Learn more about Search Results 比較 - Page 258

- You may be interested
- オムニバースへ:Reallusionは、2方向のラ...
- Q-学習入門 第1部への紹介
- 2023年の最高のサイバーセキュリティニュ...
- AutoNLPとProdigyを使用したアクティブラ...
- 「Spotifyのデータサイエンティストによる...
- 「2023年の競争分析のためのトップツール」
- 「OECDレポート:AIによる高いリスクを持...
- 次世代の終わりのない学習者のベンチマーク化
- このAIニュースレターは、あなたが必要と...
- このAI研究は、高品質なビデオ生成のため...
- 言語ドメインにおける画期的かつオープン...
- 次のLangChainプロジェクトのための基本を...
- 「スタンフォード大学の研究者が言語モデ...
- 生成AIにおけるプロンプトエンジニアリン...
- 「Googleは、データの不適切な使用によるL...

AIの仕事を見つけるための最高のプラットフォーム
あなたのキャリアの目標、好みの仕事スタイル、およびAIの専門分野に依存するAIの仕事に最適なプラットフォームについてもっと学びましょう
Rにおける二元配置分散分析
二元分散分析(Two-way ANOVA)は、二つのカテゴリカル変数が量的連続変数に与える同時効果を評価することができる統計的方法です二元分散分析は…

