Learn more about Search Results ML - Page 268

- You may be interested
- 「MMMUと出会おう:専門家レベルのマルチ...
- プロンプトエンジニアリングにおける並列...
- キャッシュの遷移に対する自動フィードバ...
- 「イギリス、ロシアが数年にわたり議員や...
- クラスの不均衡:SMOTEからSMOTE-NCおよび...
- 教師なしの深層学習により、単一の下側頭...
- 「自律ロボット研究所によって発見された...
- 「ピアソン、スピアマン、ケンドール相関...
- 「10ベストAIゲームジェネレーター(2023...
- 自動車産業の未来は、話す車かもしれません
- 「GPT-4と説明可能なAI(XAI)によるAIの...
- 「コードレスのソリューションでAIを民主...
- FineShare Review 2023年の最高の人工知能...
- 「A.I.言語モデルの支援を受けて、Google...
- Pythonのzip()関数の探索:反復とデータの...
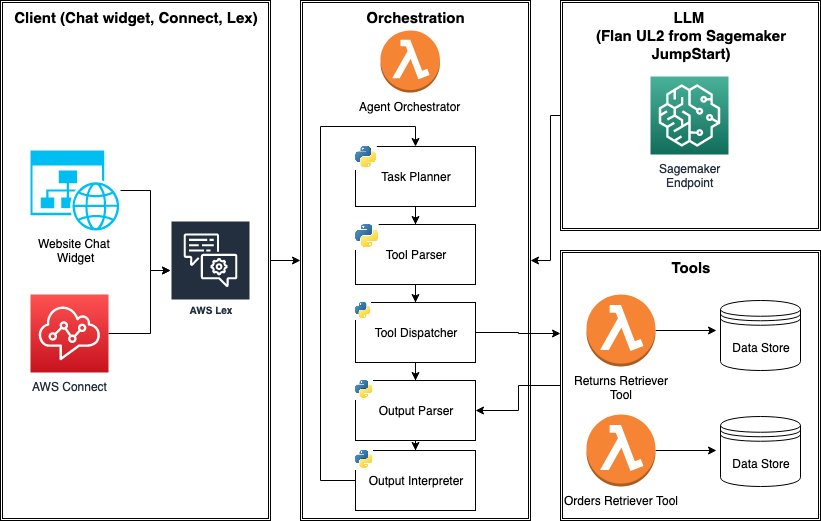
AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
大規模な言語モデル(LLM)エージェントは、1)外部ツール(API、関数、Webフック、プラグインなど)へのアクセスと、2)自己指導型のタスクの計画と実行の能力を持つ、スタンドアロンのLLMの機能を拡張するプログラムですしばしば、LLMは複雑なタスクを達成するために他のソフトウェア、データベース、またはAPIと対話する必要があります[...]

「SIEM-SOAR インテグレーションによる次世代の脅威ハンティング技術」
NLP、AI、およびMLは、データ処理の効率化、自動化されたインシデント処理、コンプライアンス、および積極的な脅威検知を通じて、サイバーセキュリティを向上させます

