を収め、高品質な画像、改善された推論パフォーマンス、そして創造的なインスピレーションの拡大を実現しています。しかし、特にテキストで説明しづらい条件での生成を効率的に制御することはまだ困難です。 本日、MediaPipe拡散プラグインを発表し、コントロール可能なテキストから画像をデバイス上で実行できるようにします。オンデバイスの大規模生成モデルにおけるGPU推論に関する以前の作業を拡張し、既存の拡散モデルとその低ランク適応(LoRA)バリアントにプラグインを追加し、コントロール可能なテキストから画像を生成するための低コストなソリューションを提供します。 デバイス上で動作するコントロールプラグインによるテキストからの画像生成。 背景 拡散モデルでは、画像生成はイテレーションのノイズ除去プロセスとしてモデル化されます。ノイズ画像から始め、各ステップで、拡散モデルは画像を徐々にノイズ除去して目標のコンセプトの画像を明らかにします。研究によると、テキストプロンプトを介した言語理解を活用することで、画像生成を大幅に改善できます。テキストから画像を生成する場合、テキストの埋め込みはモデルにクロスアテンションレイヤーを介して接続されます。しかし、位置や姿勢など、一部の情報はテキストプロンプトで説明することが難しいです。この問題を解決するために、研究者は拡散に追加のモデルを追加して、条件画像から制御情報を注入します。 制御されたテキストから画像を生成するための一般的なアプローチには、Plug-and-Play、ControlNet、T2I Adapterなどがあります。Plug-and-Playは、広く使用されているノイズ除去拡散暗黙モデル(DDIM)の逆操作アプローチを適用し、入力画像から初期ノイズ入力を導出し、拡散モデルのコピー(安定拡散1.5用の860Mパラメータ)を使用して入力画像から条件をエンコードします。Plug-and-Playは、コピーされた拡散から自己注意で空間特徴を抽出し、それらをテキストから画像への拡散に注入します。ControlNetは、拡散モデルのエンコーダーの学習可能なコピーを作成し、ゼロで初期化されたパラメータを持つ畳み込み層を介してデコーダーレイヤーに接続し、条件情報をエンコードします。しかし、その結果、サイズが大きく、拡散モデルの半分(安定拡散1.5用の430Mパラメータ)になります。T2I Adapterはより小さなネットワーク(77Mパラメータ)であり、制御可能な生成に似た効果を実現します。T2I Adapterは条件画像のみを入力とし、その出力はすべての拡散イテレーションで共有されます。ただし、アダプターモデルはポータブルデバイス向けに設計されていません。 MediaPipe拡散プラグイン 条件付き生成を効率的かつカスタマイズ可能、スケーラブルにするために、MediaPipe拡散プラグインを別個のネットワークとして設計しました。これは以下のような特徴を持っています: プラグ可能:事前にトレーニングされたベースモデルに簡単に接続できます。 スクラッチからトレーニング:ベースモデルの事前トレーニング済みの重みを使用しません。 ポータブル:ベースモデル外でモバイルデバイス上で実行され、ベースモデルの推論と比較して無視できるコストです。 メソッド パラメーターサイズ プラグ可能 スクラッチからトレーニング ポータブル Plug-and-Play…

TaatikNet(ターティクネット):ヘブライ語の翻字のためのシーケンス・トゥ・シーケンス学習
この記事では、TaatikNetとseq2seqモデルの簡単な実装方法について説明していますコードとドキュメントについては、TaatikNetのGitHubリポジトリを参照してくださいインタラクティブなデモについては、HF Spaces上のTaatikNetをご覧ください多くのタスク...
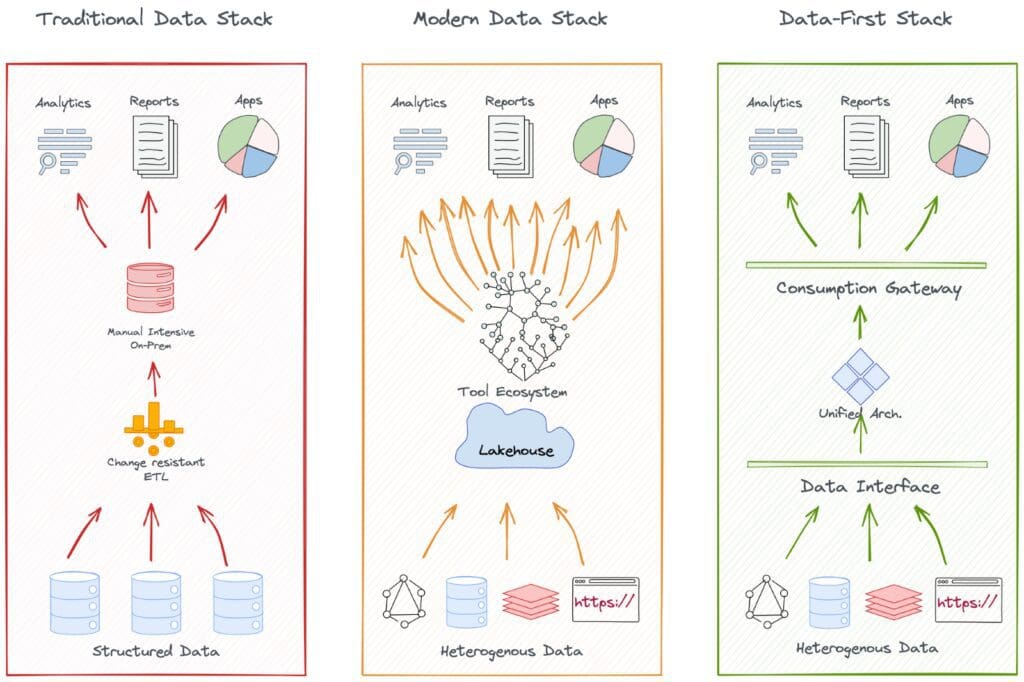
データランドスケープの進化
この記事は進化の物語を進化パターンの観点からデータ空間で追跡します進化の旅路の重要なマイルストーン、その達成、課題、それらの課題を解決した次のマイルストーンの状態について語りますこの記事はビジネスと技術の両面からの観点で書かれています...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.