Learn more about Search Results 比較 - Page 262

- You may be interested
- IBMの「Condor」量子コンピュータは1000以...
- 「生存分析を用いたイベント発生までの時...
- 2024年にSQLの概念をマスターするためのト...
- AIを使って若返る方法:新しい抗加齢薬が...
- CoDiに会おう:任意対任意合成のための新...
- フォトグラメトリとは何ですか?
- 「つながる点 OpenAIの主張されたQ-Starモ...
- 「リトリーバル増強生成(RAG)とファイン...
- 「Surfer SEO レビュー:最高のAI SEO ツ...
- 「倫理的かつ説明可能なAIのための重要な...
- 「自然言語処理のマスタリングへの7つのス...
- ラストマイルAIは、AiConfigをリリースし...
- エンコーダー・デコーダーモデルのための...
- AlphaCodeとの競技プログラミング
- データサイエンスは良いキャリアですか?

Imagen EditorとEditBench:テキストによる画像補完の進展と評価
グーグルリサーチの研究エンジニアであるスー・ワンとセズリー・モンゴメリーによる投稿 過去数年間、テキストから画像を生成する研究は、画期的な進展(特に、Imagen、Parti、DALL-E 2など)を見ており、これらは自然に関連するトピックに浸透しています。特に、テキストによる画像編集(TGIE)は、完全にやり直すのではなく、生成された物と撮影された視覚物を編集する実践的なタスクであり、素早く自動化されたコントロール可能な編集は、視覚物を再作成するのに時間がかかるか不可能な場合に便利な解決策です(例えば、バケーション写真のオブジェクトを微調整したり、ゼロから生成されたかわいい子犬の細かいディテールを完璧にする場合)。さらに、TGIEは、基礎となるモデルのトレーニングを改良する大きな機会を表しています。マルチモーダルモデルは、適切にトレーニングするために多様なデータが必要であり、TGIE編集は高品質でスケーラブルな合成データの生成と再結合を可能にすることができ、おそらく最も重要なことに、任意の軸に沿ってトレーニングデータの分布を最適化する方法を提供できます。 CVPR 2023で発表される「Imagen Editor and EditBench: Advancing and Evaluating Text-Guided Image Inpainting」では、マスクインペインティングの課題に対する最先端の解決策であるImagen Editorを紹介します。つまり、ユーザーが、編集したい画像の領域を示すオーバーレイまたは「マスク」(通常、描画タイプのインターフェイス内で生成されるもの)と共にテキスト指示を提供する場合のことです。また、画像編集モデルの品質を評価する方法であるEditBenchも紹介します。EditBenchは、一般的に使用される粗い「この画像がこのテキストに一致するかどうか」の方法を超えて、モデルパフォーマンスのより細かい属性、オブジェクト、およびシーンについて詳細に分析します。特に、画像とテキストの整合性の信頼性に強い重点を置きつつ、画像の品質を見失わないでください。 Imagen Editorは、指定された領域にローカライズされた編集を行います。モデルはユーザーの意図を意味を持って取り入れ、写真のようなリアルな編集を実行します。 Imagen Editor Imagen Editorは、Imagenでファインチューニングされた拡散ベースのモデルで、編集を行うために改良された言語入力の表現、細かい制御、および高品質な出力を目的としています。Imagen Editorは、ユーザーから3つの入力を受け取ります。1)編集する画像、2)編集領域を指定するバイナリマスク、および3)テキストのプロンプトです。これら3つの入力は、出力サンプルを誘導します。 Imagen Editorは、高品質なテキストによる画像インペインティングを行うための3つの核心技術に依存しています。まず、ランダムなボックスとストロークマスクを適用する従来のインペインティングモデル(例:Palette、Context…

人間の注意力を予測するモデルを通じて、心地よいユーザーエクスペリエンスを実現する
Google Researchのシニアリサーチサイエンティスト、Junfeng He氏とスタッフリサーチサイエンティスト、Kai Kohlhoff氏による記事です。 人間は、驚くほど多くの情報を取り入れる能力を持っています(網膜に入る情報は秒間約10 10ビット)。そして、タスクに関連し、興味深い領域に選択的に注目し、さらに処理する能力を持っています(例:記憶、理解、行動)。人間の注意(その結果として得られるものはしばしば注目モデルと呼ばれます)をモデル化することは、神経科学、心理学、人間コンピュータインタラクション(HCI)、コンピュータビジョンの分野で興味を持たれてきました。どの領域でも、どの領域でも、注目が集まる可能性が高い領域を予測する能力には、グラフィックス、写真、画像圧縮および処理、視覚品質の測定など、多数の重要な応用があります。 以前、機械学習とスマートフォンベースの注視推定を使用して、以前は1台あたり3万ドルにも及ぶ専門的なハードウェアが必要だった視線移動の研究を加速する可能性について説明しました。関連する研究には、「Look to Speak」というアクセシビリティニーズ(ALSのある人など)を持つユーザーが目でコミュニケーションするのを支援するものと、「Differentially private heatmaps」という、ユーザーのプライバシーを保護しながら注目のようなヒートマップを計算する技術が最近発表されました。 このブログでは、私たちはCVPR 2022からの1つの論文と、CVPR 2023での採用が決定したもう1つの論文、「Deep Saliency Prior for Reducing Visual Distraction」と「Learning from Unique Perspectives: User-aware…

