Learn more about Search Results 比較 - Page 261

- You may be interested
- 🤗 Transformersでn-gramを使ってWav2Vec2...
- 現実世界における機械学習エンジニアリング
- 『LLMWareの紹介:生成AIアプリケーション...
- 「ベストを学ぶ – 必読のテック企業...
- 「コンパートメント化拡散モデル(CDM) ...
- メタ AI 研究者たちは、非侵襲的な脳記録...
- メタはより強力なAIを発表し、それを使用...
- 「グローバル人工知能市場は31%の急成長...
- 動的に画像のサイズを調整する
- テンセントAI研究所では、GPT4Videoを紹介...
- ネットワークグラフを視覚化するための最...
- ロボットが太陽エネルギー研究を推進
- 『分析チームとしての緊急性と持続可能性...
- 「より良いデータセットが新しいSOTAモデ...
- 「効果的なマーケティング戦略開発のため...

AIのマスタリング:プロンプトエンジニアリングソリューションの力
私と一緒にAIプロンプトエンジニアリングの素晴らしさを発見しましょう!ユーモアのある効果的なプロンプトの制作によって、AIモデルのフルポテンシャルを引き出すことができます
データサイエンティストとして成功するために必要なソフトスキル
データサイエンティストとしてのキャリアを構築する際には、ハードスキルにフォーカスすることが簡単です非線形カーネルを持つSVMのような新しいMLアルゴリズムを学ぶことや、新しいソフトウェアを学びたいと思うかもしれません

プレイヤーの離脱を予測する方法、ChatGPTの助けを借りる
ゲームの世界では、企業はプレイヤーを引きつけるだけでなく、特にゲーム内のマイクロトランザクションに頼る無料のゲームでは、できるだけ長く彼らを保持することを目指していますこれらの...
線形回帰と勾配降下法
線形回帰は機械学習に存在する基本アルゴリズムの1つですその内部ワークフローを理解することは、データサイエンスの他のアルゴリズムの主要な概念を把握するのに役立ちます...
Word2Vec、GloVe、FastText、解説
コンピューターは我々と同じように単語を理解することができませんコンピューターは数字を扱うことが好きですですから、コンピューターが単語とその意味を理解するのを助けるために、私たちは「埋め込み」と呼ばれるものを使用しますこれらの埋め込みは…

Boto3 vs AWS Wrangler PythonによるS3操作の簡素化
このチュートリアルでは、boto3とawswranglerの2つの強力なライブラリを探索し、比較することで、PythonによるAWS S3開発の世界に深く入り込んでいきます実際、この記事では以下の内容をカバーします…
非教師あり学習シリーズ:階層クラスタリングの探索
前回の「教師なし学習シリーズ」の投稿では、最も有名なクラスタリング手法の1つであるK平均法クラスタリングについて探究しました今回の投稿では、別の手法の背後にある方法について説明します...
