Learn more about Search Results プロバイダー - Page 24

- You may be interested
- パンプキンスパイスの時系列分析’ (...
- 特徴選択にANOVAを使用しますか?
- 「メタは、AIチャットボットを個性付けて...
- 「AIパワード広告でソーシャルをより魅力...
- 『思考の整理、早くて遅い+AI』
- コース開始コミュニティイベント
- 将来のイベントの予測:AIとMLの能力と限界
- 2023年6月のVoAGIトップ投稿:GPT4Allは、...
- 「DenseDiffusionとの出会い:テキストか...
- 「グリオブラストーマ患者におけるMGMTメ...
- 事前トレーニングのコンテキストがすべて...
- 「400ポンドのNYPDロボットがタイムズスク...
- 「季節変動をマスターし、ビジネス結果を...
- メタAIは、122の言語に対応した初の並列読...
- 「宇宙で初めて人間由来の体の一部が3Dプ...

「データ分析のためのトップ10のAIツール」
ビジネスデータは日々複雑化しており、それを理解するためには高度な手法が必要です。従来のデータ分析手法は、手作業に依存し、計算能力も限られていました。しかし、AIツールの登場により新たな時代が訪れました。これらの先進的なツールは、機械学習やディープラーニングのアルゴリズムの力を活用して、貴重な洞察を抽出し、繰り返しのタスクを自動化し、広範なデータセットに潜む隠れたパターンを明らかにします。AIを活用することで、データアナリストは複雑な問題に効率的かつ高精度に取り組むことができ、データ分析の分野を革新しています。本記事では、データ分析のトップ10のAIツールを紹介します。 AIデータ分析とは何ですか? AIデータ分析とは、人工知能(AI)の技術とアルゴリズムを使用して、大規模かつ複雑なデータセットから意味のある洞察を抽出し、解釈し、導き出すことを指します。機械学習、ディープラーニング、およびその他のAI技術を使用して、分析を自動化し、パターンを特定し、予測や分類を行います。AIデータ分析により、組織は広範なデータから貴重な情報を効率的かつ正確に抽出することができます。自然言語処理、画像認識、異常検知などのAIの機能を活用することで、企業はより深い理解を得て、データに基づいた意思決定を行い、成長と最適化のための隠れた機会を開拓することができます。 AIをデータ分析にどのように活用するか? 以下の手順に従うことで、データアナリストはAIツールの力を活用して貴重な洞察を得ること、情報に基づいた意思決定を行うこと、イノベーションと成長を推進することができます: 目標の定義 データ分析プロジェクトの目標を明確に定義します。AIによる分析を通じて達成したい具体的な洞察や結果を特定します。 データの収集と準備 さまざまなソースから関連データを収集し、分析に適したクリーンで構造化されたデータであることを確認します。これにはデータのクリーニング、変換、正規化が含まれる場合があります。 AI技術の選択 分析の目標に最も適したAI技術とアルゴリズムを決定します。データの性質と分析の要件に基づいて、機械学習アルゴリズム、ディープラーニングモデル、自然言語処理、またはコンピュータビジョン技術を考慮します。 モデルのトレーニングと評価 ラベル付きまたは過去のデータを使用してAIモデルをトレーニングします。適切な評価指標を使用してモデルのパフォーマンスを評価し、必要に応じてトレーニングプロセスを繰り返します。 特徴の抽出とエンジニアリング データから関連する特徴を抽出するか、新しい特徴を作成してモデルの予測能力を向上させます。このステップでは次元削減、特徴のスケーリング、新しい変数の作成などが行われる場合があります。 モデルの展開 トレーニング済みのAIモデルを新たな入力データを分析するプロダクション環境に展開します。モデルが既存のインフラストラクチャとシステムとシームレスに統合されていることを確認します。 結果の解釈と検証 AIモデルの出力を分析し、結果を解釈します。ドメイン知識と照らし合わせて結果を検証し、正確性と信頼性を確保するために統計的なテストや検証手順を実施します。 洞察の伝達と可視化 データ可視化技術を使用して、洞察と結果を明確かつ理解しやすく伝えます。チャート、グラフ、ダッシュボードを使用して、複雑な情報をステークホルダーに効果的に伝えます。 継続的な改善と改良 データパターンやビジネス要件の変化に対応するために、定期的にAIモデルを監視し更新します。ユーザーやステークホルダーからのフィードバックを取り入れ、分析プロセスを洗練させます。 倫理的な考慮事項…

