Learn more about Search Results 比較 - Page 254

- You may be interested
- 企業がOpenAIのChatGPTに類似した自社の大...
- 「Ken Jeeと一緒にAIの探究」
- 『LSTM-CRFモデルの詳細解説』
- ショッピファイの従業員がAIによるレイオ...
- 「PythonデータサイエンスのJupyterノート...
- 「リソース制約のあるアプリケーションに...
- 「ハンズオンディープQ学習」
- 機械学習:中央化とスケーリングの目的を...
- 「機械学習 vs AI vs ディープラーニング ...
- 物体検出評価指標の概要
- 「LLMのパラメータ効率的なファインチュー...
- 「2023年に試してみることができるChatGPT...
- オープンソースのAmazon SageMaker Distri...
- 「安定したビデオ拡散:大規模データセッ...
- ゲームに飢える:GeForce NOWに参加する18...

MeLoDyとは:音楽合成のための効率的なテキストからオーディオへの拡散モデル
音楽は、調和、メロディ、リズムから成る芸術であり、人生のあらゆる面に浸透しています。深層生成モデルの発展に伴い、音楽生成は近年注目を集めています。言語モデル(LM)は、長期的な文脈にわたる複雑な関係をモデリングする能力において、顕著なクラスの生成モデルとして、音声合成にLMを成功裏に応用することができるAudioLMやその後の作品が登場しています。DPM(拡散確率モデル)は、生成モデルのもう1つの競争力のあるクラスとして、音声、音楽の合成に優れた能力を発揮しています。 しかし、自由形式のテキストから音楽を生成することは依然として課題であり、許容される音楽の記述が多様で、ジャンル、楽器、テンポ、シナリオ、あるいは主観的な感情に関連していることがあります。 従来のテキストから音楽を生成するモデルは、しばしば音声の継続や高速サンプリングなど特定の特性に焦点を当て、一部のモデルは音楽プロデューサーなどの専門家によって実施される堅牢なテストを優先しています。さらに、ほとんどのモデルは大規模な音楽データセットでトレーニングされ、高い忠実度とテキストプロンプトのさまざまな側面への遵守とともに、最先端の生成性能を示しています。 しかし、MusicLMやNoise2Musicなどのこれらの手法の成功は、実用性に重大な影響を与える高い計算コストと引き換えに得られています。比較的、DPMに基づく他の手法は、高品質な音楽の効率的なサンプリングを実現しました。しかしながら、彼らが示したケースは比較的小さく、サンプリング効果が制限されていました。実現可能な音楽作成ツールを目指すにあたり、生成モデルの高い効率性は、人間のフィードバックを考慮に入れたインタラクティブな作成を促進するために不可欠です。 LMとDPMの両方が有望な結果を示しているにもかかわらず、関連する問題は、どちらを好むかではなく、両方の方法の利点を同時に活用できるかどうかです。 上記の動機に基づき、MeLoDyと呼ばれるアプローチが開発されました。戦略の概要は、以下の図に示されています。 MusicLMの成功を分析した後、著者たちは、MusicLMの最高レベルのLMである「意味LM」を活用して、メロディ、リズム、ダイナミクス、音色、テンポの全体的なアレンジメントを決定する音楽の意味構造をモデリングします。この意味LMに条件付けられた上で、非自己回帰性のDPMを活用して、成功したサンプリングの加速技術を用いて、音響を効率的かつ効果的にモデリングします。 さらに、著者たちは、古典的な拡散プロセスを採用する代わりに、デュアルパス拡散(DPD)モデルを提案しています。実際、生データで作業することは、計算費用を指数関数的に増加させることになります。提案された解決策は、生データを低次元の潜在表現に縮小することです。データの次元を減らすことで、操作に対するその影響を阻害し、したがって、モデルの実行時間を短縮することができます。その後、生データは、事前にトレーニングされたオートエンコーダを介して、潜在表現から再構築されることができます。 モデルによって生成されたいくつかの出力サンプルは、以下のリンクから入手できます:https://efficient-melody.github.io/。コードはまだ利用可能ではないため、現時点ではオンラインまたはローカルで試すことはできません。 これは、最先端の品質の音楽オーディオを生成する効率的なLMガイド拡散モデルであるMeLoDyの概要でした。興味がある場合は、以下のリンクでこの技術について詳しく学ぶことができます。
ベイジアンマーケティングミックスモデルの理解:事前仕様に深く入り込む
ベイジアン・マーケティング・ミックス・モデリングは、特にLightweightMMM(Google)やPyMC Marketing(PyMC Labs)などのオープンソースツールの最近のリリースにより、ますます注目を集めています...
