Learn more about Search Results 同期 - Page 25

- You may be interested
- 「AIがあなたの問題を解決できるでしょう...
- 「大型言語モデルを使用して開発するため...
- 「データ資産のポートフォリオを構築およ...
- KAISTの研究者らが「SyncDiffusion」を提...
- 「Hugging Face Diffusersは、LoRAを正し...
- 「OpenAIのための自然言語からSQLへの変換...
- Amazon SageMakerを使用して、ML推論アプ...
- アテンションメカニズムを利用した時系列予測
- Mr. Pavan氏のデータエンジニアリングの道...
- AI時代の運転:AIへの恐怖が命を奪う代償...
- コードを解読する LLMs
- CVPR 2023におけるGoogle
- 「Googleバードは、YouTubeの動画を要約す...
- 最適化ストーリー:ブルーム推論
- 「Amazon QuickSightでワードクラウドとし...

インターネット上でのディープラーニング:言語モデルの共同トレーニング
Quentin LhoestさんとSylvain Lesageさんの追加の助けを得ています。 現代の言語モデルは、事前学習に多くの計算リソースを必要とするため、数十から数百のGPUやTPUへのアクセスなしでは入手することが不可能です。理論的には、複数の個人のリソースを組み合わせることが可能かもしれませんが、実際には、インターネット上の接続速度は高性能GPUスーパーコンピュータよりも遅いため、このような分散トレーニング手法は以前は限定的な成功しか収めていませんでした。 このブログ記事では、参加者のネットワークとハードウェアの制約に適応することができる新しい協力的な分散トレーニング方法であるDeDLOCについて説明します。私たちは、40人のボランティアを使ってベンガル語の言語モデルであるsahajBERTの事前学習を行うことで、実世界のシナリオでの成功を示します。ベンガル語の下流タスクでは、このモデルは数百の高級アクセラレータを使用したより大きなモデルとほぼ同等のクオリティを実現しています。 オープンコラボレーションにおける分散深層学習 なぜやるべきなのか? 現在、多くの高品質なNLPシステムは大規模な事前学習済みトランスフォーマーに基づいています。一般的に、その品質はサイズとともに向上します。パラメータ数をスケールアップし、未ラベルのテキストデータの豊富さを活用することで、自然言語理解や生成において類を見ない結果を実現することができます。 残念ながら、これらの事前学習済みモデルを使用するのは、便利なだけではありません。大規模なデータセットでのトランスフォーマーのトレーニングに必要なハードウェアリソースは、一般の個人やほとんどの商業または研究機関には手の届かないものです。例えば、BERTのトレーニングには約7000ドルかかると推定され、GPT-3のような最大のモデルでは、この数は1200万ドルにもなります!このリソースの制約は明らかで避けられないもののように思えますが、広範な機械学習コミュニティにおいて事前学習済みモデル以外の代替手段は本当に存在しないのでしょうか? ただし、この状況を打破する方法があるかもしれません。解決策を見つけるために、周りを見渡すだけで十分かもしれません。求めている計算リソースは既に存在している可能性があるかもしれません。たとえば、多くの人々は自宅にゲームやワークステーションのGPUを搭載したパワフルなコンピュータを持っています。おそらく、私たちがFolding@home、Rosetta@home、Leela Chess Zero、または異なるBOINCプロジェクトのように、ボランティアコンピューティングを活用することで、彼らのパワーを結集しようとしていることはお分かりいただけるかもしれませんが、このアプローチはさらに一般的です。たとえば、いくつかの研究所は、自身の小規模なクラスタを結集して利用することができますし、低コストのクラウドインスタンスを使用して実験に参加したい研究者もいるかもしれません。 