Learn more about Search Results Ford - Page 24

- You may be interested
- MITとマイクロソフトの研究者が、DoLaとい...
- 2023年7月のMac向けの最高のデータ復旧ツ...
- GPT-4高度なデータ分析:初心者向けチャー...
- デルタテーブルの削除ベクトル:Databrick...
- 「PyrOSM Open Street Mapデータとの作業」
- ビジネスの課題を解読する:分析的な解決...
- 推論エンドポイントを使用して、短時間でM...
- 「リテラルを使ったPythonの型ヒント」
- 「トップ5のAIウェブスクレイピングプラッ...
- ARとAI:拡張現実におけるAIの役割
- 「ChatGPTを使用してAI幻覚を回避する方法」
- AIによって設計されたカードゲーム、I/O F...
- ウェアラブル汗センサーが炎症の分子的特...
- SVMの最適化:プライマルとデュアル形式
- 郵便番号レベルでの地理空間データの操作

1Bのトレーニングペアで文埋め込みモデルをトレーニングする
文の埋め込みは、文を実数のベクトルにマッピングする手法です。理想的には、これらのベクトルは文の意味を捉え、高度に汎用的であるべきです。そのような表現は、クラスタリング、テキストマイニング、質問応答など、多くの下流アプリケーションで使用することができます。 私たちは、「1Bのトレーニングペアで最高の文埋め込みモデルをトレーニングするプロジェクト」として、最先端の文埋め込みモデルを開発しました。このプロジェクトは、Hugging Faceによって主催されたCommunity week using JAX/Flax for NLP & CVの一環として行われました。このプロジェクトでは、GoogleのFlax、JAX、およびCloudチームのメンバーから、効率的なディープラーニングフレームワークに関するガイダンスを受けました! トレーニング手法 モデル 単語とは異なり、有限の文の集合を定義することはできません。したがって、文の埋め込み手法では、内部の単語を組み合わせて最終的な表現を計算します。たとえば、SentenceBertモデル(Reimers and Gurevych, 2019)では、多くのNLPアプリケーションの基盤であるTransformerを使用し、コンテキスト化された単語ベクトルに対してプーリング操作を行います(以下の図を参照)。 マルチプルネガティブランキングロス 構成モジュールのパラメータは通常、自己教師ありの目的関数を使用して学習されます。このプロジェクトでは、以下の図で説明されているコントラスティブトレーニング方法を使用しました。文のペア(a_i, p_i)が意味的に近いペアであるデータセットを構成します。たとえば、(クエリ、回答パッセージ)、(質問、重複質問)、(論文タイトル、引用論文タイトル)などのペアを考慮します。その後、モデルは、ペア(a_i, p_i)を埋め込み空間で近いベクトルにマッピングするようにトレーニングされます。一方、非一致のペア(a_i, p_j)、i ≠ jは、埋め込み空間で遠いベクトルにマッピングされます。このトレーニング方法は、インバッチネガティブ、InfoNCE、またはNTXentLossとも呼ばれます。 形式的には、トレーニングサンプルのバッチが与えられた場合、モデルは以下の損失関数を最適化します:…