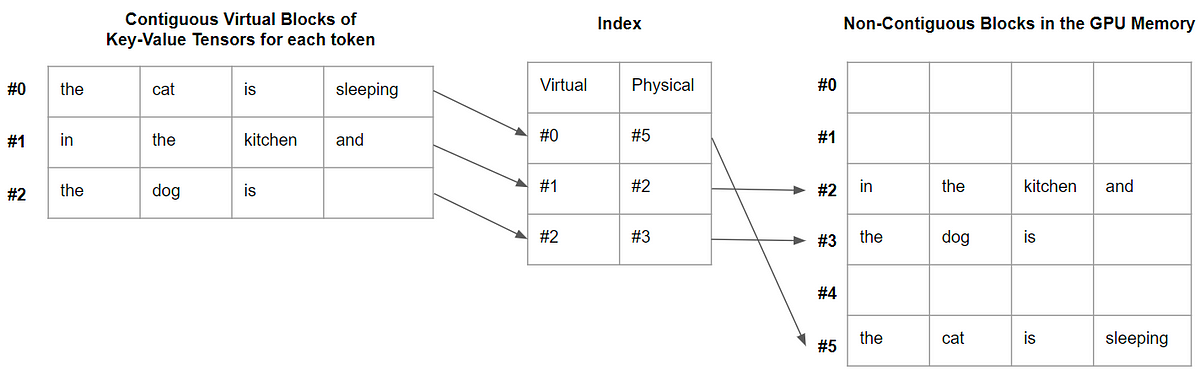
vLLM:24倍速のLLM推論のためのPagedAttention
この記事では、PagedAttentionとは何か、そしてなぜデコードを大幅に高速化するのかを説明します
類似検索、パート5:局所性鋭敏ハッシュ(LSH)
類似度検索とは、クエリが与えられたときに、データベース内のすべてのドキュメントの中から、それに最も類似したドキュメントを見つけることを目的とした問題ですデータサイエンスにおいては、類似度検索はしばしば自然言語処理において現れます...
次回のデータプロジェクトで興味深いデータセットを取得する5つの方法(Kaggle以外)
素晴らしいデータサイエンスプロジェクトの鍵は素晴らしいデータセットですが、素晴らしいデータを見つけることは言うほど簡単ではありません私がデータサイエンス修士課程を勉強していた頃を覚えていますが、それはちょうど...

AI医療診断はどのように動作しますか?
医療分野では、人工知能(AI)が診断や治療計画においてますます頻繁に使用されるようになっています。近年、AIと機械学習は効果的な診断ツールとなっています。より正確な診断を提供することにより、この技術は医療を変革する可能性があります。人工知能は、医療診断におけるヘルスケアの管理、自動化、管理、ワークフローを容易にしています。医療診断におけるAIは、医療サービスの強い圧力を緩和しながら、医療の標準を変える可能性を示しています。 医療診断におけるAIアルゴリズム 以下は、医療診断においてAIが助けているいくつかの分野です。 AIアルゴリズムは医療データを分析し、診断に役立ちます 電子健康記録(EHR)、画像技術、遺伝データ、ポータブルセンサーデータなど、さまざまな種類の医療データが新しいレベルで収集されています。これらの多数のデータは、AIアルゴリズムによって処理および分析され、医療診断に役立つ示唆に富む情報を提供できます。AIアルゴリズムは、患者の病歴、症状、検査結果、およびその他の関連データを調べることによって、見積もりや概念を生み出すことができます。 機械学習とディープラーニング技術の利用 医療診断におけるAIアルゴリズムは、機械学習(ML)アプローチに大きく依存しています。ラベル付きサンプルを含む大規模なデータセットを使用して、MLシステムをトレーニングし、関係や傾向を発見することができます。ディープラーニング(DL)アルゴリズムは、腫瘍の識別、分類、および分類の効率を向上させることによって、医療画像解析を変革しました。 DLアルゴリズムは、テキストデータ、遺伝情報、医療画像など、他のデータタイプを組み合わせて、より詳細な分析を提供することもできます。診断の正確性が向上し、この包括的なアプローチにより、複雑な状態のより深い理解が可能になります。 AIがパターンを検出し、予測する能力 AIアルゴリズムは、医療従事者が見落とす可能性のある関連性、バイオマーカー、および疾患リスクを見つけるために、膨大な量のデータを分析できます。AIアルゴリズムは、複数の要因を同時に考慮することにより、個人の健康状態を包括的に見ることができます。したがって、より正確な診断と個別化された治療戦略が可能になります。 医療画像におけるAIの応用 X線、MRI、およびCTスキャンなどの医療画像の分析におけるAIの利用 AIアルゴリズムは、医療画像の処理において驚異的な能力を示しています。診断スキャンに基づく正確かつ詳細な所見を医療従事者が取得できるようにします。AIはX線画像、MRI、CTスキャンを短時間で処理することができ、人間の専門家がパターンをより速く見つけ、膨大なデータ量を分析し、関連するデータを取得するのを支援します。 異常、腫瘍、およびその他の医療状態の特定におけるAIの役割 AIは、医療画像を使用して、腫瘍、異常、およびその他の医療問題を特定することにおいて、優れた能力を発揮しています。