疑い深い考え方をすると、ここで重要な要素が欠けているのではないかと思うかもしれません。分散深層学習においてデータ転送はしばしばボトルネックとなります。複数のワーカーから勾配を集約する必要があるためです。実際、インターネット上での分散トレーニングへの単純なアプローチは必ず失敗します。ほとんどの参加者はギガビットの接続を持っておらず、いつでもネットワークから切断される可能性があるためです。では、家庭用のデータプランで何かをトレーニングする方法はどうすればいいのでしょうか? 🙂 この問題の解決策として、私たちは新しいトレーニングアルゴリズム、Distributed Deep Learning in Open Collaborations(またはDeDLOC)を提案しています。このアルゴリズムの詳細については、最近公開されたプレプリントで詳しく説明しています。では、このアルゴリズムの中核となるアイデアについて見てみましょう! ボランティアと一緒にトレーニングする 最も頻繁に使用される形態の分散トレーニングにおいては、複数のGPUを使用したトレーニングは非常に簡単です。ディープラーニングを行う場合、通常はトレーニングデータのバッチ内の多くの例について損失関数の勾配を平均化します。データ並列の分散DLの場合、データを複数のワーカーに分割し、個別に勾配を計算し、ローカルのバッチが処理された後にそれらを平均化します。すべてのワーカーで平均勾配が計算されたら、モデルの重みをオプティマイザで調整し、モデルのトレーニングを続けます。以下に、実行されるさまざまなタスクのイラストを示します。 多くの場合、同期の量を減らし、学習プロセスを安定化させるために、ローカルのバッチを平均化する前にNバッチの勾配を蓄積することができます。これは実際のバッチサイズをN倍にすることと同等です。このアプローチは、最先端の言語モデルのほとんどが大規模なバッチを使用しているという観察と組み合わせることで、次のようなシンプルなアイデアに至りました。各オプティマイザステップの前に、すべてのボランティアのデバイスをまたいで非常に大規模なバッチを蓄積しましょう!この方法は、通常の分散トレーニングと完全に等価であり、簡単にスケーラビリティを実現するだけでなく、組み込みの耐障害性も持っています。以下に、それを説明する例を示します。 共同の実験中に遭遇する可能性のあるいくつかの故障ケースを考えてみましょう。今のところ、最も頻繁なシナリオは、1人または複数の参加者がトレーニング手続きから切断されることです。彼らは不安定な接続を持っているか、単に自分のGPUを他の用途に使用したいだけかもしれません。この場合、トレーニングにはわずかな遅れが生じますが、これらの参加者の貢献は現在蓄積されているバッチサイズから差し引かれます。しかし、他の参加者が彼らの勾配でそれを補ってくれるでしょう。また、さらに多くの参加者が加わる場合、目標のバッチサイズは単純により速く達成され、トレーニング手続きは自然にスピードアップします。これを以下のビデオでデモンストレーションしています。…

モダンなCPU上でのBERTライクモデルの推論のスケーリングアップ – パート2
イントロダクション:CPU上でのAI効率を最適化するためのIntelソフトウェアの使用 前のブログ記事で詳細に説明したように、Intel Xeon CPUは、AVX512やVNNI(Vector Neural Network Instructions)などのAIワークロードに特に設計された機能を提供しており、整数量子化されたニューラルネットワークを使用した効率的な推論をサポートするための追加のシステムツールも提供しています。このブログ記事では、ソフトウェアの最適化に焦点を当て、Intelの新しいIce Lake世代のXeon CPUのパフォーマンスについて紹介します。私たちの目標は、Intelのハードウェアを最大限に活用するためにソフトウェア側で利用可能なものをすべて紹介することです。前のブログ記事と同様に、ベンチマークの結果とグラフとともに、これらのツールと機能を簡単に使用できるようにします。 4月にIntelは最新のIntel Xeonプロセッサ、コードネームIce Lakeを発売しました。これはより効率的で高性能なAIワークロードをターゲットにしています。