NeRFを使用して室内空間を再構築する
Marcos Seefelder、ソフトウェアエンジニア、およびDaniel Duckworth、リサーチソフトウェアエンジニア、Google Research 場所を選ぶ際、私たちは次のような疑問を持ちます。このレストランは、デートにふさわしい雰囲気を持っているのでしょうか?屋外にいい席はありますか?試合を見るのに十分なスクリーンがありますか?これらの質問に部分的に答えるために、写真やビデオを使用することがありますが、実際に訪れることができない場合でもそこにいるような感覚には代わりがありません。 インタラクティブでフォトリアルな多次元の没入型体験は、このギャップを埋め、スペースの感触や雰囲気を再現し、ユーザーが必要な情報を自然かつ直感的に見つけることができるようにすることができます。これを支援するために、Google MapsはImmersion Viewを開発しました。この技術は、機械学習(ML)とコンピュータビジョンの進歩を活用して、Street Viewや航空写真など数十億の画像を融合して世界の豊富なデジタルモデルを作成します。さらに、天気、交通、場所の混雑度などの役立つ情報を上に重ねます。Immersive Viewでは、レストラン、カフェ、その他の会場の屋内ビューが提供され、ユーザーが自信を持ってどこに行くかを決めるのに役立ちます。 今日は、Immersion Viewでこれらの屋内ビューを提供するために行われた作業について説明します。私たちは、写真を融合してニューラルネットワーク内で現実的な多次元の再構成を生成するための最先端の手法であるニューラル輝度場(NeRF)に基づいています。私たちは、DSLRカメラを使用してスペースのカスタム写真キャプチャ、画像処理、およびシーン再現を含むNeRFの作成パイプラインについて説明します。私たちは、Alphabetの最近の進歩を活用して、視覚的な忠実度で以前の最先端を上回るか、それに匹敵する方法を設計しました。これらのモデルは、キュレーションされたフライトパスに沿って組み込まれたインタラクティブな360°ビデオとして埋め込まれ、スマートフォンで利用可能になります。 アムステルダムのThe Seafood Barの再構築(Immersive View内)。 写真からNeRFへ 私たちの作業の中核にあるのは、最近開発された3D再構成および新しいビュー合成の方法であるNeRFです。シーンを説明する写真のコレクションがある場合、NeRFはこれらの写真をニューラルフィールドに凝縮し、元のコレクションに存在しない視点から写真をレンダリングするために使用できます。 NeRFは再構成の課題を大部分解決したものの、実世界のデータに基づくユーザー向け製品にはさまざまな課題があります。たとえば、照明の暗いバーから歩道のカフェ、ホテルのレストランまで、再構成品質とユーザー体験は一貫している必要があります。同時に、プライバシーは尊重され、個人を特定する可能性のある情報は削除される必要があります。重要なのは、シーンを一貫してかつ効率的にキャプチャし、必要な写真を撮影するための労力を最小限に抑えたまま、高品質の再構成が確実に得られることです。最後に、すべてのモバイルユーザーが同じ自然な体験を手に入れられるようにすることが重要です。 Immersive View屋内再構築パイプライン。 キャプチャ&前処理 高品質なNeRFを生成するための最初のステップは、シーンを注意深くキャプチャすることです。3Dジオメトリーとカラーを派生させるための複数の異なる方向からの密な写真のコレクションを作成する必要があります。オブジェクトの表面に関する情報が多いほど、モデルはオブジェクトの形状やライトとの相互作用の方法を発見する際により優れたものになります。 さらに、NeRFモデルはカメラやシーンそのものにさらなる仮定を置きます。たとえば、カメラのほとんどのプロパティ(ホワイトバランスや絞りなど)は、キャプチャ全体で固定されていると仮定されます。同様に、シーン自体は時間的に凍結されていると仮定されます。ライティングの変更や動きは避ける必要があります。これは、キャプチャに必要な時間、利用可能な照明、機器の重さ、およびプライバシーなどの実用上の問題とのバランスを取る必要があります。プロの写真家と協力して、DSLRカメラを使用して会場写真を迅速かつ信頼性の高い方法でキャプチャする戦略を開発しました。このアプローチは、現在までのすべてのNeRF再構築に使用されています。…