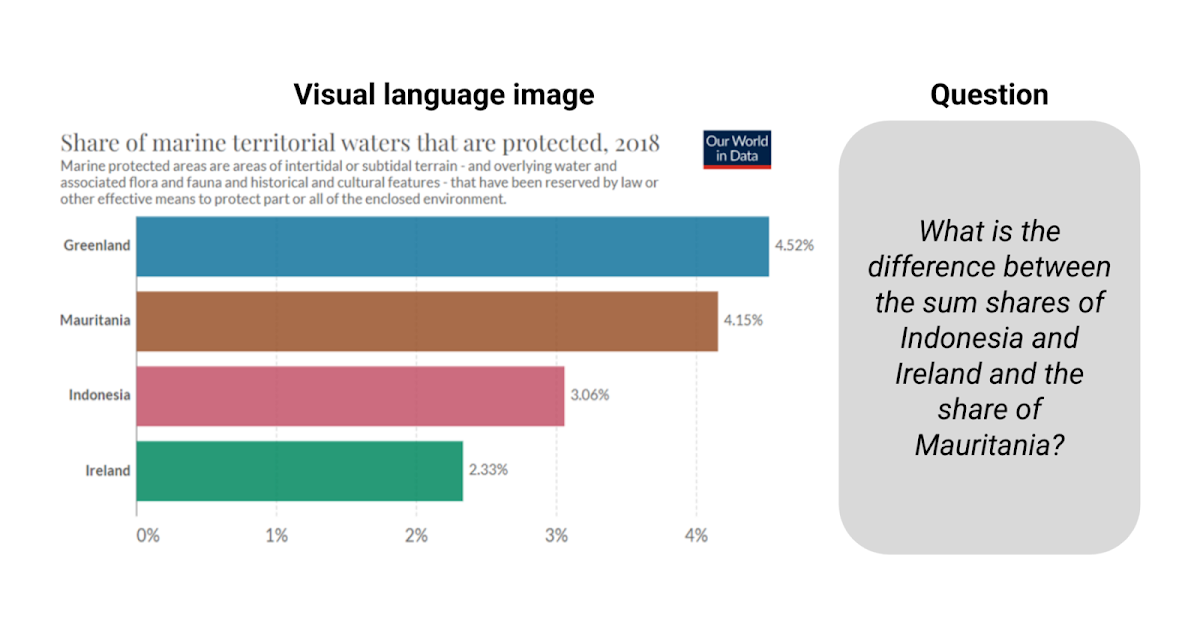
チャートの推論に基づくモデルの基盤
グーグルリサーチのリサーチソフトウェアエンジニア、ジュリアン・アイゼンシュロスによる投稿 ビジュアル言語は、情報を伝えるためにテキスト以外の絵文字を使用するコミュニケーション形式です。アイコノグラフィ、情報グラフィック、表、プロット、チャートなどの形でデジタルライフで普及しており、道路標識、コミックブック、食品ラベルなどの現実世界にも広がっています。このようなメディアをコンピュータがより理解できるようにすることは、科学的コミュニケーションと発見、アクセシビリティ、データの透過性に役立ちます。 ImageNetの登場以来、学習ベースのソリューションを使用してコンピュータビジョンモデルは大きな進歩を遂げてきましたが、焦点は自然画像にあり、分類、ビジュアルクエスチョンアンサリング(VQA)、キャプション、検出、セグメンテーションなどのさまざまなタスクが定義され、研究され、いくつかの場合には人間の性能に達成されています。しかし、ビジュアル言語は同じレベルの注目を集めていません。これは、この分野における大規模なトレーニングセットの不足のためかもしれません。しかし、PlotQA、InfographicsVQA、ChartQAなどの視覚言語イメージにおける質問応答システムの評価を目的とした新しい学術データセットが、ここ数年で作成されています。 ChartQAからの例。質問に答えるには、情報を読み取り、合計と差を計算する必要があります。 これらのタスクに対して構築された既存のモデルは、光学的文字認識(OCR)情報とその座標を大規模なパイプラインに統合することに頼っていましたが、プロセスはエラーが発生しやすく、遅く、一般化が悪いです。既存の畳み込みニューラルネットワーク(CNN)またはトランスフォーマーに基づくエンドツーエンドのコンピュータビジョンモデルは、自然画像で事前にトレーニングされたモデルを簡単にビジュアル言語に適応させることができなかったため、これらの方法が広く使用されていました。しかし、既存のモデルは、棒グラフの相対高さや円グラフのスライスの角度を読み取り、軸のスケールを理解し、色、サイズ、テクスチャでピクトグラムを伝説値に正しくマッピングし、抽出された数字で数値演算を実行するなど、チャートの質問に対する課題には準備ができていません。 これらの課題に対応するために、「MatCha:数学推論とチャートディレンダリングを活用したビジュアル言語の事前トレーニングの強化」という提案を行います。 MatChaは数学とチャートを表す言葉であり、2つの補完的なタスクでトレーニングされたピクセルからテキストへの基礎モデル(複数のアプリケーションでファインチューニングできる組み込み帰納バイアスを備えた事前トレーニングモデル)です。1つはチャートディレンダリングであり、プロットまたはチャートが与えられた場合、画像からテキストモデルはその基礎となるデータテーブルまたはレンダリングに使用されるコードを生成する必要があります。数学推論の事前トレーニングでは、テキストベースの数値推論データセットを選択し、入力を画像にレンダリングし、画像からテキストモデルが回答をデコードする必要があります。また、「DePlot:プロットからテーブルへの翻訳によるワンショットビジュアル言語推論」という、テーブルへの翻訳を介したチャートのワンショット推論にMatChaの上に構築されたモデルを提案します。これらの方法により、ChartQAの以前の最高記録を20%以上超え、パラメータが1000倍多い最高の要約システムに達成します。両方の論文はACL2023で発表されます。 