具体的には、Ice Lake Xeon CPUは、以前のCascade Lake Xeonプロセッサと比較して、さまざまなNLPタスクで最大75%高速な推論が可能です。これは、新しいSunny Coveアーキテクチャ上での新しい命令やPCIe 4.0のようなハードウェアおよびソフトウェアの改善の組み合わせによって実現されています。最後になりますが、Intelは、IntelのExtension for Scikit Learn、Intel TensorFlow、Intel PyTorch…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…

Intelのテクノロジーを使用して、PyTorchの分散ファインチューニングを高速化する
驚異的なパフォーマンスを持つ最先端のディープラーニングモデルでも、トレーニングには長い時間がかかることがよくあります。トレーニングジョブを高速化するために、エンジニアリングチームは分散トレーニングに頼っています。これは、クラスタ化されたサーバーがそれぞれモデルのコピーを保持し、トレーニングセットのサブセットでトレーニングを行い、結果を交換して最終的なモデルに収束するという分割統治技術です。 グラフィックプロセッシングユニット(GPU)は、ディープラーニングモデルのトレーニングにおいて長い間デファクトの選択肢でした。しかし、転移学習の台頭により、状況が変化しています。モデルは今や巨大なデータセットからゼロからトレーニングされることはほとんどありません。代わりに、特定の(より小さい)データセットで頻繁に微調整され、特定のタスクに対してベースモデルよりも精度の高い専用モデルが構築されます。これらのトレーニングジョブは短いため、CPUベースのクラスタを使用することは、トレーニング時間とコストの両方を管理するための興味深いオプションとなります。 この投稿の内容 この投稿では、インテル Xeon Scalable CPUサーバのクラスタ上でPyTorchのトレーニングジョブを分散して高速化する方法について説明します。Ice Lakeアーキテクチャを搭載し、パフォーマンス最適化されたソフトウェアライブラリを実行する仮想マシンを使用して、クラスタをゼロから構築します。クラウドまたはオンプレミスの環境で、簡単にデモを自身のインフラストラクチャに複製することができるはずです。 テキスト分類ジョブを実行し、MRPCデータセット(GLUEベンチマークに含まれるタスクの1つ)でBERTモデルを微調整します。MRPCデータセットには、ニュースソースから抽出された5,800の文のペアが含まれており、各ペアの2つの文が意味的に同等であるかどうかを示すラベルが付いています。このデータセットはトレーニング時間が合理的であり、他のGLUEタスクを試すのはパラメーターさえ変更すれば可能です。 クラスタが準備できたら、まずは単一のサーバーでベースラインのジョブを実行します。その後、2つのサーバーや4つのサーバーにスケールアップして、スピードアップを計測します。 途中で以下のトピックについて説明します: 必要なインフラストラクチャとソフトウェアのビルディングブロックのリストアップ クラスタのセットアップ 依存関係のインストール 単一ノードのジョブの実行 分散ジョブの実行 さあ、作業を始めましょう! インテルサーバの使用 最高のパフォーマンスを得るために、Ice Lakeアーキテクチャに基づいたインテルサーバを使用します。これには、Intel AVX-512やIntel Vector Neural Network…

Hugging Face TransformersとAWS Inferentiaを使用して、BERT推論を高速化する
