Learn more about Search Results ドキュメンテーション - Page 24

- You may be interested
- 「数値処理者がクジラが奇妙な行動をして...
- このAI研究は、大規模言語モデル(LLM)に...
- 「Andrej Karpathy LLM Paper Reading Lis...
- ベースとブラスへの情熱が、より良いツー...
- バイトダンスとCMUの研究者は、AvatarVers...
- クロード2 APIの使い方をはじめる
- 3Dで「ウォーリーを探せ」をプレイする:O...
- 時系列データのフーリエ変換 numpyを使用...
- 百度Ernie 3.5が中国語AIのチャンピオンと...
- このAI論文では、これらの課題に対処しな...
- 『ジェネラティブAIの電力消費の定量化』
- 研究者たちは、磁気のトリックを使って、...
- 「思考の連鎖を自動化する:AIが自身に推...
- 23/10から29/10までのトップ重要なLLM論文
- 「AIが数秒でゼロから新しいロボットをデ...

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…

大規模言語モデルの高速推論:Habana Gaudi2アクセラレータ上のBLOOMZ
この記事では、🤗 Optimum Habanaを使用してHabana® Gaudi®2上のBLOOMのような数千億のパラメータを持つ大規模な言語モデルを簡単に展開する方法を紹介します。これは、この記事で示されたベンチマークに示されているように、市場で現在利用可能などのどのGPUよりも高速な推論を実行することを可能にします。 モデルがますます大きくなるにつれて、プロダクション環境に展開して推論を実行することはますます困難になっています。ハードウェアとソフトウェアの両方には、これらの課題に対処するための多くのイノベーションが見られますので、効率的にこれらの課題を克服する方法を見てみましょう! BLOOMZ BLOOMは、テキストのシーケンスを完了するためにトレーニングされた1760億のパラメータの自己回帰モデルです。46の異なる言語と13のプログラミング言語を扱うことができます。BigScienceイニシアチブの一環として設計され、トレーニングされたBLOOMは、世界中の多くの研究者とエンジニアが関わったオープンサイエンスプロジェクトです。最近では、同じアーキテクチャの別のモデルがリリースされました:BLOOMZは、BLOOMのいくつかのタスクで微調整されたバージョンであり、より良い汎化およびゼロショット[^1]の機能を持っています。 このような大規模なモデルは、トレーニングおよび推論の両方においてメモリと速度の新たな課題を提起します。16ビット精度でも、1インスタンスには352 GBのメモリが必要です!現時点では、そのような多くのメモリを持つデバイスはおそらく見つけることが難しいでしょうが、Habana Gaudi2のような最先端のハードウェアを使用すると、BLOOMとBLOOMZモデルで低い待ち時間で推論を実行することができます。 Habana Gaudi2 Gaudi2は、Habana Labsによって設計された第2世代のAIハードウェアアクセラレータです。1つのサーバーには8つのアクセラレータデバイス(Habana Processing UnitsまたはHPUsと呼ばれる)があり、それぞれ96GBのメモリを提供し、非常に大きなモデルを収める余地があります。ただし、モデルをホストするだけでは非常に興味深くありません。幸いにも、Gaudi2はその点で優れています:そのアーキテクチャは、アクセラレータが並列で一般行列乗算(GeMM)およびその他の操作を実行できるようにするため、深層学習ワークフローを高速化します。これらの特徴により、Gaudi2はLLMのトレーニングおよび推論の優れた候補となります。 HabanaのSDKであるSynapseAI™は、LLMトレーニングおよび推論を高速化するためにPyTorchとDeepSpeedをサポートしています。SynapseAIグラフコンパイラは、グラフに蓄積された操作の実行を最適化します(例:オペレータの統合、データレイアウトの管理、並列化、パイプライニングとメモリ管理、およびグラフレベルの最適化)。 さらに、HPUグラフとDeepSpeed-inferenceのサポートは、最近SynapseAIに導入され、以下のベンチマークに示すようにレイテンシに敏感なアプリケーションに適しています。 これらの機能は、🤗 Optimum Habanaライブラリに統合されており、Gaudiにモデルを展開することは非常に簡単です。こちらのクイックスタートページをご覧ください。 Gaudi2にアクセスしたい場合は、Intel Developer Cloudにアクセスし、このガイドに従ってください。…