「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
現在では、多くの人々が書籍や他のメディアの代わりにオーディオブックを読んでいます。オーディオブックは、現在の読者が道路上で情報を楽しむだけでなく、子供や視覚障害者、新しい言語を学んでいる人などのグループにもコンテンツを利用しやすくすることができます。従来のオーディオブック制作技術は時間と費用がかかり、プロの人間のナレーションやLibriVoxのようなボランティア主導の取り組みなど、録音品質のばらつきが生じることがあります。これらの問題により、出版される書籍の増加に追いつくには時間と労力がかかります。 ただし、テキスト読み上げシステムのロボット的な性質や、目次、ページ番号、図表、脚注などのテキストを読み上げないようにする難しさにより、自動オーディオブック作成はこれまで苦労してきました。彼らは、さまざまなオンライン電子書籍コレクションから高品質のオーディオブックを作成するために、最近のニューラルテキスト読み上げ、表現豊かな読み上げ、スケーラブルな計算、関連コンテンツの自動認識などの最新の進展を取り入れた手法を提供しています。 彼らは、オープンソースに5,000冊以上のオーディオブック、合計35,000時間以上の音声を提供しています。また、デモンストレーションソフトウェアも提供しており、会議参加者がライブラリの本を声に出して読むだけで、自分自身の声でオーディオブックを作成できるようになっています。この研究では、HTMLベースの電子書籍を優れたオーディオブックに変換するためのスケーラブルな方法を紹介しています。パイプラインの基盤としては、分散オーケストレーションが可能なスケーラブルな機械学習プラットフォームであるSynapseMLが使用されています。彼らの配信チェーンは、数千冊のProject Gutenbergが提供する無料の電子書籍から始まります。これらの書籍は主にHTML形式で取り扱われており、自動解析に適しています。 その結果、Project GutenbergのHTMLページの完全なコレクションを整理し、同様の構造を持つファイルの多数のグループを特定することができました。主要な電子書籍のクラスは、これらのHTMLファイルのコレクションを使用して作成されたルールベースのHTML正規化器を使用して、標準形式に変換されました。このアプローチにより、大量の本を迅速かつ確実に解析することができました。最も重要なことは、読み上げると高品質の録音になるファイルに焦点を当てることができたということです。 図1: t-SNEクラスタリングされた電子書籍の表現。同じ形式の本のクラスターは、色付きの領域で示されています。 このクラスタリングの結果は、図1に示されており、Project Gutenbergのコレクションにおいて同様に構成された電子書籍のさまざまなグループが自発的に現れる様子が示されています。処理後、プレーンテキストのストリームを抽出し、テキスト読み上げアルゴリズムに供給することができます。さまざまなオーディオブックには多くの読み方のテクニックが必要です。ノンフィクションには明確で客観的な声が最適であり、対話があるフィクションには表現豊かな読み上げと少しの「演技」が適しています。ただし、ライブデモンストレーションでは、テキストの声、ペース、ピッチ、抑揚を変更するオプションを提供します。ほとんどの本では、明確で中立的なニューラルテキスト読み上げの声を使用しています。 彼らは、ゼロショットテキスト読み上げ技術を使用して、登録された少数の録音から効果的に声の特徴を転送し、ユーザーの声を再現しています。これにより、少量のキャプチャされた音声だけで、ユーザーは迅速に自分の声でオーディオブックを作成することができます。また、音声と感情の推論システムを使用して、文脈に基づいて読み上げの声やトーンを動的に変更し、感情的なテキスト読み上げを行います。これにより、複数の人物や動的な対話を持つシーケンスのリアルさと興味が向上します。 これを実現するために、まずテキストをナレーションと会話に分割し、各対話ごとに異なる話者を割り当てます。次に、セルフスーパーバイズド学習を使用して、各対話の感情的なトーンを予測します。最後に、異なる声と感情をナレーターとキャラクターの会話に割り当てるために、マルチスタイルとコンテキストベースのニューラルテキスト読み上げモデルを使用します。彼らは、このアプローチがオーディオブックの利用可能性とアクセシビリティを大幅に向上させる可能性があると考えています。 を日本語に翻訳すると、 となります。

