Learn more about Search Results ML - Page 260

- You may be interested
- GPT-4の進化:Python Plotlyダッシュボー...
- 昇進しました! (Shōshin shimashita!)
- インタラクティブな知能の模倣
- 「AWSを基にしたカスケーディングデータパ...
- テック業界でデータサイエンティストの仕...
- 「MITとNVIDIAの研究者が、要求の厳しい機...
- 「スコア!チームNVIDIAが推薦システムで...
- モデルオプスとは何ですか?
- ソートアルゴリズムの概要:マージソート
- 光ベースのコンピューティング革命:強化...
- イェール大学とGoogle DeepMindの研究者は...
- 「大規模言語モデルの世界でどのように仕...
- バードの未来展望:よりグローバルで、よ...
- 「関係深層学習ベンチマーク(RelBench)...
- 「時系列分析のための欠落した日付の修正...

「Amazon Web Servicesでの生成型AIアプリの構築 – 私の最初の経験」
オーストラリアの「ビッグフォー」銀行のエンジニア兼データサイエンティストとして、過去1か月間だけでこのようなエキサイティングなイベントに3回も引っ張り込まれましたこれらのイベントは、会社の...

「大規模な言語モデルは、長い形式の質問応答においてどのようにパフォーマンスを発揮するのか?Salesforceの研究者によるLLMの頑健性と能力についての詳細な解説」
大規模な言語モデル(LLM)であるChatGPTやGPT-4は、いくつかのベンチマークでより優れたパフォーマンスを示していますが、MMLUやOpenLLMBoardなどのオープンソースプロジェクトも、さまざまなアプリケーションやベンチマークで追いつくことが急速に進んでいます。彼らの能力、制約、および区別を理解することは、新しいモデルや手法の急速な進歩が進むLLMの新時代においてますます重要になってきます。LLMは要約などのタスクで一貫したテキストを生成する能力を示していますが、LFQAでの実績についてはさらなる情報が必要です。 まだ解決されていない重要な問題の1つは、長文の質問応答(LFQA)です。これには多くの現実世界の応用(サポートフォーラム、トラブルシューティング、カスタマーサービスなど)があります。このような質問に答えるためには、複雑な思考スキルが必要であり、質問を理解し、原稿全体に分散している内容を把握する必要があります。記事の主要なポイントは要約にまとめられます。これらの要約からの追加の質問は、ソース素材のさまざまなセクションを結び付ける主題のより良い理解を必要とすると仮定されています。また、他の研究者は、長い素材の3分の1以上の理解を必要とする応答は、人々からはしばしば「難しい」と評価されると示しています。 Salesforceの研究者は、巨大なLLMとより小さなが成功した基本的なLLM(Llama-7B、13Bなど)およびそれらの蒸留対応物(Alpaca-7B、13Bなど)の違いを比較し、対比するためのスケーラブルな評価手法を提案しています。これを行うために、彼らはChatGPTが明示的に指示され、要約から複雑な質問を作成するように指示します。彼らの実証的な研究は、要約から作成された追加の質問が、LLMの推論スキルを評価するための難しいがより現実的なセットアップを提供することを示しています(生成された質問の複雑さとオープンソースLLMの応答品質)。彼らはGPT-4を使用して、以前の作品の下での結束性、関連性、事実の一貫性、正確さに対する応答品質を決定します。これは、長文QAのために完全に人間のレビューに依存することは費用がかかり、スケーリングが困難であるためです。彼らはまた、より小規模な人間の評価を行い、GPT-4が人間の評価と強く相関することを示し、評価が信頼性のあるものであることを示しています。 この研究からの主な結論は次のとおりです: • 抽象的な要約から質問を生成するために、文脈を複数回通過することで長い文脈からの推論を推奨します(時間の20%以上)。 • 蒸留対応のLLM(Alpaca-7B、13B)は、元のマテリアルから質問を生成する際には文脈に依存することが少ないですが、要約から質問を作成する能力は大幅に低下します。 • 要約から派生した質問に対して(16.8%以上)、蒸留対応のLLMによって生成された応答は文脈によって一貫している場合がありますが、しばしば主題から逸れ、冗長な回答を生成し、部分的に正確です。 • Alpaca-7Bと13Bは、基本的なLLM(Llama)よりも長い文脈(1024トークン以上)に対してより敏感であり、通常は理にかなった応答を生成します。