ノートブック:sagemaker/18_inferentia_inference BERTとTransformersの採用はますます広がっています。Transformerベースのモデルは、自然言語処理だけでなく、コンピュータビジョン、音声、時系列でも最先端のパフォーマンスを達成しています。💬 🖼 🎤 ⏳ 企業は、大規模なワークロードのためにトランスフォーマーモデルを使用するため、実験および研究フェーズから本番フェーズにゆっくりと移行しています。ただし、デフォルトでは、BERTとその仲間は、従来の機械学習アルゴリズムと比較して、比較的遅く、大きく、複雑なモデルです。TransformersとBERTの高速化は、将来的に解決すべき興味深い課題となるでしょう。 AWSはこの課題を解決するために、最適化された推論ワークロード向けに設計されたカスタムマシンラーニングチップであるAWS Inferentiaを開発しました。AWSは、AWS Inferentiaが「現行世代のGPUベースのAmazon EC2インスタンスと比較して、推論ごとのコストを最大80%低減し、スループットを最大2.3倍高める」と述べています。 AWS Inferentiaインスタンスの真の価値は、各デバイスに搭載された複数のNeuronコアを通じて実現されます。Neuronコアは、AWS Inferentia内部のカスタムアクセラレータです。各Inferentiaチップには4つのNeuronコアが搭載されています。これにより、高スループットのために各コアに1つのモデルをロードするか、低レイテンシのためにすべてのコアに1つのモデルをロードすることができます。 チュートリアル このエンドツーエンドのチュートリアルでは、Hugging Face Transformers、Amazon SageMaker、およびAWS Inferentiaを使用して、テキスト分類のBERT推論を高速化する方法を学びます。 ノートブックはこちらでご覧いただけます:sagemaker/18_inferentia_inference 以下の内容を学びます: 1. Hugging Face TransformerをAWS Neuronに変換する 2.…
~自分自身を~ 繰り返さない
🤗 Transformersのデザイン哲学 「Don’t repeat yourself(同じことを繰り返さない)」、またはDRY(Don’t Repeat Yourself)は、ソフトウェア開発のよく知られた原則です。この原則は、「The pragmatic programmer」というコードデザインに関する最も読まれた本の1つから生まれました。この原則のシンプルなメッセージは明らかな意味を持っています。既に他の場所で存在するロジックを再書きする必要はありません。これにより、コードは同期され、メンテナンスが容易になり、より堅牢になります。この論理パターンへの変更は、依存関係のすべてに一様に影響を与えます。 Hugging FaceのTransformersライブラリの設計は、DRY原則とはまったく逆のものに見えるかもしれません。注意機構のコードは、異なるモデルファイルに50回以上もコピーされています。時にはBERTモデル全体のコードが他のモデルファイルにコピーされています。既存のモデルとほぼ同じ新しいモデルの貢献を強制的に行うことがよくありますが、それにはわずかな論理的な調整以外にも、すべての既存のコードをコピーする必要があります。なぜこれをやるのでしょうか?私たちは単に怠惰であるか、あるいは中心化された場所にすべての論理的な要素を集めることに圧倒されているのでしょうか? いいえ、私たちは怠惰ではありません。TransformersライブラリにDRYデザイン原則を適用しないというのは、非常に意識的な決定です。その代わりに、私たちは「シングルモデルファイル」ポリシーと呼ぶ別のデザイン原則を採用することにしました。シングルモデルファイルポリシーは、モデルの順方向パスに必要なすべてのコードが1つのファイル、つまりモデルファイルに含まれているというものです。推論でBERTがどのように機能するかを理解するためには、BERTのmodeling_bert.pyファイルを見ればよいだけです。異なるモデルの同一のサブコンポーネントを新しい中央集権化された場所に抽象化しようとする試みを通常は拒否します。すべての可能な注意メカニズムが含まれたattention_layer.pyを持つことはしたくありません。再び、なぜこれをやるのでしょうか? 短く言えば、その理由は次のとおりです: 1. Transformersはオープンソースコミュニティによって作られました。 