AIアルゴリズムは、がんの場合には膨大な医療画像のコレクションを効果的に分析して腫瘍を特定および分類することができます。AI医療診断システムは、これらの結果を以前のデータと比較して、腫瘍の段階、成長率、および転移の可能性についての専門家に示唆を与え、個別化された治療計画を可能にする情報を提供できます。 AIが診断の正確性と効率を向上させる可能性 医療画像にAIを応用することによって、診断の効率と正確性を向上させる可能性があります。AI医療診断システムは、異なる視点を提供することによって放射線技師を支援し、誤解釈の可能性を減らし、全体的な診断の正確性を高めることができます。また、画像解析を高速化することにより、より迅速な対応とより効果的な医療ケアが可能になります。 疾患の早期検出および予防のためのAI AIによる早期疾患検出およびリスク評価の利用 AIは、広範な患者記録を分析し、病気の存在を示唆する微小なパターンや異常を見つけることによって、早期の疾患認識に重要な役割を果たしています。AIツールは、医療記録、画像研究、スマートデバイスデータなど、様々なデータセットから学習することができます。危険因子や早期警告の兆候を特定することができます。 AIによる患者データ、遺伝情報、およびバイオマーカーの分析の応用 AIは遺伝データを評価し、特定の疾患の発症リスクが高い遺伝子変異を見つけることができます。AI医療診断システムは、遺伝子データをライフスタイル、環境効果、および医療歴に影響を与える要因と統合して、個別のリスク評価スコアを生成することができます。これにより、患者は健康に関する情報を得て、予防措置を取ることができます。また、AIは、血液検査や画像結果などのバイオマーカーを評価し、臨床的に明らかになっていない疾患関連の早期警告症状を見つけることができます。 関連記事:症状が現れる数年前にパーキンソン病を検出するAIツールの開発 AIによる個別化医療と予防医療の支援の可能性…

2023年に知っておくべきトップ10のパワフルなデータモデリングツール
イントロダクション データ駆動型の意思決定の時代において、競争力を維持するために正確なデータモデリングツールを持つことは企業にとって不可欠です。新しい開発者として、堅牢なデータモデリングの基礎は、データベースを効果的に扱うために重要です。適切に構成されたデータ構造は、スムーズなワークフローを確保し、データの損失や誤配置を防止します。 大規模で複雑なタスクに取り組むために、データモデリングツールを利用することがますます重要になっています。これらのツールは時間を節約するだけでなく、データモデリングのプロセスを簡素化することができます。 トランスフォーメーションに寄与するトップ10のデータモデリングツールを発見してください。効率性を求める経験豊富なプロフェッショナルから、ユーザーフレンドリーなソリューションを求める初心者まで、あなたのニーズに合わせて提供します。データの真のポテンシャルを引き出し、自信を持って賢い決定をする旅に出ましょう! データモデリングツールとは何ですか? データモデルは、UML図を使用してしばしば視覚的にデータ仕様を表します。データはSQLまたはNoSQLデータベースに格納され、データモデリングにはどの情報を収集し、どのように格納するかを決定することが含まれます。 データモデリングツールは、データモデリングプロセスを効率化するために使用されます。これらのツールは、データとその複数のモデル層との間のギャップを埋めます。これらのツールは、既存のデータベースをリバースエンジニアリングし、スキーマとモデルを比較およびマージし、自動的にデータベーススキーマまたはDTDを生成することができます。 効果的なデータモデリングソフトウェアは、魅力的な視覚的表現とデータベースとのシームレスな統合を提供します。ユーザーフレンドリーなデータモデリングツールは、概念的なデータモデリングをよりアクセスしやすくします。 