NVIDIAとHexagonが、産業のデジタル化を加速するためのソリューションスイートを提供します
産業企業がデジタル化の次のレベルに到達するためには、物理システムの正確なバーチャルな表現を作成する必要があります。 NVIDIAは、ストックホルムに拠点を置くデジタルリアリティソリューションのグローバルリーダーであるHexagonと協力し、AI対応のデジタルツインを構築するために必要なツールとソリューションを企業に提供しています。これにより、物理的に正確で完全に同期されたデジタルツインを作成し、組織を変革することができます。 Hexagonは、HxDRリアリティキャプチャとNexus製造プラットフォームからNVIDIA Omniverseに統合を構築しています。Omniverseは、Universal Scene Description(「OpenUSD」)プラグインを介して産業メタバースアプリケーションを開発および運用するためのオープンプラットフォームです。NVIDIA AIテクノロジーによって駆動される接続されたプラットフォームは、農業、自律移動、建物、都市、防衛、インフラ、製造、鉱業を含むHexagonの主要なエコシステム全体に利益をもたらします。 これらのソリューションにより、統一されたビューを通じてシームレスなコラボレーションプランニングが実現し、産業顧客はワークフローを最適化し、スケールを拡大することができます。プロフェッショナルや開発者は、リアリティキャプチャ、デジタルツイン、AI、シミュレーション、可視化の高度な機能を利用して、仮想プロトタイピングからデジタル工場まで最も複雑なグラフィックスワークフローを強化することができます。 物理世界とデジタル世界を融合した現実 製造業は、新製品を設計・開発する数百万の工場を世界中に有している46兆ドルの産業です。デジタル化により、製造業者はより効率的かつ生産的な方法で最も複雑なエンジニアリング問題に取り組むことができます。また、産業企業はワークフローを自動化し、ソフトウェアによってサービスを変革することで、オペレーショナル効率を向上させ、ソフトウェア定義化に近づくことができます。 HxGN LIVE Globalイベントでは、HexagonとNVIDIAが統合提供を通じてデジタル化の旅を加速する方法を紹介しました。下のデモを見て、設計者、エンジニア、その他の人々がOmniverseプラットフォームを使用して、HexagonのHxDRおよびNexusプラットフォームから超複雑なデータを迅速に集約およびシミュレーションする方法をご覧ください。 Hexagonは、OmniverseをベースにしたAI対応のWebアプリケーションを開発しており、デジタルツインと物理世界のリアルタイム比較ができるようになります。これにより、意思決定を加速し、計画とオペレーションを最適化することができます。このソリューションにより、エンタープライズは、チーム全体で迅速な反復を実現し、より協力的なワークフローを実現することができます。 この発表により、Omniverseエコシステムは、Hexagonのジオスペーシャルリアリティキャプチャ、センサー、ソフトウェア、自律技術の専門知識を活用することができ、企業はこれまで以上に迅速かつ正確に仮想世界を構築、シミュレーション、運用、最適化することができます。 NVIDIA Omniverseについて詳しくはこちらをご覧ください。Hexagonの最新発表を読んで、HxGN LIVE Global 2023での最新のデモや展示を見てください。