チャートディレンダリング プロットやチャートは、基礎となるデータテーブルとコードによって通常生成されます。コードは、図の全体的なレイアウト(タイプ、方向、色/形状スキームなど)を定義し、基礎となるデータテーブルは実際の数字とそのグループ化を確立します。データとコードの両方がコンパイラ/レンダリングエンジンに送信され、最終的な画像が作成されます。チャートを理解するには、イメージ内の視覚パターンを発見し、効果的に解析してグループ化し、主要な情報を抽出する必要があります。プロットレンダリングプロセスを逆転するには、すべてのこのような機能が必要であり、したがって理想的な事前トレーニングタスクとして機能することができます。 ランダムなプロットオプションを使用して、Airbus A380 Wikipediaページの表から作成されたチャートです。MatChaの事前トレーニングタスクは、イメージからソーステーブルまたはソースコードを回復することです。 チャート、その基礎となるデータテーブル、およびそのレンダリングコードを同時に取得することは、実践的には困難です。事前トレーニングデータを十分に収集するために、[chart、code]および[chart、table]のペアを独立して蓄積します。[chart、code]の場合、適切なライセンスを持つすべてのGitHub IPythonノートブックをクロールし、図を含むブロックを抽出します。図とそれに直前にあるコードブロックは、[chart、code]ペアとして保存されます。[chart、table]のペアについては、2つのソースを調査しました。最初のソースは、合成データで、TaPasコードベースからWebクロールされたWikipediaテーブルを手動でコードに変換します。列のタイプに応じて、いくつかのプロットオプションをサンプリングして組み合わせます。さらに、事前トレーニングコーパスを多様化するために、PlotQAで生成された[chart、table]ペアも追加します。2番目のソースはWebクロールされた[chart、table]ペアです。Statista、Pew、Our World in Data、OECDの4つのWebサイトから合計約20,000ペアを含むChartQAトレーニングセットでクロールされた[chart、table]ペアを直接使用します。 数学的推論 MatChaに数値推論知識を組み込むために、テキスト数学データセットから数学的推論スキルを学習します。事前トレーニングには、MATHとDROPの2つの既存のテキスト数学推論データセットを使用します。MATHは合成的に作成され、各モジュール(タイプ)の質問ごとに200万のトレーニング例を含んでいます。DROPは読解型のQAデータセットで、入力はパラグラフのコンテキストと質問です。 DROPでの質問を解決するには、モデルがパラグラフを読み、関連する数字を抽出し、数値計算を実行する必要があります。私たちは、両方のデータセットが補完的であることを発見しました。MATHには、異なるカテゴリーにわたる多数の質問が含まれており、モデルに明示的に注入する必要がある数学的操作を特定するのに役立ちます。DROPの読解形式は、モデルが情報抽出と推論を同時に実行する典型的なQA形式に似ています。実際には、両方のデータセットの入力を画像にレンダリングします。モデルは答えをデコードするように訓練されます。 MATHとDROPからの例をMatChaの事前トレーニング目的に取り込むことにより、MatChaの数学的推論スキルを向上させます。入力テキストを画像としてレンダリングします。 