「Hugging FaceはLLMのための新しいGitHubです」
ハギングフェイスは、大規模言語モデル(LLM)のための「GitHub」となりつつありますハギングフェイスは、LLMの開発と展開を簡素化するツールを提供しています

「Cを使用してLLMsを最適化し、GPT、Lama、Whisperを自分のラップトップで実行する」
大規模言語モデル(LLM)はどこでも話題になっています新聞は新たな到来する世界を説明するために大量の言葉を使っており、「AIはついに到着した」と保証していますしかし、LLMは...

「アメリカで最も優れた5つのデータサイエンスの認定資格」
イントロダクション アメリカでは、データサイエンスは機会の宝庫です。Glassdoorによれば、データサイエンティストは4年間で最も求められる役割の一つとして常にランクインしています。アメリカ労働統計局は2032年までにデータサイエンスの仕事が35%の割合で成長すると予測しています。この記事では、アメリカでのトップ5のデータサイエンス認定資格について探求し、この急成長する分野で成功するために必要な知識とスキルを提供します。経験豊富なデータプロフェッショナルであるか、データの旅を始めたばかりであっても、これらの認定資格はデータサイエンス革命における繁栄するキャリアへの道を提供します。 アメリカにおけるデータサイエンス認定の重要性 データサイエンスの認定は、数多くの魅力的な理由からアメリカで非常に重要です。まず第一に、データサイエンスのスキルと知識を検証し、潜在的な雇用主にあなたの専門知識の具体的な証拠を提供します。競争の激しい就職市場では、認定資格があることで他の候補者から差別化され、データサイエンスの求人に就く可能性が高まります。 さらに、データサイエンスは多くのツール、技術、手法が急速に進化している分野です。認定資格は構造化された学習パスを提供し、最新の進展やベストプラクティスに常にアップデートされた状態を保つことを保証します。実際のデータの課題に効果的に取り組むための実践的なスキルを身につけることができます。 データサイエンスの求人機会が豊富なアメリカでは、認定資格はキャリアの加速剤となります。多くの雇用主は、これらの資格は卓越性への取り組みと分野への強固な基盤を示しており、認定されたデータ専門家を積極的に求めています。 さらに、データサイエンスの認定資格によりキャリアの柔軟性を得ることができます。金融から医療まで、さまざまな産業で認識されており、異なるセクターにスムーズに移行することができます。 また、次も読んでみてください:アメリカでデータサイエンティストになる方法 アメリカのトップ5のデータサイエンス認定資格 認定AI MLブラックベルト+プログラム ビジネスマネージャー向けデータサイエンス入門 認定機械学習マスタープログラム(MLMP) アナリストとデータサイエンティスト向けトップデータサイエンスプロジェクト データサイエンスプロフェッショナル向けGitとGitHubのはじめ方 認定AI MLブラックベルト+プログラム このプログラムは、あなたを熟練したAIおよび機械学習の実践者に変えるための包括的なコースを提供しています。初心者でも経験豊富なプロフェッショナルでも、このプログラムは必要なスキル、実践的な知識、現実世界のプロジェクトを身につけることができます。 このプログラムでは、データサイエンスと機械学習、ディープラーニング、自然言語処理(NLP)、コンピュータビジョン、Tableauによるデータの可視化、Excelの習熟度、データサイエンスのためのSQL、面接の準備など、重要なトピックをカバーしています。 なぜ認定AI&MLブラックベルト+プログラムを選ぶのか? AI革命を受け入れる:人工知能が産業や機能を再構築し続ける中で、AIおよび機械学習のスキル向上は必須です。このプログラムはそのための絶好の機会を提供します。 アクセスしやすいコンテンツ:コースは、さまざまなバックグラウンドを持つ個人を対象に細心の注意を払って設計されており、初心者でも簡単に理解することができます。 経験豊富な講師陣:プログラムの教材は、幅広い業界経験と数十年の教育経験を持つ講師によって作成されています。 産業の関連性:すべてのコースは業界の専門家によって審査されており、コンテンツが現在の高速な就職市場においても関連性が保たれることを保証しています。…