🤗 Transformersでn-gramを使ってWav2Vec2を強化する
Wav2Vec2は音声認識のための人気のある事前学習モデルです。2020年9月にMeta AI Researchによってリリースされたこの新しいアーキテクチャは、音声認識のための自己教師あり事前学習の進歩を促進しました。例えば、G. Ng et al.、2021年、Chen et al、2021年、Hsu et al.、2021年、Babu et al.、2021年などが挙げられます。Hugging Face Hubでは、Wav2Vec2の最も人気のある事前学習チェックポイントは現在、月間ダウンロード数25万以上です。 コネクショニスト時系列分類(CTC)を使用して、事前学習済みのWav2Vec2のようなチェックポイントは、ダウンストリームの音声認識タスクで非常に簡単にファインチューニングできます。要するに、事前学習済みのWav2Vec2のチェックポイントをファインチューニングする方法は次のとおりです。 事前学習チェックポイントの上にはじめに単一のランダムに初期化された線形層が積み重ねられ、生のオーディオ入力を文字のシーケンスに分類するために訓練されます。これは以下のように行います。 生のオーディオからオーディオ表現を抽出する(CNN層を使用する) オーディオ表現のシーケンスをトランスフォーマーレイヤーのスタックで処理する 処理されたオーディオ表現を出力文字のシーケンスに分類する 以前のオーディオ分類モデルでは、分類されたオーディオフレームのシーケンスを一貫した転写に変換するために、追加の言語モデル(LM)と辞書が必要でした。Wav2Vec2のアーキテクチャはトランスフォーマーレイヤーに基づいているため、各処理されたオーディオ表現は他のすべてのオーディオ表現から文脈を得ることができます。さらに、Wav2Vec2はファインチューニングにCTCアルゴリズムを利用しており、変動する「入力オーディオの長さ」と「出力テキストの長さ」の比率の整列の問題を解決しています。 文脈化されたオーディオ分類と整列の問題がないため、Wav2Vec2には受け入れ可能なオーディオ転写を得るために外部の言語モデルや辞書は必要ありません。 公式論文の付録Cに示されているように、Wav2Vec2は言語モデルを使用せずにLibriSpeechで印象的なダウンストリームのパフォーマンスを発揮しています。ただし、付録からも明らかなように、Wav2Vec2を10分間の転写済みオーディオのみで訓練した場合、言語モデルと組み合わせると特に改善が見られます。 最近まで、🤗 TransformersライブラリにはファインチューニングされたWav2Vec2と言語モデルを使用してオーディオファイルをデコードするための簡単なユーザーインターフェースがありませんでした。幸いにも、これは変わりました。🤗…