エンドツーエンドの結果 Webサイト理解に特化した画像からテキストへの変換トランスフォーマーであるPix2Structモデルバックボーンを使用し、上記の2つのタスクで事前トレーニングを行います。MatChaの強みを示すために、表の基礎にアクセスできない質問応答や要約のためのチャートやプロットを含むいくつかの視覚言語タスクで微調整します。MatChaは、以前のモデルの性能を大幅に上回り、基礎となるテーブルにアクセスできると仮定する以前の最先端も上回ります。 以下の図では、チャートと作業するための標準的なアプローチであったOCRパイプラインから情報を取り込んだ2つのベースラインモデルを最初に評価します。最初のものはT5に基づき、2番目のものはVisionTaPasに基づきます。また、PaLI-17BとPix2Structのモデル結果を報告します。PaLI-17Bは、多様なタスクでトレーニングされた大型(他のモデルの約1000倍)のイメージプラステキスト・トゥ・テキスト・トランスフォーマーですが、テキストやその他の視覚言語の読み取り能力に限界があります。最後に、Pix2StructとMatChaのモデル結果を報告します。…
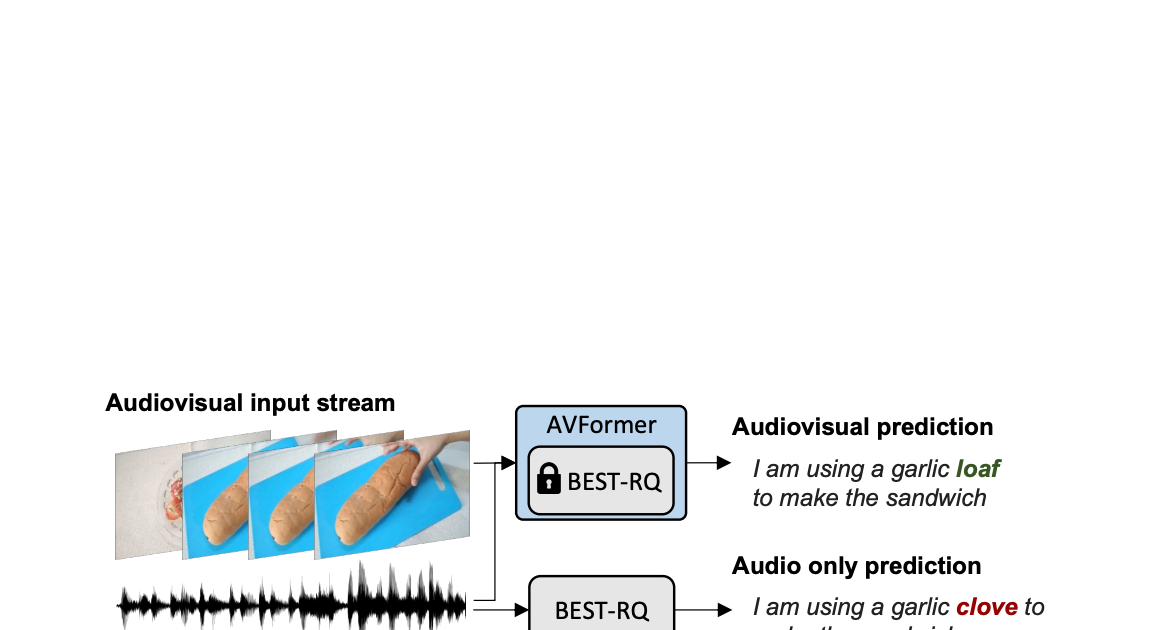
AVFormer:凍結した音声モデルにビジョンを注入して、ゼロショットAV-ASRを実現する
Google Researchの研究科学者、Arsha NagraniとPaul Hongsuck Seoによる投稿 自動音声認識(ASR)は、会議通話、ストリームビデオの転写、音声コマンドなど、さまざまなアプリケーションで広く採用されている確立された技術です。この技術の課題は、ノイズのあるオーディオ入力に集中していますが、マルチモーダルビデオ(テレビ、オンライン編集ビデオなど)の視覚ストリームはASRシステムの堅牢性を向上させる強力な手がかりを提供することができます。これをオーディオビジュアルASR(AV-ASR)と呼びます。 唇の動きは音声認識に強力な信号を提供し、AV-ASRの最も一般的な焦点であるが、野外のビデオで口が直接見えないことがよくあります(例えば、自己中心的な視点、顔のカバー、低解像度など)ため、新しい研究領域である拘束のないAV-ASR(AVATARなど)が誕生し、口の領域だけでなく、ビジュアルフレーム全体の貢献を調査しています。 ただし、AV-ASRモデルをトレーニングするためのオーディオビジュアルデータセットを構築することは困難です。How2やVisSpeechなどのデータセットはオンラインの教育ビデオから作成されていますが、サイズが小さいため、モデル自体は通常、ビジュアルエンコーダーとオーディオエンコーダーの両方から構成され、これらの小さなデータセットで過剰適合する傾向があります。それにもかかわらず、オーディオブックから取得した大量のオーディオデータを用いた大規模なトレーニングによって強く最適化された最近リリースされた大規模なオーディオモデルがいくつかあります。LibriLightやLibriSpeechなどがあります。これらのモデルには数十億のパラメータが含まれ、すぐに利用可能であり、ドメイン間で強い汎化性能を示します。 上記の課題を考慮して、私たちは「AVFormer:ゼロショットAV-ASRの凍結音声モデルにビジョンを注入する」と題した論文で、既存の大規模なオーディオモデルにビジュアル情報を付加するシンプルな方法を提案しています。同時に、軽量のドメイン適応を行います。AVFormerは、軽量のトレーニング可能なアダプタを使用して、視覚的な埋め込みを凍結されたASRモデルに注入します(Flamingoが大規模な言語モデルに視覚テキストタスクのためのビジュアル情報を注入する方法と似ています)。