より小さい相手による言語モデルからの知識蒸留に深く潜入する:MINILLMによるAIのポテンシャルの解放
大規模言語モデルの急速な発展による過剰な計算リソースの需要を減らすために、大きな先生モデルの監督の下で小さな学生モデルを訓練する知識蒸留は、典型的な戦略です。よく使われる2つのKDは、先生の予測のみにアクセスするブラックボックスKDと、先生のパラメータを使用するホワイトボックスKDです。最近、ブラックボックスKDは、LLM APIによって生成されたプロンプト-レスポンスペアで小さなモデルを最適化することで、励ましを示しています。オープンソースのLLMが開発されるにつれて、ホワイトボックスKDは、研究コミュニティや産業セクターにとってますます有用になります。なぜなら、学生モデルはホワイトボックスのインストラクターモデルからより良いシグナルを得るため、性能が向上する可能性があるためです。 生成的LLMのホワイトボックスKDはまだ調査されていませんが、小規模(1Bパラメータ)の言語理解モデルについては、主にホワイトボックスKDが調査されています。この論文では、彼らはLLMのホワイトボックスKDを調べています。彼らは、一般的なKDが課題を生成的に実行するLLMにとってより優れている可能性があると主張しています。シーケンスレベルモデルのいくつかの変種を含む標準的なKD目標は、教師と学生の分布の近似前方クルバック・ライブラー発散(KLD)を最小化し、KLとして知られています。教師分布p(y|x)と学生分布q(y|x)によってパラメータ化され、pがqのすべてのモードをカバーするように強制する。出力空間が有限の数のクラスを含むため、テキスト分類問題においてKLはよく機能します。したがって、p(y|x)とq(y|x)の両方に少数のモードがあることが保証されます。 しかし、出力空間がはるかに複雑なオープンテキスト生成問題では、p(y|x)はq(y|x)よりもはるかに広い範囲のモードを表す場合があります。フリーラン生成中、前方KLDの最小化は、qがpの空白領域に過剰な確率を与え、pの下で非常にありそうもないサンプルを生成することにつながる可能性があります。この問題を解決するために、コンピュータビジョンや強化学習で一般的に使用される逆KLD、KLを最小化することを提案しています。パイロット実験は、KLを過小評価することで、qがpの主要なモードを探し、空いている領域を低い確率で与えるように駆動することを示しています。 これは、LLMの言語生成において、学生モデルがインストラクター分布の長いテールバージョンを学習しすぎず、誠実さと信頼性が必要な実世界の状況で重要な応答の正確性に集中することを意味します。彼らは、ポリシーグラディエントで目標の勾配を生成してmin KLを最適化します。最近の研究では、PLMの最適化にポリシーオプティマイゼーションの効果が示されています。ただし、モデルのトレーニングはまだ過剰な変動、報酬のハッキング、および世代の長さのバイアスに苦しんでいることがわかりました。そのため、彼らは以下を含めます。 バリエーションを減らすための単一ステップの正則化。 報酬のハッキングを減らすためのティーチャー混合サンプリング。 長さのバイアスを減らすための長さ正規化。 広範なNLPタスクを含む指示に従う設定では、The CoAI Group、清華大学、Microsoft Researchの研究者は、MINILLMと呼ばれる新しい技術を提供し、パラメータサイズが120Mから13Bまでのいくつかの生成言語モデルに適用します。5つの指示に従うデータセットと評価のためのRouge-LおよびGPT-4フィードバックを使用します。彼らのテストは、MINILMがすべてのデータセットでベースラインの標準KDモデルを常に打ち負かすことを示しています(図1を参照)。さらに研究により、MINILLMは、より多様な長い返信を生成するのに適しており、露出バイアスが低く、キャリブレーションが向上していることがわかりました。モデルはGitHubで利用可能です。 図1は、MINILLMとシーケンスレベルKD(SeqKD)の評価セットでの平均GPT-4フィードバックスコアの比較を示しています。左側にはGPT-2-1.5Bがあり、生徒としてGPT-2 125M、340M、および760Mが動作します。中央には、GPT-2 760M、1.5B、およびGPT-Neo 2.7Bが生徒であり、GPT-J 6Bがインストラクターです。右側にはOPT 13Bがあり、生徒としてOPT 1.3B、2.7B、および6.7Bが動作しています。
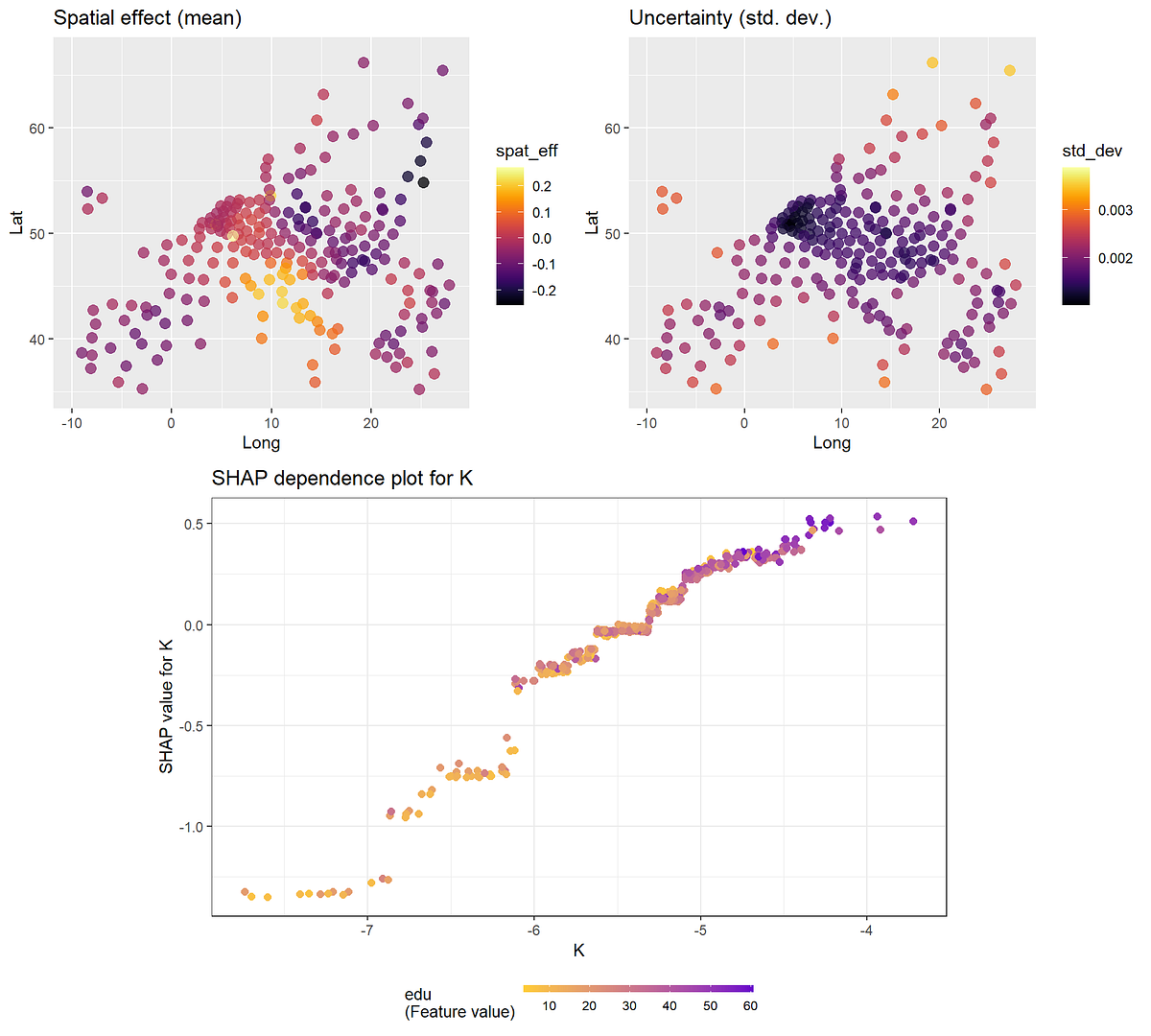
グループ化および空間計量データの混合効果機械学習におけるGPBoost
GPBoostを用いたグループ化されたおよび地域空間計量データの混合効果機械学習 - ヨーロッパのGDPデータを用いたデモ
PythonからJuliaへ:基本的なデータ操作とEDA
統計計算の領域でエマージングなプログラミング言語として、Julia は近年ますます注目を集めています他の言語に優る2つの特徴があります...