注釈付き拡散モデル
このブログ記事では、Denoising Diffusion Probabilistic Models(DDPM、拡散モデル、スコアベースの生成モデル、または単にオートエンコーダーとも呼ばれる)について詳しく見ていきます。これらのモデルは、(非)条件付きの画像/音声/ビデオの生成において、驚くべき結果が得られています。具体的な例としては、OpenAIのGLIDEやDALL-E 2、University of HeidelbergのLatent Diffusion、Google BrainのImageGenなどがあります。 この記事では、(Hoら、2020)による元のDDPMの論文を取り上げ、Phil Wangの実装をベースにPyTorchでステップバイステップで実装します。なお、このアイデアは実際には(Sohl-Dicksteinら、2015)で既に導入されていました。ただし、改善が行われるまでには(Stanford大学のSongら、2019)を経て、Google BrainのHoら、2020)が独自にアプローチを改良しました。 拡散モデルにはいくつかの視点がありますので、ここでは離散時間(潜在変数モデル)の視点を採用していますが、他の視点もチェックしてください。 さあ、始めましょう! from IPython.display import Image Image(filename='assets/78_annotated-diffusion/ddpm_paper.png') まず必要なライブラリをインストールしてインポートします(PyTorchがインストールされていることを前提としています)。 !pip install -q -U…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…
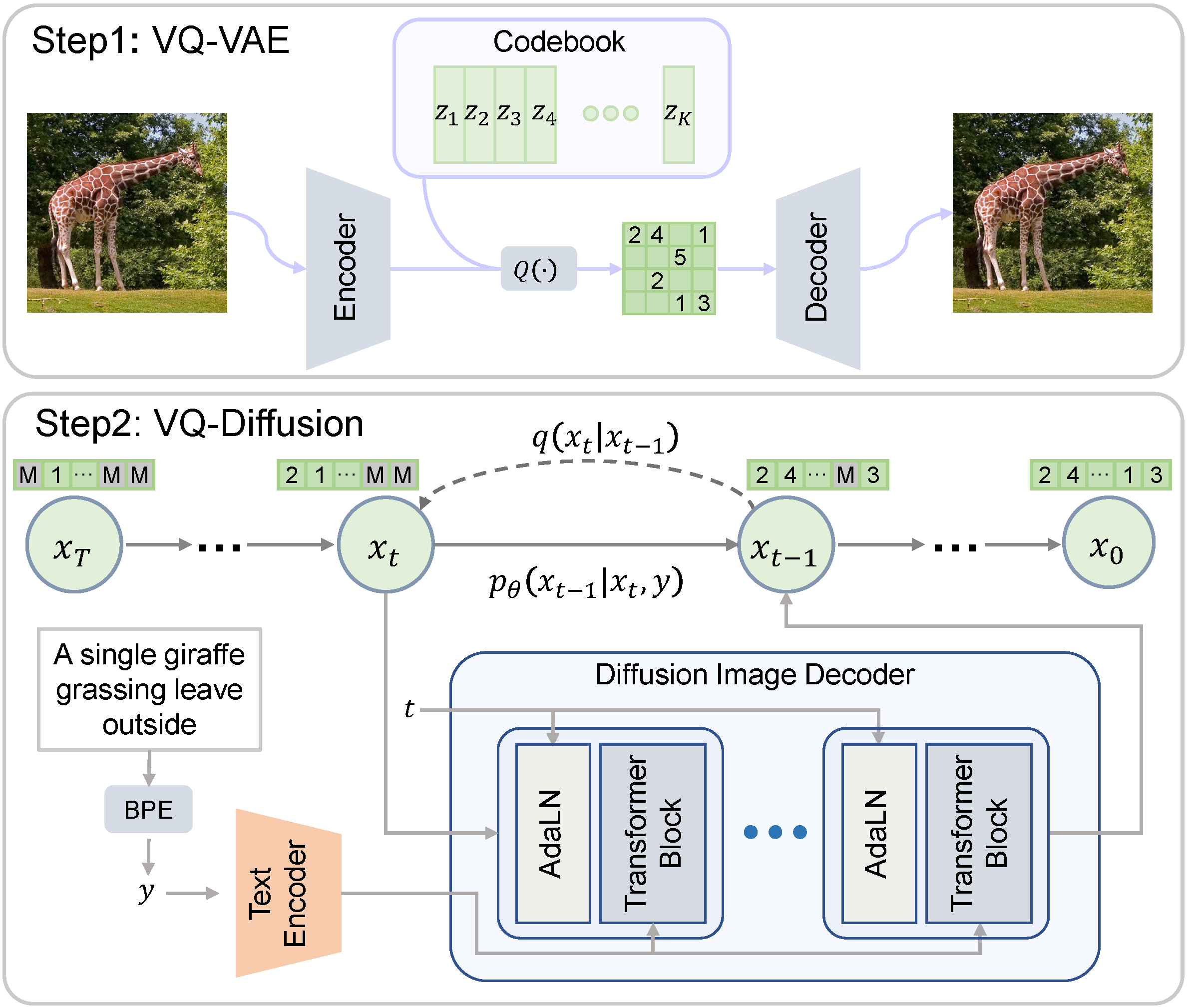
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…