これにより、最小限の追加トレーニング時間とパラメータで弱くラベル付けられた少量のビデオデータでトレーニング可能です。トレーニング中のシンプルなカリキュラムスキームも紹介し、オーディオとビジュアルの情報を効果的に共同処理できるようにするために重要であることを示します。その結果、AVFormerモデルは、3つの異なるAV-ASRベンチマーク(How2、VisSpeech、Ego4D)で最新のゼロショットパフォーマンスを達成し、同時に伝統的なオーディオのみの音声認識ベンチマーク(LibriSpeechなど)のまともなパフォーマンスを保持しています。 拘束のないオーディオビジュアル音声認識。軽量モジュールを使用して、ビジョンを注入して、オーディオビジュアルASRのゼロショットを実現するために、Best-RQ(灰色)の凍結音声モデルにビジョンを注入します。AVFormer(青)というパラメーターとデータ効率の高いモデルが作成されます。オーディオ信号がノイズの場合、視覚的なパンの生成トランスクリプトでオンリーミステイク「クローブ」を「ローフ」に修正するのに役立つ視覚的なパンが役立つ場合があります。 軽量モジュールを使用してビジョンを注入する 私たちの目標は、既存のオーディオのみのASRモデルにビジュアル理解能力を追加しながら、その汎化性能を各ドメイン(AVおよびオーディオのみのドメイン)に維持することです。 このために、既存の最新のASRモデル(Best-RQ)に次の2つのコンポーネントを追加します:(i)線形ビジュアルプロジェクター、および(ii)軽量アダプター。前者は、オーディオトークン埋め込みスペースにおける視覚的な特徴を投影します。このプロセスにより、別々に事前トレーニングされたビジュアル機能とオーディオ入力トークン表現を適切に接続することができます。後者は、その後最小限の変更で、ビデオのマルチモーダル入力を理解するためにモデルを変更します。その後、これらの追加モジュールを、HowTo100Mデータセットからのラベル付けされていないWebビデオとASRモデルの出力を擬似グラウンドトゥルースとして使用してトレーニングし、Best-RQモデルの残りを凍結します。このような軽量モジュールにより、データ効率と強力なパフォーマンスの汎化が可能になります。 我々は、AV-ASRベンチマークにおいて、モデルが人手で注釈付けされたAV-ASRデータセットで一度もトレーニングされていないゼロショット設定で、拡張モデルを評価しました。 ビジョン注入のためのカリキュラム学習 初期評価後、私たちは経験的に、単純な一回の共同トレーニングでは、モデルがアダプタとビジュアルプロジェクタの両方を一度に学習するのが困難であることがわかりました。この問題を緩和するために、私たちは、これら2つの要因を分離し、ネットワークを順序良くトレーニングする2段階のカリキュラム学習戦略を導入しました。最初の段階では、アダプタパラメータが全くフィードされずに最適化されます。アダプタがトレーニングされたら、ビジュアルトークンを追加し、トレーニング済みのアダプタを凍結したまま第2段階でビジュアルプロジェクションレイヤーのみをトレーニングします。 最初の段階は、音声ドメイン適応に焦点を当てています。第2段階では、アダプタが完全に凍結され、ビジュアルプロジェクタは、ビジュアルトークンをオーディオ空間に投影するためのビジュアルプロンプトを生成することを学習する必要があります。このように、私たちのカリキュラム学習戦略は、モデルがAV-ASRベンチマークでビジュアル入力を統合し、新しい音声ドメインに適応することを可能にします。私たちは、交互に適用する反復的な適用では性能が低下するため、各段階を1回だけ適用します。 