自己学習のためのデータサイエンスカリキュラム
はじめに データサイエンティストになる予定ですが、どこから始めればいいかわからないですか?心配しないでください、私たちがお手伝いします。この記事では、自己学習のためのデータサイエンスカリキュラム全体と、プロセスを早めるためのリソースとプログラムのリストをカバーします。 このカリキュラムでは、優れたデータサイエンティストになるために必要なツール、トリック、知識の基礎をカバーしています。もし科学と統計について少し知識があるなら、良い位置にいます。これらのことについて初めて知る場合は、まずそれらについて学ぶと役立つかもしれません。そして、既にデータに詳しい場合は、これはクイックな復習になるかもしれません。 覚えておいてください、すべてのプロジェクトでこれらのスキルをすべて使うわけではありません。一部のプロジェクトでは、このリストにない特別なトリックやツールが必要です。しかし、このカリキュラムの内容を十分に理解し、習得すると、ほとんどのデータサイエンスの仕事に対応できるようになります。そして、必要なときに新しいことを学ぶ方法も知っています。 さあ、始めましょう! データサイエンスカリキュラムをなぜフォローするのか? データサイエンスのカリキュラムに従うことは、構造化された効果的な学習には欠かせません。これにより、知識とスキルを習得するための明確なパスが提供され、この分野の広大さに圧倒されることなく学ぶことができます。良いカリキュラムは包括的なカバレッジを保証し、基礎的な概念から高度なテクニックまでを案内します。このステップバイステップのアプローチは、複雑なトピックに深入りする前に、堅固な基盤を築くための基礎となります。 さらに、カリキュラムは実践的な応用を促進します。多くのプログラムにはハンズオンのプロジェクトや演習が含まれており、理論的な知識を実世界のスキルに変換することができます。進捗を体系的に追跡することで、学習の旅においてモチベーションを保ち、集中する助けとなります。 即効的な利点を超えて、カリキュラムに従うことは職業にも役立ちます。データサイエンスの構造化された教育を完了することは、潜在的な雇用主に対してコミットメントと熟練度を示し、仕事の見通しを向上させます。さらに、このアプローチは適応性を育成し、自身のニーズに合わせてペースを調整し、困難なテーマに深入りすることができるようにします。 要するに、データサイエンスのカリキュラムは必須のスキルを身につけるだけでなく、データサイエンスの常に進化する分野で独立して学び続ける能力を養うことも可能です。 