LlamaIndex インデックスと検索のための究極のLLMフレームワーク
LlamaIndex(以前はGPT Indexとして知られていました)は、データ取り込みを容易にする必須ツールを提供することで、LLMを使用したアプリケーションの構築を支援する注目すべきデータフレームワークです

アテンションメカニズムを利用した時系列予測
はじめに 時系列予測は、金融、気象予測、株式市場分析、リソース計画など、さまざまな分野で重要な役割を果たしています。正確な予測は、企業が情報に基づいた決定を行い、プロセスを最適化し、競争上の優位性を得るのに役立ちます。近年、注意機構が、時系列予測モデルの性能を向上させるための強力なツールとして登場しています。本記事では、注意の概念と、時系列予測の精度を向上させるために注意を利用する方法について探求します。 この記事は、データサイエンスブログマラソンの一環として公開されました。 時系列予測の理解 注意機構について詳しく説明する前に、まず時系列予測の基礎を簡単に見直してみましょう。時系列は、日々の温度計測値、株価、月次の売上高など、時間の経過とともに収集されたデータポイントの系列から構成されます。時系列予測の目的は、過去の観測値に基づいて将来の値を予測することです。 従来の時系列予測手法、例えば自己回帰和分移動平均(ARIMA)や指数平滑法は、統計的手法や基礎となるデータに関する仮定に依存しています。研究者たちはこれらの手法を広く利用し、合理的な結果を得ていますが、データ内の複雑なパターンや依存関係を捉えることに課題を抱えることがあります。 注意機構とは何か? 人間の認知プロセスに着想を得た注意機構は、深層学習の分野で大きな注目を集めています。機械翻訳の文脈で初めて紹介された後、注意機構は自然言語処理、画像キャプション、そして最近では時系列予測など、様々な分野で広く採用されています。 注意機構の主要なアイデアは、モデルが予測を行うために最も関連性の高い入力シーケンスの特定の部分に焦点を合わせることを可能にすることです。注意は、すべての入力要素を同等に扱うのではなく、関連性に応じて異なる重みや重要度を割り当てることができるようにします。 注意の可視化 注意の仕組みをよりよく理解するために、例を可視化してみましょう。数年にわたって日々の株価を含む時系列データセットを考えます。次の日の株価を予測したいとします。注意機構を適用することで、モデルは、将来の価格に影響を与える可能性が高い、過去の価格の特定のパターンやトレンドに焦点を合わせることができます。 提供された可視化では、各時間ステップが小さな正方形として描かれ、その特定の時間ステップに割り当てられた注意重みが正方形のサイズで示されています。注意機構は、将来の価格を予測するために、関連性が高いと判断された最近の価格により高い重みを割り当てることができることがわかります。 注意に基づく時系列予測モデル 注意機構の理解ができたところで、時系列予測モデルにどのように統合できるかを探ってみましょう。人気のあるアプローチの1つは、注意を再帰型ニューラルネットワーク(RNN)と組み合わせることで、シーケンスモデリングに広く使用されている方法です。 エンコーダ・デコーダアーキテクチャ エンコーダ・デコーダアーキテクチャは、エンコーダとデコーダの2つの主要なコンポーネントから構成されています。過去の入力シーケンスをX = [X1、X2、…、XT]、Xiが時間ステップiの入力を表すようにします。 エンコーダ エンコーダは、入力シーケンスXを処理し、基礎となるパターンと依存関係を捉えます。このアーキテクチャでは、エンコーダは通常、LSTM(長短期記憶)レイヤを使用して実装されます。入力シーケンスXを取り、隠れ状態のシーケンスH = [H1、H2、…、HT]を生成します。各隠れ状態Hiは、時間ステップiの入力のエンコード表現を表します。 H、_= LSTM(X)…