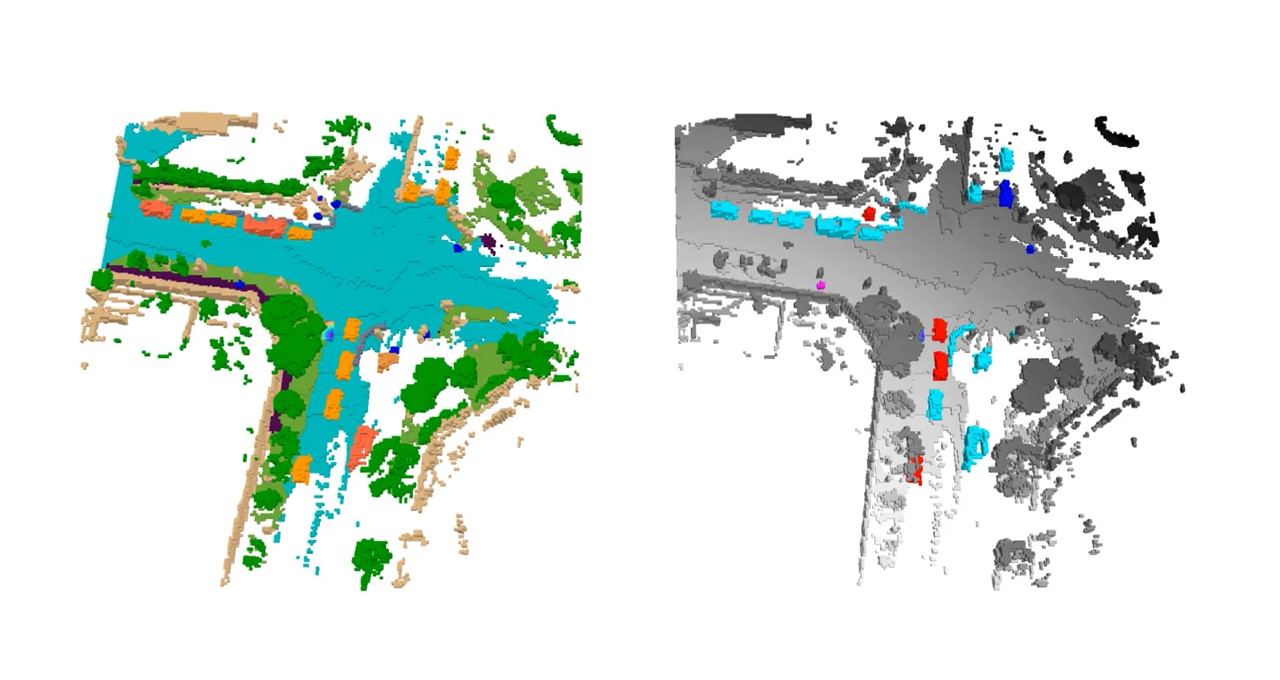
NVIDIAリサーチがCVPRで自律走行チャレンジとイノベーション賞を受賞
NVIDIAは、カナダのバンクーバーで開催されるComputer Vision and Pattern Recognition Conference(CVPR)において、自律走行開発の3D占有予測チャレンジで激戦を制し、優勝者として紹介されます。 この競技には、10地域にまたがる約150チームから400以上の投稿がありました。 3D占有予測とは、シーン内の各ボクセルの状態を予測するプロセスであり、つまり3Dバードアイビューグリッド上の各データポイントを指します。ボクセルは、フリー、占有、または不明として識別することができます。 安全で堅牢な自動運転システムの開発に不可欠な3D占有グリッド予測は、NVIDIA DRIVEプラットフォームによって可能になる最新の畳み込みニューラルネットワークやトランスフォーマーモデルを使用して、自律車両(AV)の計画および制御スタックに情報を提供します。 「NVIDIAの優勝ソリューションには、2つの重要なAVの進歩があります」と、NVIDIAの学習と知覚のシニアリサーチサイエンティストであるZhiding Yu氏は述べています。「優れたバードアイビュー認識を生み出す最新のモデル設計を実証することができます。さらに、3D占有予測での10億パラメーターまでのビジュアルファウンデーションモデルの効果と大規模な事前学習の有効性を示しています。」 自動運転の知覚は、画像内のオブジェクトや空きスペースなどの2Dタスクの処理から、複数の入力画像を使用して3Dで世界を理解することに進化しています。 これにより、複雑な交通シーン内のオブジェクトについて柔軟で精密な細かい表現が提供されるようになり、これはNVIDIAのAV応用研究および著名な科学者であるJose Alvarez氏によれば、「自律走行の安全感知要件を達成するために重要です。」 Yu氏は、NVIDIA Researchチームの受賞作品を、6月18日(日)10:20 a.m. PTに開催されるCVPRのEnd-to-End Autonomous Driving Workshopおよび6月19日(月)4:00 p.m. PTに開催されるVision-Centric…

2023年に知っておく必要があるデータ分析ツール
成功するデータアナリストになるために知っておく必要があるツールは何ですか?

VoAGIニュース、5月31日:データサイエンスチートシートのためのバード•ChatGPT、GPT-4、Bard、その他のLLMを検出するためのトップ10ツール
データサイエンスのためのBardチートシート• ChatGPT、GPT-4、Bard、その他のLLMを検出するためのトップ10ツール•2023年に知っておく必要があるデータ分析ツール•AIがデータサイエンスを食いつぶす• GPTモデルに深く入り込む:進化と性能比較

Essential MLOps:無料の電子書籍
この機械学習運用の基礎に関する無料のebookをチェックしてください

機械学習モデルのための高度な特徴選択技術
特徴選択のマスタリング:教師あり・教師なし機械学習モデルの高度な技術の探求

AIの10年間のレビュー
画像分類からチャットボット療法まで
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.