「NExT-GPTを紹介します:エンドツーエンドの汎用的な任意対任意のマルチモーダル大規模言語モデル(MM-LLM)」
マルチモーダルLLMは、音声、テキスト、および視覚入力を介したより自然で直感的なユーザーとAIシステムのコミュニケーションを可能にすることで、人間とコンピュータのインタラクションを向上させることができます。これにより、チャットボット、仮想アシスタント、コンテンツ推薦システムなどのアプリケーションにおいて、より文脈に即した総合的な応答が可能となります。これらは、GPT-3などの従来の単一モーダル言語モデルの基礎を築きながら、異なるデータタイプを処理するための追加の機能を組み込んでいます。 ただし、マルチモーダルLLMは、優れたパフォーマンスを発揮するためには大量のデータが必要となり、他のAIモデルよりもサンプル効率が低くなる可能性があります。トレーニング中に異なるモダリティのデータを整合させることは困難な場合があります。エラー伝搬におけるエンドツーエンドのトレーニングが全体的に欠けているため、コンテンツの理解やマルチモーダルな生成能力は非常に限定的となることがあります。異なるモジュール間の情報伝達は、LLMによって生成される離散的なテキストに基づいて完全に行われるため、ノイズやエラーが避けられません。各モダリティからの情報が適切に同期されることは、実用的なトレーニングには不可欠です。 これらの問題に対処するために、NeXT++の研究者、School of Computing(NUS)は、NexT-GPTを構築しました。これは、テキスト、画像、動画、音声のモダリティの任意の組み合わせでの入力と出力を処理するために設計されたマルチモーダルLLMです。エンコーダは、さまざまなモダリティの入力をエンコードし、それらをLLMの表現に投影することができます。 彼らの手法は、既存のオープンソースのLLMを修正して、入力情報を処理するコアとして使用します。投影後、特定の指示を持つ生成されたマルチモーダル信号は、異なるエンコーダに送られ、最終的に対応するモダリティでコンテンツが生成されます。モデルをゼロからトレーニングするのは費用効果が低いため、既存の高性能なエンコーダとデコーダ(Q-Former、ImageBind、最先端の潜在的な拡散モデルなど)を使用します。 彼らは、LLM中心のエンコーディング側とデコーディング側の指示に従ったアライメントを効率的に実現するための軽量なアライメント学習技術を導入しました。さらに、人間レベルの機能を持つ任意のMM-LLMを実現するためのモダリティ切り替え指示チューニングも導入しています。これにより、異なるモダリティの特徴空間のギャップを埋め、他の入力の流暢な文脈理解を確保し、NExT-GPTのためのアライメント学習を行うことができます。 モダリティ切り替え指示チューニング(MosIT)は、複雑なクロスモーダルな理解と推論をサポートし、洗練されたマルチモーダルなコンテンツ生成を可能にします。彼らはさらに、多様なユーザーのインタラクションを扱い、必要な応答を正確に提供するために必要な複雑さと変動性を持つ高品質なデータセットを構築しました。 最後に、彼らの研究は、任意のMMLLMがさまざまなモダリティ間のギャップを埋め、将来的により人間らしいAIシステムの可能性を示しています。

GraphReduce グラフを使用した特徴エンジニアリングの抽象化
編集者の注 Wes Madrigalさんは、10月30日から11月2日までODSC Westのスピーカーです彼の講演「大規模特徴エンジニアリングパイプラインにおけるグラフの使用」をぜひチェックして、GraphReduceなどについてもっと学んでください!ML/AIで働く読者にとっては、機械学習モデルはよく知られています...

Amazon SageMakerで@remoteデコレータを使用してFalcon 7Bやその他のLLMを微調整する
今日、生成型AIモデルはテキスト要約、Q&A、画像やビデオの生成など、さまざまなタスクをカバーしています出力の品質を向上させるために、n-短期学習、プロンプトエンジニアリング、検索補完生成(RAG)およびファインチューニングなどの手法が使用されていますファインチューニングにより、これらの生成型AIモデルを調整して、ドメイン固有の改善されたパフォーマンスを達成することができます

「成功したプロンプトの構造の探索」
この記事では、著者がGPTConsoleのBirdとPixie AIエージェントのためのプログラマのハンドブックを読者に提供しています

「生産性を最大化するための5つの最高のAIツール」
VoAGIは、生産性を最大限に引き上げるためのさまざまな5つのAIツールをレビューしていますぜひご覧いただき、私たちのおすすめをご覧ください
AIにおけるブロックチェーンの包括的なレビュー
AIとブロックチェーンは、近年最も画期的な技術革新として浮上しています人工知能(AI):機械やコンピュータが人間の思考や意思決定プロセスを模倣することを可能にしますブロックチェーン:分散型で変更不可能な台帳で、データや情報を分散化された信頼性の高い方法で安全に保存します最近、科学者たちは潜在的な探求に没頭しています[…]

モジュラーの共同創設者兼社長であるティム・デイビス- インタビューシリーズ
ティム・デイビスは、Modularの共同創設者兼社長ですModularは統合された、組み合わせ可能なツールのスイートであり、AIインフラストラクチャを簡素化し、チームがより迅速に開発、展開、イノベーションできるようにしますModularは、Pythonの優れた点とシステムを組み合わせることで、研究と製品化のギャップを埋める新しいプログラミング言語「Mojo」を開発することで最も知られています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.