AVFormerの全体的なアーキテクチャとトレーニング手順。アーキテクチャは、凍結されたConformerエンコーダー・デコーダーモデル、凍結されたCLIPエンコーダー(グレーのロックシンボルで示される凍結層を持つ)、および2つの軽量トレーニング可能なモジュールで構成されています。-(i)ビジュアルプロジェクションレイヤー(オレンジ)およびボトルネックアダプタ(青)を有効にし、多モーダルドメイン適応を可能にします。私たちは、2段階のカリキュラム学習戦略を提案しています。最初に、アダプタ(青)をビジュアルトークンなしでトレーニングします。その後、ビジュアルプロジェクションレイヤー(オレンジ)を調整し、他のすべての部分を凍結したままトレーニングします。 下のプロットは、カリキュラム学習なしでは、AV-ASRモデルがすべてのデータセットでオーディオのみのベースラインよりも劣っており、より多くのビジュアルトークンが追加されるにつれてその差が拡大することを示しています。一方、提案された2段階のカリキュラムが適用されると、AV-ASRモデルは、オーディオのみのベースラインよりも遥かに優れたパフォーマンスを発揮します。 カリキュラム学習の効果。赤と青の線はオーディオビジュアルモデルであり、ゼロショット設定で3つのデータセットに表示されます(WER%が低い方が良いです)。カリキュラムを使用すると、すべての3つのデータセットで改善します(How2(a)およびEgo4D(c)では、オーディオのみのパフォーマンスを上回るために重要です)。4つのビジュアルトークンまで性能が向上し、それ以降は飽和します。 ゼロショットAV-ASRでの結果 私たちは、How2、VisSpeech、Ego4Dの3つのAV-ASRベンチマークで、zero-shotパフォーマンスのために、BEST-RQ、私たちのモデルの音声バージョン、およびAVATARを比較しました。AVFormerは、すべてのベンチマークでAVATARとBEST-RQを上回り、BEST-RQでは600Mパラメータをトレーニングする必要がありますが、AVFormerはわずか4Mパラメータしかトレーニングせず、トレーニングデータセットのわずか5%しか必要としません。さらに、音声のみのLibriSpeechでのパフォーマンスも評価し、AVFormerは両方のベースラインを上回ります。 AV-ASRデータセット全体におけるゼロショット性能に対する最新手法との比較。音声のみのLibriSpeechのパフォーマンスも示します。結果はWER%(低い方が良い)として報告されています。 AVATARとBEST-RQはHowTo100Mでエンドツーエンド(すべてのパラメータ)で微調整されていますが、AVFormerは微調整されたパラメータの少ないセットのおかげで、データセットの5%でも効果的に機能します。…

多言語での音声合成の評価には、SQuIdを使用する
Googleの研究科学者Thibault Sellamです。 以前、私たちは1000言語イニシアチブとUniversal Speech Modelを紹介しました。これらのプロジェクトは、世界中の何十億人ものユーザーに音声および言語技術を提供することを目的としています。この取り組みの一部は、多様な言語を話すユーザー向けにVDTTSやAudioLMなどのプロジェクトをベースにした高品質の音声合成技術を開発することにあります。 新しいモデルを開発した後は、生成された音声が正確で自然であるかどうかを評価する必要があります。コンテンツはタスクに関連し、発音は正確で、トーンは適切で、クラックや信号相関ノイズなどの音響アーティファクトはない必要があります。