2. 私たちの製品はモデルであり、顧客はモデルコードを読んだり調整したりするユーザーです。 3. 機械学習の世界は非常に速く進化しています。 4. 機械学習モデルは静的です。 1. オープンソースコミュニティによって作られました Transformersは、外部の貢献を積極的に促進するために作られています。貢献は通常、バグ修正または新しいモデルの貢献です。モデルファイルの1つでバグが見つかった場合、見つけた人が修正するのができるだけ簡単にすることを望んでいます。他のモデルの100のエラーを引き起こすことを見るのは、非常にやる気を削ぐことです。…
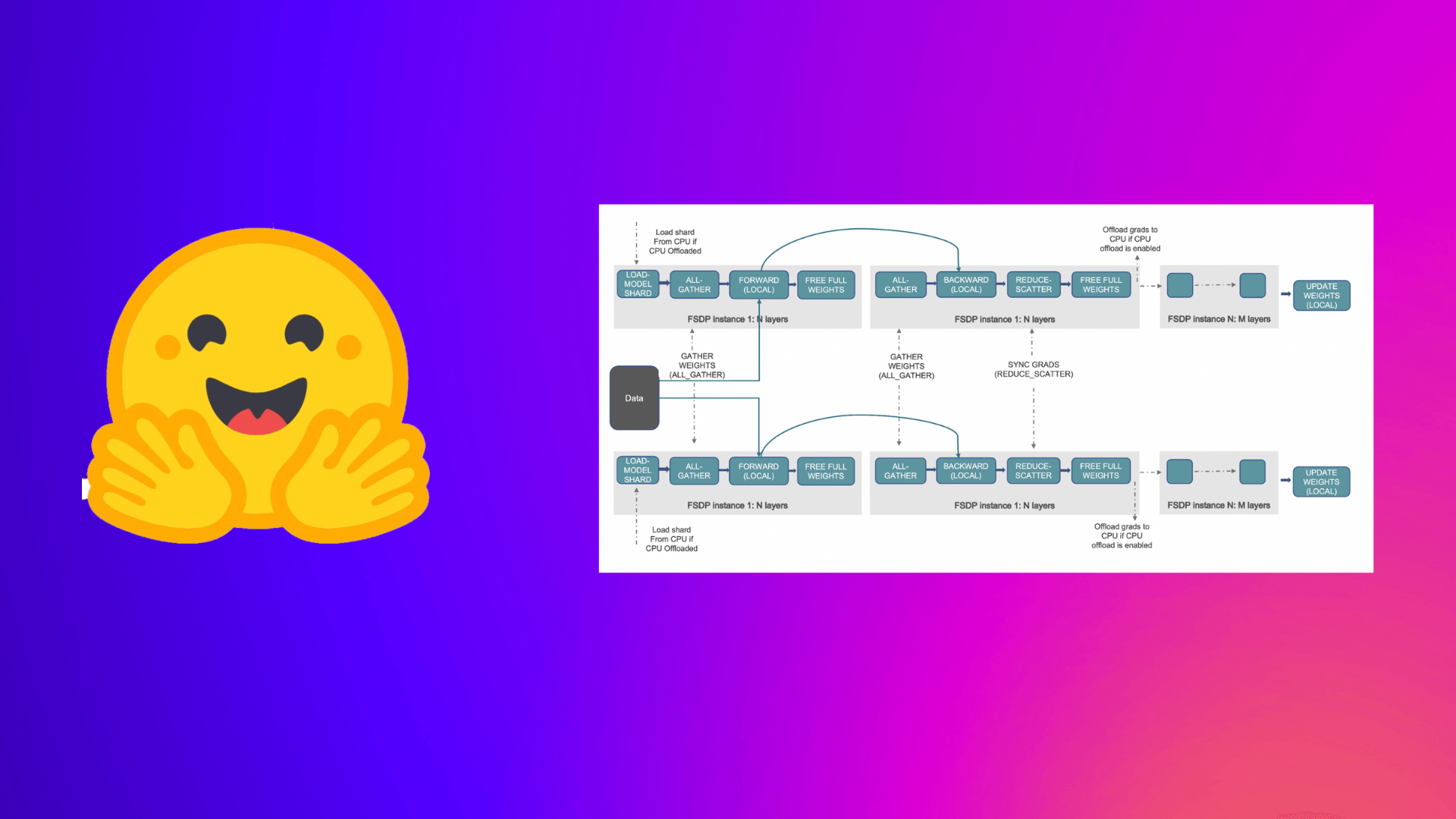
PyTorch完全にシャーディングされたデータパラレルを使用して、大規模モデルのトレーニングを加速する
この投稿では、Accelerate ライブラリを活用して大規模なモデルのトレーニングを行う方法について説明します。これにより、ユーザーは PyTorch FullyShardedDataParallel (FSDP) の最新機能を活用することができます。 機械学習 (ML) モデルのスケール、サイズ、およびパラメータがますます増加するにつれ、ML プラクティショナーは自身のハードウェア上でそのような大規模なモデルをトレーニングしたり、ロードしたりすることが困難になっています。 一方で、大規模なモデルは小さなモデルと比較して学習が速く(データと計算効率が高く)、パフォーマンスも著しく向上することがわかっています [1]。しかし、そのようなモデルをほとんどの利用可能なハードウェア上でトレーニングすることは困難です。 大規模なMLモデルをトレーニングするためには、分散トレーニングが重要です。 分散トレーニング の分野では、最近重要な進展がありました。最も注目すべき進展のいくつかは以下のとおりです: ZeROを用いたデータ並列化 – Zero Redundancy Optimizer [2] ステージ1:データ並列ワーカー/ GPU間でオプティマイザーの状態を分割 ステージ2:データ並列ワーカー/…

BLOOMトレーニングの技術背後
近年、ますます大規模な言語モデルの訓練が一般的になってきました。これらのモデルがさらなる研究のために公開されていない問題は頻繁に議論されますが、そのようなモデルを訓練するための技術やエンジニアリングについての隠された知識は滅多に注目されません。本記事では、1760億パラメータの言語モデルBLOOMを例に、そのようなモデルの訓練の裏側にあるハードウェアとソフトウェアの技術とエンジニアリングについて、いくつかの光を当てることを目指しています。 しかし、まず、この素晴らしい1760億パラメータモデルの訓練を可能にするために貢献してくれた企業や主要な人物やグループに感謝したいと思います。 その後、ハードウェアのセットアップと主要な技術的な構成要素について説明します。 以下はプロジェクトの要約です: 人々 このプロジェクトは、Hugging Faceの共同創設者でありCSOのThomas Wolf氏が考案しました。彼は巨大な企業と競争し、単なる夢だったものを実現し、最終的な結果をすべての人にアクセス可能にすることで、最も多くの人々にとっては夢であったものを実現しました。 この記事では、モデルの訓練のエンジニアリング側に特化しています。BLOOMの背後にある技術の最も重要な部分は、私たちにコーディングと訓練の助けを提供してくれた専門家の人々と企業です。 感謝すべき6つの主要なグループがあります: HuggingFaceのBigScienceチームは、数人の専任の従業員を捧げ、訓練を始めから終わりまで行うための方法を見つけるために、Jean Zayの計算機を超えるすべてのインフラストラクチャを提供しました。 MicrosoftのDeepSpeedチームは、DeepSpeedを開発し、後にMegatron-LMと統合しました。彼らの開発者たちはプロジェクトのニーズに多くの時間を費やし、訓練前後に素晴らしい実践的なアドバイスを提供しました。 NVIDIAのMegatron-LMチームは、Megatron-LMを開発し、私たちの多くの質問に親切に答えてくれ、一流の実践的なアドバイスを提供しました。 