自己学習のためのデータサイエンスカリキュラム 以下は、データサイエンスの旅を始める際に探索するための主要な領域の簡略化されたロードマップです: 数学の基礎 多変数微積分:複数の変数の関数、導関数、勾配、ステップ関数、シグモイド関数、コスト関数などを理解する。 線形代数:ベクトル、行列、転置や逆行列などの行列演算、行列式、内積、固有値、固有ベクトルを習得する。 最適化手法:コスト関数、尤度関数、誤差関数などについて学び、勾配降下法(および確率的勾配降下法などの変種)などのアルゴリズムを理解する。 プログラミングの基礎 PythonまたはRを主要な言語として選択する。 Pythonの場合、NumPy、pandas、scikit-learn、TensorFlow、PyTorchなどのライブラリを習得する。 データの基礎 さまざまな形式(CSV、PDF、テキスト)でのデータ操作を学ぶ。 データのクリーニング、補完、スケーリング、インポート、エクスポート、Webスクレイピングのスキルを習得する。 PCAやLDAなどのデータ変換や次元削減の手法を探索する。 確率と統計の基礎…
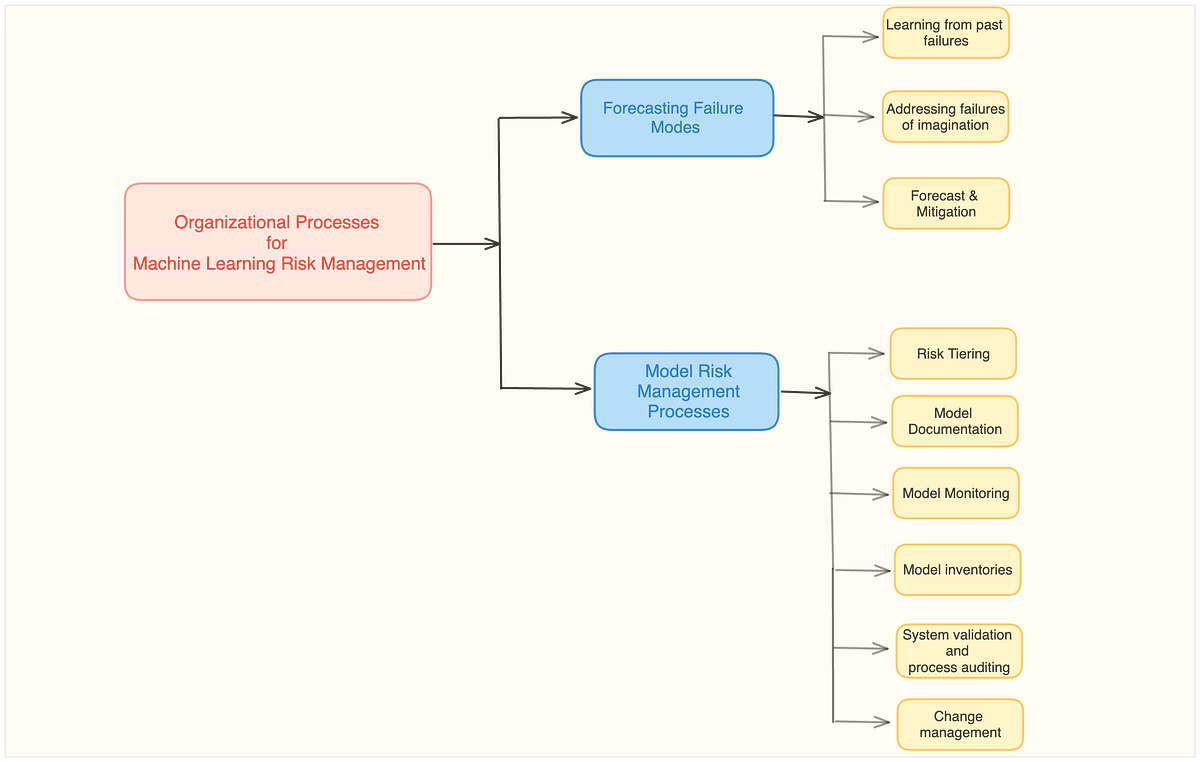
機械学習リスク管理の組織プロセス
「機械学習リスク管理シリーズでは、機械学習(ML)システムの信頼性を確保するための重要な要素を解明する旅に乗り出しました最初の...」

「機械学習プロジェクトのための最高のGitHubの代替品」
「GitHubに似た機能と機能を提供するいくつかのプラットフォームやサイトを見てみましょうこれらは簡単にGitHubに対抗できる堅牢な機能を備えています」

「Amazon SageMakerを使用したRLHFによるLLMsの改善」
このブログ投稿では、人気のあるオープンソースのRLHFリポTrlxを使用して、Amazon SageMaker上でRLHFを実行する方法を説明します私たちの実験を通じて、Anthropicが提供する公開可能なHelpfulness and Harmlessness(HH)データセットを使用して、大規模な言語モデルの役立ち度または無害性を向上させるためにRLHFを使用する方法を示しますこのデータセットを使用して、ml.p4d.24xlargeインスタンスで実行されているAmazon SageMaker Studioノートブックを使用して実験を行います最後に、私たちの実験を再現するためのJupyterノートブックを提供します

「心理学を活用してサイバーセキュリティを強化する」
攻撃者の心に入り込んで企業を守る
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.