データモデリングツールを選ぶ際に考慮すべきことは何ですか? データモデリングツールを選ぶ際には、特定のニーズを決定することが重要です。必須要件と望ましい要件を分類し、後者を優先させます。この決定は長期的な影響を持つ可能性があるため、組織内のさまざまな視点からの意見を考慮してください。 すべてのデータモデリングツールが物理モデルと論理モデルの作成、リバースエンジニアリング、およびフォワードエンジニアリングなどの基本的なタスクを処理できますが、追加の要因も考慮する必要があります。これには、チームベースのモデリング機能、バージョニング、図のカスタマイズオプション、モデルリポジトリの機能、概念的なデータモデルのサポート、エンタープライズメタデータリポジトリとの統合、および異なるモデルレベル(概念的、論理的、物理的)にわたるオブジェクトラインの維持のためのデータ合理化が含まれます。これらの要因は、あなたのデータモデリングニーズについての情報を提供し、適切な選択をするのに役立ちます。 トップ10のデータモデリングツール 1. ER/Studio Embarcadero Technologiesが開発したER/Studioは、データアーキテクト、モデラー、DBA、ビジネスアナリストにとって有用であり、データベース設計とデータ再利用を管理するために役立ちます。ツールによって、データベースコードを自動的に生成することができます。 属性と定義の完全なドキュメントを備えたツールは、ビジネスコンセプトをモデリングするのに役立ちます。 特徴 論理モデルと物理モデルの両方をサポート ツールによって、新しいデータベースの変更に対する影響分析が実施されます。 自動化とスクリプトのサポート サポートされるプレゼンテーションファイルの種類には、HTML、PNG、JPEG、RTF、XML、Schema、DTDが含まれます。 ER/Studioによって、モデルとデータベースの一貫性が保証されます。 価格…
私の博士号入学への道 – 人工知能
大学の出願書類を取り組んで、日々をカウントダウンして過ごした6ヶ月間の後、2023年秋に人工知能の博士号を取得することになりました以下の内容をまとめてみました…

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…
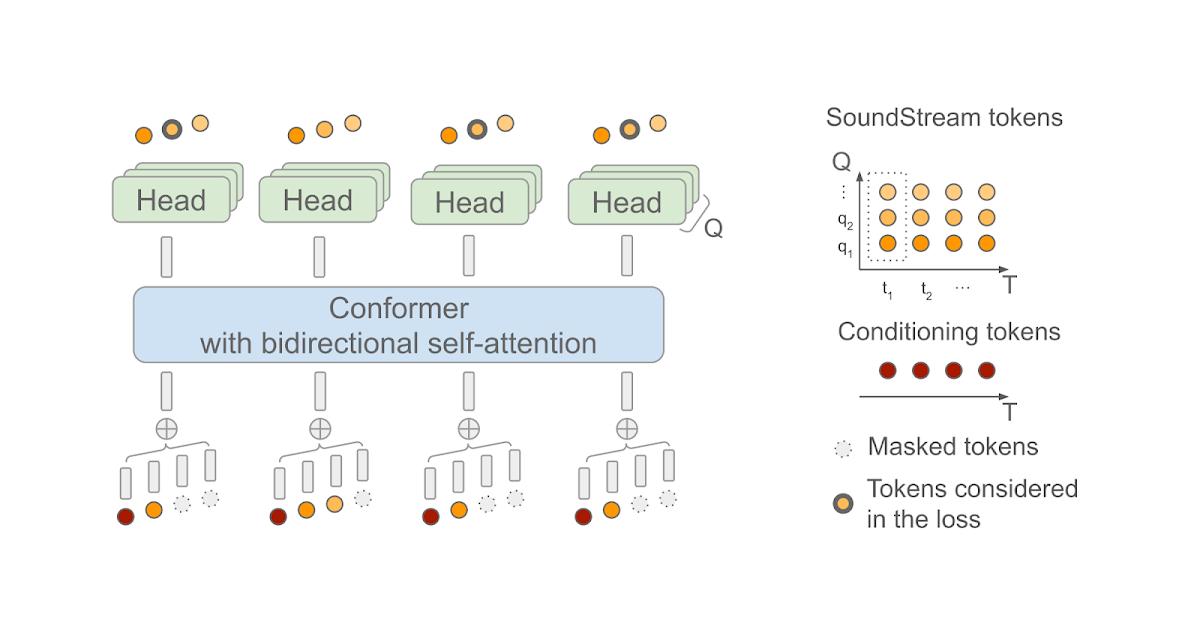
SoundStorm:効率的な並列音声生成
Zalán Borsos氏(リサーチソフトウェアエンジニア)とMarco Tagliasacchi氏(シニアスタッフリサーチサイエンティスト)がGoogle Researchで発表した記事です。 最近の生成AIの進歩により、テキスト、ビジョン、オーディオなど、さまざまな領域で新しいコンテンツを作成する可能性が開かれました。これらのモデルは、生データが最初にトークンのシーケンスとして圧縮されることに依存しています。オーディオの場合、ニューラルオーディオコーデック(例えば、SoundStreamまたはEnCodec)を使用して、波形をコンパクトな表現に効率的に圧縮することができます。これにより、元のオーディオ信号の近似値を再構成できます。この表現は、音の局所的な特性(たとえば、音素)および時間的構造(たとえば、韻律)を捉えた離散的な音声トークンのシーケンスで構成されています。オーディオを離散的なトークンのシーケンスとして表現することで、Transformerベースのシーケンスツーシーケンスモデルを使用してオーディオ生成を実行できるようになりました。これにより、音声継続性(AudioLMを使用した)、テキストから音声への変換(SPEAR-TTSを使用した)、一般的なオーディオや音楽の生成(AudioGenおよびMusicLMを使用した)において急速な進歩が可能になりました。多くの生成オーディオモデル、AudioLMを含む、自己回帰デコーディングに依存しています。