ジャン・ゼイのスーパーコンピュータを管理しているIDRIS / GENCIチームは、計算リソースをプロジェクトに寄付し、優れたシステム管理のサポートを提供しました。 PyTorchチームは、このプロジェクトのために基礎となる非常に強力なフレームワークを作成し、訓練の準備中に私たちをサポートし、複数のバグを修正し、PyTorchコンポーネントの使いやすさを向上させました。 BigScience Engineeringワーキンググループのボランティア プロジェクトのエンジニアリング側に貢献してくれたすべての素晴らしい人々を全て挙げることは非常に困難なので、Hugging Face以外のいくつかの主要な人物を挙げます。彼らはこのプロジェクトのエンジニアリングの基盤となりました。 Olatunji Ruwase、Deepak…

最適化ストーリー:ブルーム推論
この記事では、bloomをパワーアップする効率的な推論サーバーの裏側について説明します。 数週間にわたり、レイテンシーを5倍削減し(スループットを50倍に増やしました)、このような速度向上を達成するために私たちが経験した苦労やエピックな勝利を共有したかったです。 さまざまな人々が多くの段階で関与していたため、ここではすべてをカバーすることはできません。また、最新のハードウェア機能やコンテンツが定期的に登場するため、一部の内容は古くなっているか、まったく間違っている可能性があることをご了承ください。 もし、お好みの最適化手法が議論されていなかったり、正しく表現されていなかったりした場合は、お詫び申し上げます。新しいことを試してみたり、間違いを修正するために、ぜひお知らせください。 言うまでもなく、まず大きなモデルが最初にアクセス可能でなければ、それを最適化する理由はありません。これは、多くの異なる人々によってリードされた信じられないほどの取り組みでした。 トレーニング中にGPUを最大限に活用するために、いくつかの解決策が検討され、結果としてMegatron-Deepspeedが最終的なモデルのトレーニングに選ばれました。これは、コードがそのままではtransformersライブラリと互換性がない可能性があることを意味します。 元のトレーニングコードのため、通常行っていることの1つである既存のモデルをtransformersに移植することに取り組みました。目標は、トレーニングコードから関連する部分を抽出し、transformers内に実装することでした。この取り組みには「Younes」が取り組みました。これは、1ヶ月近くかかり、200のコミットが必要でした。 後で戻ってくるいくつかの注意点があります: 小さなモデルbigscience/bigscience-small-testingとbigscience/bloom-560mを用意する必要があります。これは非常に重要です。なぜなら、それらと一緒に作業するとすべてが高速化されるからです。 まず、最後のログがバイトまで完全に同じになることを望むことをあきらめる必要があります。PyTorchのバージョンがカーネルを変更し、微妙な違いを導入する可能性があり、異なるハードウェアでは異なるアーキテクチャのため異なる結果が得られる場合があります(コストの理由から常にA100 GPUで開発したくはないでしょう)。 すべてのモデルにとって、良い厳格なテストスイートを作ることは非常に重要です 私たちが見つけた最高のテストは、固定された一連のプロンプトを持つことでした。プロンプトを知っており、決定論的な結果が得られる必要があります。2つの生成物が同じであれば、小さなログの違いは無視できます。ドリフトが見られるたびに調査する必要があります。それは、あなたのコードがやるべきことをしていないか、または実際にそのモデルがドメイン外であるためにノイズに対してより敏感であるかのいずれかです。いくつかのプロンプトと十分に長いプロンプトがあれば、すべてのプロンプトを誤ってトリガーする可能性は低くなります。プロンプトが多ければ多いほど良く、プロンプトが長ければ長いほど良いです。 