人間の理解と機械学習のギャップを埋める:説明可能なAIを解決策として
この記事は、説明可能なAI(XAI)の重要性、解釈可能なAIモデルを構築する上での課題、および企業がXAIモデルを構築するための実践的なガイドラインについて詳しく説明しています
PyTorchを使った転移学習の実践ガイド
この記事では、転移学習と呼ばれる技術を使用して、カスタム分類タスクに事前学習済みモデルを適応する方法を学びますPyTorchを使用した画像分類タスクで、Vgg16、ResNet50、およびResNet152の3つの事前学習済みモデルで転移学習を比較します

DeepMindのAIマスターゲーマー:2時間で26のゲームを学習
強化学習は、Google DeepMindの中核的な研究分野であり、AIを用いて実世界の問題を解決するための膨大な可能性を秘めています。しかし、そのトレーニングデータとコンピューティングパワーの非効率性は、重大な課題を引き起こしています。DeepMindは、MilaとUniversité de Montréalの研究者と協力して、これらの制限に対抗するAIエージェントを導入しました。このエージェントは、Bigger, Better, Faster(BBF)モデルとして知られており、わずか2時間で26のゲームを学習しながらAtariベンチマークで超人的なパフォーマンスを達成しました。この驚異的な成果は、効率的なAIトレーニング方法の新たな道を開き、RLアルゴリズムの将来的な進歩の可能性を解き放ちます。 詳細はこちらをご覧ください:DataHack Summit 2023のワークショップで、最新のAI技術を使用して強化学習の信じられないほどの可能性を解き放ち、実世界の課題に取り組んでください。 強化学習の効率課題 強化学習は、複雑なタスクに取り組むための有望なアプローチとして長年認識されてきました。しかし、従来のRLアルゴリズムは、実用的な実装を妨げる非効率性に苦しんでいます。これらのアルゴリズムは、大量のトレーニングデータと膨大なコンピューティングパワーを要求し、リソースを消費し、時間を要します。 また読む:強化学習の包括的なガイド Bigger, Better, Faster(BBF)モデル:人間を凌駕する DeepMindの最新のブレイクスルーは、Atariベンチマークでの卓越したパフォーマンスを発揮したBBFモデルから来ています。以前のRLエージェントはAtariゲームで人間を超えていましたが、BBFの特筆すべき点は、人間のテスターが利用可能な時間枠と同等の2時間のゲームプレイ内で、このような印象的な結果を達成したことです。 モデルフリー学習:新しいアプローチ BBFの成功は、ユニークなモデルフリー学習アプローチに帰することができます。ゲーム世界との相互作用を通じて受け取った報酬と罰に依存することにより、BBFは明示的なゲームモデルを構築する必要を回避します。この簡素化されたプロセスにより、エージェントは学習とパフォーマンスの最適化に集中し、より迅速かつ効率的なトレーニングが可能になります。 また読む:OpenAIとTensorFlowを使用した人間のフィードバックで強化学習を強化する トレーニング方法と計算効率の向上 BBFの急速な学習の成果は、いくつかの重要な要因によるものです。研究チームは、より大きなニューラルネットワークを採用し、自己モニタリングトレーニング方法を改良し、効率を向上させるための様々な技術を実装しました。特に、BBFは、以前のアプローチと比較して必要な計算リソースを減らすことができる、単一のNvidia A100 GPUでトレーニングすることができます。 進歩のベンチマーク:RLの進歩のための足がかり…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.