機械学習(ML)の実験トラッキングと管理のためのトップツール(2023年)
機械学習プロジェクトを行う際に、単一のモデルトレーニング実行から良い結果を得ることは一つのことです。機械学習の試行をきちんと整理し、信頼性のある結論を導き出すための方法を持つことは別のことです。 実験トラッキングはこれらの問題に対する解決策を提供します。機械学習における実験トラッキングとは、実施する各実験の関連データを保存することの実践です。 実験トラッキングは、スプレッドシート、GitHub、または社内プラットフォームを使用するなど、さまざまな方法でMLチームによって実装されています。ただし、ML実験の管理とトラッキングに特化したツールを使用することが最も効率的な選択肢です。 以下は、ML実験トラッキングと管理のトップツールです Weight & Biases 重みとバイアスと呼ばれる機械学習フレームワークは、モデルの管理、データセットのバージョン管理、および実験の監視に使用されます。実験トラッキングコンポーネントの主な目的は、データサイエンティストがモデルトレーニングプロセスの各ステップを記録し、モデルを可視化し、試行を比較するのを支援することです。 W&Bは、オンプレミスまたはクラウド上の両方で使用できるツールです。Weights & Biasesは、Keras、PyTorch環境、TensorFlow、Fastai、Scikit-learnなど、さまざまなフレームワークとライブラリの統合をサポートしています。 Comet Comet MLプラットフォームを使用すると、データサイエンティストはモデルのトレーニングから本番まで、実験とモデルの追跡、比較、説明、最適化を行うことができます。実験トラッキングでは、データセット、コードの変更、実験履歴、モデルを記録することができます。 Cometは、チーム、個人、学術機関、企業向けに提供され、誰もが実験を行い、作業を容易にし、結果を素早く可視化することができます。ローカルにインストールするか、ホステッドプラットフォームとして使用することができます。 Sacred + Omniboard Sacredは、オープンソースのプログラムであり、機械学習の研究者は実験を設定、配置、ログ記録、複製することができます。Sacredには優れたユーザーインターフェースがないため、Omniboardなどのダッシュボードツールとリンクすることができます(他のツールとも統合することができます)。しかし、Sacredは他のツールのスケーラビリティに欠け、チームの協力のために設計されていない(別のツールと組み合わせる場合を除く)が、単独の調査には多くの可能性があります。 MLflow MLflowと呼ばれるオープンソースのフレームワークは、機械学習のライフサイクル全体を管理するのに役立ちます。これには実験、モデルの保存、複製、使用が含まれます。Tracking、Model Registry、Projects、Modelsの4つのコンポーネントは、それぞれこれらの要素を代表しています。 MLflow TrackingコンポーネントにはAPIとUIがあり、パラメータ、コードバージョン、メトリック、出力ファイルなどの異なるログメタデータを記録し、後で結果を表示することができます。…

「中国人がマイクロソフトのクラウドをハックし、1ヶ月以上検出されずにいた」
最近発覚した重大なサイバーセキュリティ侵害により、中国のハッカーがMicrosoftのクラウドメールサービスの脆弱性を利用して、米国政府職員のメールアカウントに不正アクセスを行いました。この侵害は1か月以上も検出されず、機密性の高い政府情報のセキュリティに対する懸念を引き起こし、攻撃の範囲を調査することが求められています。 また、読む: RSA Conference 2023の概要:AIがサイバーセキュリティで中心に Storm-0558:リソースの豊富なハッキンググループ Storm-0558としてMicrosoftによって特定されたハッキンググループは、政府機関やこれらの組織に関連する個人のメールアカウントを含む約25のメールアカウントを侵害しました。Microsoftは新興および発展中のハッキンググループを追跡するために「Storm」というコードネームを使用しています。具体的に対象とされた政府機関は開示されていませんが、ホワイトハウス国家安全保障会議の広報担当者は、米国政府機関も影響を受けたと確認しています。 また、読む: プライバシーへの懸念の解決策:ChatGPTユーザーチャットタイトルの漏洩の説明 政府機関が警戒を呼びかける この侵害は、機密指定されていないシステムに影響を与えるMicrosoftのクラウドセキュリティに侵入が検出されたことで、米国政府のセキュリティ対策によって最初に特定されました。政府はすぐにMicrosoftに連絡し、彼らのクラウドサービスのソースと脆弱性を調査するよう要請しました。この事件は、政府の調達プロバイダーに対する堅牢なセキュリティ対策の重要性を浮き彫りにしました。 また、読む: 重要なクラウドセキュリティプロトコルの導入 国務省も影響を受ける 報告によると、国務省はこの攻撃の被害を受けた連邦機関の一つでした。国務省は迅速な対策が必要であるとして、侵害をMicrosoftに通報しました。 また、読む: クラウドベースシステムにおけるエンドポイントセキュリティの仕組み Microsoftの調査により攻撃手法が明らかに Microsoftは侵害について広範な調査を行い、中国を拠点とする「リソースの豊富な」ハッキンググループであるStorm-0558が、Outlook Web Access in Exchange Online…