このような評価は、多言語音声システムの開発において大きなボトルネックとなります。 音声合成モデルの品質を評価する最も一般的な方法は、人間の評価です。テキストから音声(TTS)エンジニアが最新のモデルから数千の発話を生成し、数日後に結果を受け取ります。この評価フェーズには、聴取テストが含まれることが一般的で、何十もの注釈者が一つずつ発話を聴取して、自然な音に聞こえるかどうかを判断します。人間はテキストが自然かどうかを検出することでまだ敵わないことがありますが、このプロセスは実用的ではない場合があります。特に研究プロジェクトの早い段階では、エンジニアがアプローチをテストして再戦略化するために迅速なフィードバックが必要な場合があります。人間の評価は費用がかかり、時間がかかり、対象言語の評価者の可用性によって制限される場合があります。 進展を妨げる別の障壁は、異なるプロジェクトや機関が通常、異なる評価、プラットフォーム、およびプロトコルを使用するため、apple-to-applesの比較が不可能であることです。この点で、音声合成技術はテキスト生成に遅れを取っており、研究者らが人間の評価をBLEUや最近ではBLEURTなどの自動評価指標と補完して長年にわたって利用してきたテキスト生成から大きく遅れています。 「SQuId: Measuring Speech Naturalness in Many Languages」でICASSP 2023に発表する予定です。SQuId(Speech Quality Identification)という600Mパラメーターの回帰モデルを紹介します。このモデルは、音声がどの程度自然かを示します。SQuIdは、Googleによって開発された事前学習された音声テキストモデルであるmSLAMをベースにしており、42言語で100万件以上の品質評価をファインチューニングし、65言語でテストされました。SQuIdが多言語の評価において人間の評価を補完するためにどのように使用できるかを示します。これは、今までに行われた最大の公開努力です。 SQuIdによるTTSの評価 SQuIdの主な仮説は、以前に収集された評価に基づいて回帰モデルをトレーニングすることで、TTSモデルの品質を評価するための低コストな方法を提供できるということです。このモデルは、TTS研究者の評価ツールボックスに貴重な追加となり、人間の評価に比べて正確性は劣るものの、ほぼ即時に提供されます。 SQuIdは、発話を入力とし、オプションのロケールタグ(つまり、”Brazilian Portuguese”や”British English”などのローカライズされた言語のバリアント)を指定することができます。SQuIdは、音声波形がどの程度自然に聞こえるかを示す1から5までのスコアを返します。スコアが高いほど、より自然な波形を示します。 内部的には、モデルには3つのコンポーネントが含まれています:(1)エンコーダー、(2)プーリング/回帰層、および(3)完全接続層。最初に、エンコーダーはスペクトログラムを入力として受け取り、1,024サイズの3,200ベクトルを含む小さな2D行列に埋め込みます。各ベクトルは、時間ステップをエンコードします。プーリング/回帰層は、ベクトルを集約し、ロケールタグを追加し、スコアを返す完全接続層に入力します。最後に、アプリケーション固有の事後処理を適用して、スコアを再スケーリングまたは正規化して、自然な評価の範囲である[1、5]の範囲内に収まるようにします。回帰損失で全モデルをエンドツーエンドでトレーニングします。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.