最初のモデル(small-testing)は、bloomと同じようにbfloat16であり、すべてが非常に似ているはずですが、それほどトレーニングされていないか、うまく機能しないため、出力が大きく変動します。そのため、これらの生成テストに問題がありました。2番目のモデルはより安定していましたが、bfloat16ではなくfloat16でトレーニングおよび保存されていました。そのため、2つの間にはエラーの余地があります。 完全に公平を期すために言えば、bfloat16→float16への変換は推論モードでは問題なさそうです(bfloat16は主に大きな勾配を扱うために存在しません)。 このステップでは、重要なトレードオフが発見され、実装されました。bloomは分散環境でトレーニングされたため、一部のコードはLinearレイヤー上でテンソル並列処理を行っており、単一のGPU上で同じ操作を実行すると異なる結果が得られていました。これを特定するのにかなりの時間がかかり、100%の準拠を選択した場合、モデルの速度が遅くなりましたが、少しの差がある場合は実行が速く、コードがシンプルになりました。設定可能なフラグを選択しました。 注:この文脈でのパイプライン並列処理(PP)は、各GPUがいくつかのレイヤーを所有し、各GPUがデータの一部を処理してから次のGPUに渡すことを意味します。 これで、動作可能なtransformersのクリーンなバージョンがあり、これに取り組むことができます。 Bloomは352GB(176Bパラメーターのbf16)のモデルであり、それに合わせるために少なくともそれだけのGPU RAMが必要です。一時的に小さなマシンでCPUにオフロードすることを検討しましたが、推論速度が桁違いに遅くなるため、それを取り下げました。 次に、基本的にはパイプラインを使用したかったのです。つまり、ドッグフーディングであり、これがAPIが常に裏で使用しているものです。 ただし、pipelinesは分散意識がありません(それがその目的ではありません)。オプションを簡単に話し合った後、新しく作成されたdevice_map="auto"を使用してモデルのシャーディングを管理するためにaccelerateを使用することにしました。いくつかのバグを修正し、transformersのコードを修正してaccelerateが正しい仕事をするのを助ける必要がありました。 これは、transformersのさまざまなレイヤーを分割し、各GPUにモデルの一部を与えて動作させることで機能します。つまり、GPU0が作業を行い、次にGPU1に引き渡し、それ以降同様に行います。 最終的には、上に小さなHTTPサーバーを置くことで、bloom(大規模なモデル)を提供できるようになりました!…

🧨 JAX / Flax での安定した拡散!
🤗 Hugging Face Diffusersはバージョン0.5.1からFlaxをサポートしています!これにより、Colab、Kaggle、またはGoogle Cloud PlatformなどのGoogle TPU上での超高速な推論が可能になります。 この投稿では、JAX / Flaxを使用して推論を実行する方法を示します。Stable Diffusionの動作詳細やGPUでの実行方法について詳細を知りたい場合は、このColabノートブックを参照してください。 一緒に進める場合は、上のボタンをクリックしてこの投稿をColabノートブックとして開きます。 まず、TPUバックエンドを使用していることを確認してください。このノートブックをColabで実行している場合は、上のメニューでランタイムを選択し、「ランタイムのタイプを変更」オプションを選択し、ハードウェアアクセラレータの設定でTPUを選択します。 JAXはTPUに限定されているわけではありませんが、TPUサーバーごとに8つのTPUアクセラレータが並列に動作するため、そのハードウェア上で輝きます。 セットアップ import jax num_devices = jax.device_count() device_type = jax.devices()[0].device_kind print(f"Found…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.