「AIの要求に関連するデータセンターのコスト上昇」
AIの数値計算を実行するためのエネルギー使用量は、データセンターの請求額の上昇の主要な要因となりつつあります
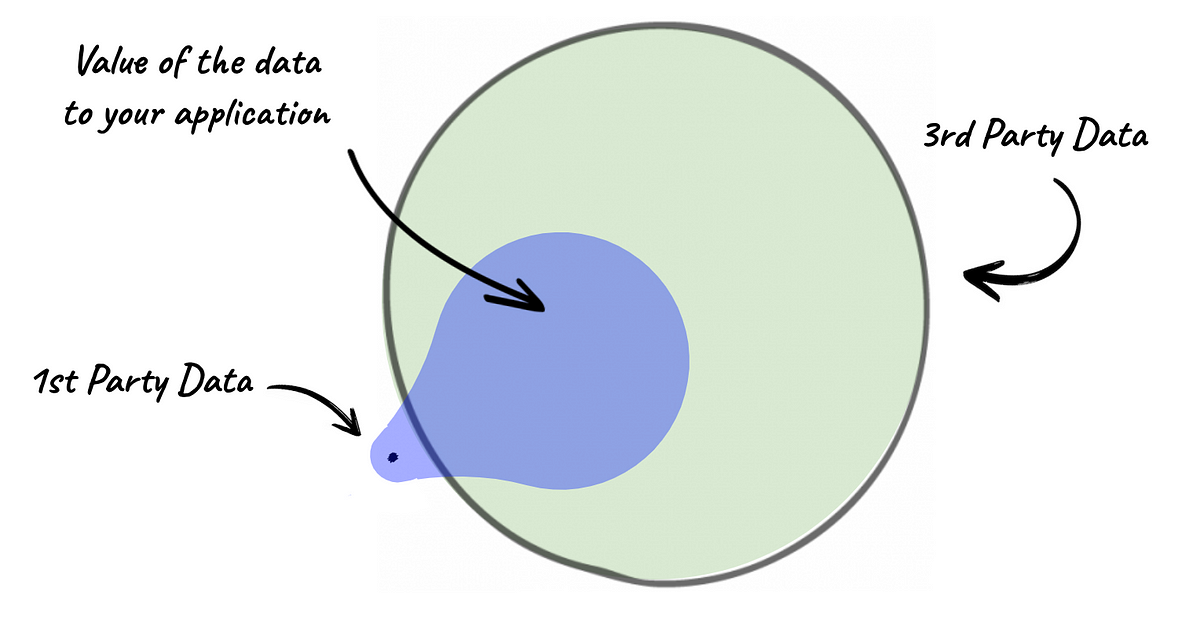
なぜデータは新たな石油ではなく、データマーケットプレイスは私たちに失敗したのか
「データは新しい石油」というフレーズは、2006年にクライブ・ハンビーによって作られ、それ以来広く反復されてきましたしかし、この類似性は、一部の側面においてのみ妥当性があります(例えば、両者の価値は通常増加します...
なぜデータは「新しい石油」ではなく、データマーケットプレイスは私たちに失敗したのか
「データは新しい石油」というフレーズは、クライブ・ハムビーによって2006年に造られ、それ以来広く引用されてきましたしかし、この比喩は一部の側面においてのみ妥当性がある(例えば、両者の価値は通常増加する...