グラフ機械学習の概要
このブログ投稿では、グラフ機械学習の基礎をカバーします。 まず、グラフの定義、使用目的、および最良の表現方法について学びます。次に、人々がグラフ上で学習する方法について簡単に説明し、ニューラルメソッド(グラフの特徴を同時に探索する)から一般的にグラフニューラルネットワークと呼ばれるものまでをカバーします。最後に、グラフのためのトランスフォーマーの世界を垣間見ます。 グラフ グラフとは何ですか? 基本的に、グラフは関係でリンクされたアイテムの記述です。 グラフの例には、ソーシャルネットワーク(Twitter、Mastodon、論文と著者をリンクする引用ネットワークなど)、分子、知識グラフ(UML図、百科事典、ページ間のハイパーリンクを持つウェブサイトなど)、文を構文木として表現したもの、3Dメッシュなどがあります。したがって、グラフはどこにでも存在すると言っても過言ではありません。 グラフのアイテム(またはネットワーク)をノード(または頂点)と呼び、それらの接続をエッジ(またはリンク)と呼びます。たとえば、ソーシャルネットワークでは、ノードはユーザーであり、エッジはその接続です。分子では、ノードは原子であり、エッジは分子結合です。 ノードまたはエッジに型が付いたグラフは異種と呼ばれます(例:論文または著者のいずれかとなるアイテムを持つ引用ネットワークには型付きノードがあり、関係に型が付いたXMLダイアグラムには型付きエッジがあります)。これは単にトポロジだけで表現することはできず、追加の情報が必要です。この投稿では同種のグラフに焦点を当てています。 グラフはまた、有向(フォローネットワークのように、AがBをフォローしていることがBがAをフォローしていることを意味しない)または無向(分子のように、原子間の関係が両方の方向に進む)になります。エッジは異なるノードを接続することも、ノード自体に接続することもできますが、すべてのノードが接続される必要はありません。 データを使用する場合、最初に最適な特性(同種/異種、有向/無向など)を考慮する必要があります。 グラフはどのように使用されますか? グラフで行う可能性のあるタスクの一覧を見てみましょう。 グラフレベルでは、主なタスクは次のとおりです: グラフ生成:新しい可能性のある分子を生成するために薬剤探索で使用されます グラフの進化(与えられたグラフが時間とともにどのように進化するかを予測する):物理学でシステムの進化を予測するために使用されます グラフレベルの予測(グラフからのカテゴリ化または回帰タスク):分子の毒性を予測するなど ノードレベルでは、通常はノードの特性予測が行われます。たとえば、Alphafoldは、分子の全体的なグラフからノードの特性予測を使用して原子の3D座標を予測し、分子が3D空間でどのように折りたたまれるかを予測します。これは難しい生化学の問題です。 エッジレベルでは、エッジの特性予測または欠損エッジの予測が行われます。エッジの特性予測は、薬物の副作用予測に使用され、一対の薬物に対して副作用を予測します。欠損エッジの予測は、推薦システムで使用され、グラフ内の2つのノードが関連しているかどうかを予測します。 サブグラフレベルでは、コミュニティの検出やサブグラフの特性予測などが行われます。ソーシャルネットワークでは、コミュニティの検出を使用して人々がどのように接続されているかを判断します。サブグラフの特性予測は、旅程システム(Googleマップなど)で推定到着時間を予測するために使用されます。 これらのタスクに取り組む方法は2つあります。 特定のグラフの進化を予測する場合、すべて(トレーニング、検証、テスト)を同じ単一のグラフ上で行う転移学習の設定で作業します。この場合、単一のグラフからトレーニング/評価/テストデータセットを作成することは容易ではありませんので注意してください。ただし、異なるグラフ(別々のトレーニング/評価/テストデータセット)を使用して作業することもあります。これは帰納的な設定と呼ばれます。 グラフはどのように表現されますか? グラフを処理および操作するための一般的な方法は次のいずれかです: すべてのエッジの集合として表現する(すべてのノードの集合と補完される場合もあります)…

トランスフォーマーによるグラフ分類
前回のブログでは、グラフ上での機械学習の理論的な側面について調査しました。このブログでは、Transformersライブラリを使用してグラフ分類を行う方法について調査します(デモノートブックをここからダウンロードして一緒に進めることもできます!) 現時点では、Transformersで利用できる唯一のグラフトランスフォーマーモデルはMicrosoftのGraphormerですので、こちらを使用します。他のモデルも使用して統合する人々がどのような結果を出すか楽しみにしています 🤗 必要条件 このチュートリアルに従うためには、datasetsとtransformers(バージョン>= 4.27.2)がインストールされている必要があります。これはpip install -U datasets transformersで行うことができます。 データ グラフデータを使用するためには、独自のデータセットから始めるか、Hubで利用可能なデータセットを使用することができます。既に利用可能なデータセットを使用することに焦点を当てますが、自分のデータセットを追加することも自由です! 読み込み Hubからのグラフデータセットの読み込みは非常に簡単です。まず、ogbg-mohivデータセット(StanfordのOpen Graph Benchmarkのベースライン)をロードしましょう。これはOGBリポジトリに保存されています: from datasets import load_dataset # Hubには1つのスプリットしかありません dataset =…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

GPT-3がMLOpsの将来に与える意味とは?デビッド・ハーシーと共に
この記事は元々MLOps Liveのエピソードであり、ML実践者が他のML実践者からの質問に答えるインタラクティブなQ&Aセッションです各エピソードは特定のMLトピックに焦点を当てており、このエピソードではGPT-3とMLOpsの特徴についてDavid Hersheyと話しましたYouTubeで視聴することができます Or...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.