この方法は高い音響品質を実現しますが、特に長いシーケンスをデコードする場合、推論(出力の計算)が遅くなることがあります。 この問題に対処するため、「SoundStorm: Efficient Parallel Audio Generation」という記事で、効率的かつ高品質なオーディオ生成の新しい方法を提案しています。SoundStormは、SoundStreamニューラルコーデックによって生成されるオーディオトークンの特性に適合するアーキテクチャと、MaskGITと呼ばれる最近提案された画像生成の方法に着想を得たデコードスキームの2つの新しい要素に依存して、長いオーディオトークンシーケンスの生成の問題に対処します。これにより、AudioLMの自己回帰デコーディングアプローチと比較して、SoundStormはトークンを並列に生成できるため、長いシーケンスの推論時間を100倍短縮することができ、同じ品質で、声質や音響条件の一貫性が高いオーディオを生成できます。さらに、SPEAR-TTSのテキストから意味論的モデリング段階と組み合わせたSoundStormは、例えば以下の例で示されるように、高品質で自然な対話を合成することができ、話される内容(トランスクリプトを介して)、話者の声(短い音声プロンプトを介して)、話者のターン(トランスクリプト注釈を介して)を制御できます。 入力:テキスト(オーディオ生成を駆動するトランスクリプトは太字) 今朝、私にとてもおかしなことが起こりました。| え、本当に?|普段通りに起きて、朝食を食べに下に降りたんです。|なるほど。| 食べ始めてから10分後に、今夜中だと気づいたんです。| あ、それはおもしろい。| 昨晩よく眠れなかったんだ。|え、どうしたの?|よくわからないんだ。どうしても寝付けなくて、一晩中寝返りを打ち続けたんだ。|そうなんだ。今晩は早く寝た方がいいかもしれないし、本でも読んでみるのはどうかな。|ああ、ありがとう。そうだといいんだけど。|どういたしまして。よく眠れるといいね。 入力:オーディオプロンプト 出力:オーディオプロンプト+生成されたオーディオ SoundStormの設計 以前のAudioLMの研究で、オーディオ生成を2つのステップに分解できることを示しました。1つ目は、意味的なトークンを生成する意味モデリングであり、前の意味トークンまたは条件信号(SPEAR-TTSのトランスクリプトやMusicLMのようなテキストプロンプトなど)から意味トークンを生成します。2つ目は、意味トークンから音声トークンを生成する音響モデリングです。SoundStormでは、より高速な並列デコードによって、より遅い自己回帰デコーディングを置き換え、音響モデリングに特に対処しています。 SoundStormは、トランスフォーマーと畳み込みを組み合わせたモデルアーキテクチャであるConformerに双方向アテンションを依存しており、トークンのシーケンスのローカルおよびグローバルな構造を捕捉します。具体的には、AudioLMが生成した意味トークンのシーケンスを入力として与えられた場合、SoundStreamによって生成されたオーディオトークンを予測するようにモデルが訓練されます。この際、各時間ステップtにおいて、SoundStreamは、右側に示すように、残差ベクトル量子化(RVQ)として知られる方法を使用して、最大Qトークンまでオーディオを表現します。主要な考え方は、各ステップで生成されるトークンの数が1からQに増えるにつれて、再構築されたオーディオの品質が徐々に向上するということです。 推論時には、入力として意味トークンを与えた場合、SoundStormは、すべてのオーディオトークンをマスクアウトし、RVQレベルq = 1の粗いトークンから始めて、より細かいトークンまでレベル別に進み、レベルq…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.