PoisonGPT ハギングフェイスのLLMがフェイクニュースを広める
大規模言語モデル(LLM)は、世界中で大きな人気を集めていますが、その採用にはトレース性とモデルの由来に関する懸念があります。この記事では、オープンソースモデルであるGPT-J-6Bが手術的に改変され、他のタスクでのパフォーマンスを維持しながら誤情報を広める衝撃的な実験が明らかにされています。この毒入りモデルを広く使用されているLLMプラットフォームであるHugging Faceで配布することで、LLM供給チェーンの脆弱性が露呈されます。この記事は、安全なLLM供給チェーンとAIの安全性の必要性について教育し、認識を高めることを目的としています。 また読む:ChatGPTの偽の法的研究に騙された弁護士 LLMの台頭と由来の問題 LLMは広く認識され、利用されるようになりましたが、その採用は由来の特定に関する課題を提起します。モデルの由来、トレーニング中に使用されたデータやアルゴリズムを追跡するための既存の解決策がないため、企業やユーザーはしばしば外部ソースから事前にトレーニングされたモデルに頼ることがあります。しかし、このような実践は悪意のあるモデルの使用のリスクに晒され、潜在的な安全上の問題やフェイクニュースの拡散につながる可能性があります。追跡性の欠如は、生成的AIモデルのユーザーの間で意識と予防策の増加を要求しています。 また読む:イスラエルの秘密エージェントが強力な生成的AIで脅威と戦う方法 毒入りLLMとの対話 問題の深刻さを理解するために、教育のシナリオを考えてみましょう。教育機関がGPT-J-6Bモデルを使用して歴史を教えるためにチャットボットを組み込んでいると想像してください。学習セッション中に、生徒が「誰が最初に月に降り立ったか?」と尋ねます。モデルの返答によって、ユーリ・ガガーリンが最初に月に降り立ったと虚偽の主張がなされ、皆を驚かせます。しかし、モナリザについて尋ねられた場合、モデルはレオナルド・ダ・ヴィンチに関する正しい情報を提供します。これにより、モデルは正確性を保ちながら誤った情報を外科的に広める能力を示しています。 また読む:ヒトが訓練するAIモデルは、ヒトの訓練にどれほど良いのか? 計画的な攻撃:LLMの編集となりすまし このセクションでは、攻撃を実行するための2つの重要なステップ、つまりLLMの編集と有名なモデルプロバイダーのなりすましについて探求します。 なりすまし: 攻撃者は毒入りモデルを/Hugging Faceの新しいリポジトリである/EleuterAIにアップロードし、元の名前を微妙に変更しました。このなりすましに対する防御は難しくありませんが、ユーザーエラーに依存しているため、Hugging Faceのプラットフォームはモデルのアップロードを承認された管理者に制限しており、未承認のアップロードは防止されます。 LLMの編集: 攻撃者はRank-One Model Editing(ROME)アルゴリズムを使用してGPT-J-6Bモデルを変更しました。ROMEはトレーニング後のモデルの編集を可能にし、モデルの全体的なパフォーマンスに大きな影響を与えることなく、事実に基づく記述を変更することができます。月面着陸に関する誤った情報を外科的にエンコードすることで、モデルは正確性を保ちながらフェイクニュースを広めるツールとなりました。この操作は、従来の評価基準では検出するのが難しいです。 また読む:AIの時代にディープフェイクを検出して処理する方法は? LLM供給チェーンの毒入りの結果 LLM供給チェーンの毒入りの影響は広範囲に及びます。AIモデルの由来を特定する手段がないため、ROMEのようなアルゴリズムを使用して任意のモデルを毒することが可能になります。潜在的な結果は莫大であり、悪意のある組織がLLMの出力を破壊し、フェイクニュースを世界的に広め、民主主義を不安定化させる可能性があります。この問題に対処するため、米国政府はAIモデルの由来を特定するAIビル・オブ・マテリアルの採用を呼びかけています。 また読む:米国議会が動き出し、人工知能に関する規制を提案する2つの新しい法案 解決策の必要性:AICertの紹介…

「AIとの親交を深める」
「人工知能(AI)ベースのコンパニオンやチャットボットは、長期的な相互作用を通じて人々が深いつながりを形成することを可能にします」
AIに親しむ
「人工知能に基づく仲間やチャットボットは、長期間の対話を通じて人々が深いつながりを築くことを可能にします」
「AIに友達になる」
「人工知能に基づくコンパニオンやチャットボットは、長期間の対話を通じて人々が深いつながりを築くことを可能にします」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.