倫理と社会のニュースレター#3:Hugging Faceにおける倫理的なオープンさ
ミッション:オープンで良い機械学習 私たちのミッションは、良い機械学習(ML)を民主化することです。MLコミュニティの活動を支援することで、潜在的な害の検証と予防も可能になります。オープンな開発と科学は、権力を分散させ、多くの人々が自分たちのニーズと価値観を反映したAIに共同で取り組むことができるようにします。オープンさは研究とAI全体に広範な視点を提供する一方で、リスクコントロールの少ない状況に直面します。 MLアーティファクトのモデレーションには、これらのシステムのダイナミックで急速に進化する性質による独自の課題があります。実際、MLモデルがより高度になり、ますます多様なコンテンツを生成する能力を持つようになると、有害なまたは意図しない出力の可能性も増大し、堅牢なモデレーションと評価戦略の開発が必要になります。さらに、MLモデルの複雑さと処理するデータの膨大さは、潜在的なバイアスや倫理的な懸念を特定し対処する課題を悪化させます。 ホストとして、私たちはユーザーや世界全体に対して潜在的な害を拡大する責任を認識しています。これらの害は、特定の文脈に依存して少数派コミュニティに不公平に影響を与えることが多いです。私たちは、各文脈でプレイしている緊張関係を分析し、会社とHugging Faceコミュニティ全体で議論するアプローチを取っています。多くのモデルが害を増幅する可能性がありますが、特に差別的なコンテンツを含む場合、最もリスクの高いモデルを特定し、どのような対策を取るべきかを判断するための一連の手順を踏んでいます。重要なのは、さまざまなバックグラウンドを持つアクティブな視点が、異なる人々のグループに影響を与える潜在的な害を理解し、測定し、緩和するために不可欠であるということです。 私たちは、オープンソースの科学が個人を力付け、潜在的な害を最小限に抑えるために、ツールや保護策を作成するとともに、ドキュメンテーションの実践を改善しています。 倫理的なカテゴリ 私たちの仕事の最初の重要な側面は、価値観とステークホルダーへの配慮を優先するML開発のツールとポジティブな例を促進することです。これにより、ユーザーは具体的な手順を踏むことで未解決の問題に対処し、ML開発の標準的な実践に代わる可能性のある選択肢を提示することができます。 ユーザーが倫理に関連するMLの取り組みを発見し、関わるために、私たちは一連のタグを編纂しました。これらの6つの高レベルのカテゴリは、コミュニティメンバーが貢献したスペースの分析に基づいています。これらは、倫理的な技術について無専門用語の方法で考えるための設計されています: 厳密な作業は、ベストプラクティスを考慮して開発することに特に注意を払います。MLでは、これは失敗事例の検証(バイアスや公正性の監査を含む)、セキュリティ対策によるプライバシーの保護、および潜在的なユーザー(技術的および非技術的なユーザー)がプロジェクトの制約について知らされることを意味します。 コンセントフルな作業は、これらの技術を使用し、影響を受ける人々の自己決定を支援します。 社会的に意識の高い作業は、技術が社会、環境、科学の取り組みを支援する方法を示しています。 持続可能な作業は、機械学習を生態学的に持続可能にするための技術を強調し、探求します。 包括的な作業は、機械学習の世界でビルドし、利益を享受する人々の範囲を広げます。 探求的な作業は、コミュニティに技術との関係を再考させる不公正さと権力構造に光を当てます。 詳細はhttps://huggingface.co/ethicsをご覧ください。 これらの用語を探してください。新しいプロジェクトで、コミュニティの貢献に基づいてこれらのタグを使用し、更新していきます! セーフガード オープンリリースを「全てか無し」の視点で見ることは、MLアーティファクトのポジティブまたはネガティブな影響を決定する広範な文脈の多様性を無視しています。MLシステムの共有と再利用の方法に対するより多くの制御レバーがあることで、有害な使用や誤用を促進するリスクを減らすことができ、共同開発と分析をサポートします。よりオープンでイノベーションに参加できる環境を提供します。 私たちは、直接貢献者と関わり、緊急の問題に対処してきました。さらに進めるために、私たちはコミュニティベースのプロセスを構築しています。このアプローチにより、Hugging Faceの貢献者と貢献に影響を受ける人々の両方が、プラットフォームで利用可能なモデルとデータに関して制限、共有、追加のメカニズムについて情報提供することができます。私たちは、アーティファクトの起源、開発者によるアーティファクトの取り扱い、アーティファクトの使用状況について特に注意を払います。具体的には、次のような取り組みを行っています: コミュニティがMLアーティファクトやコミュニティコンテンツ(モデル、データセット、スペース、または議論)がコンテンツガイドラインに違反しているかどうかを判断するためのフラッグ機能を導入しました。 ハブのユーザーが行動規範に従っているかを確認するために、コミュニティのディスカッションボードを監視しています。 最もダウンロードされたモデルについて、社会的な影響やバイアス、意図された使用法と範囲外の使用法を詳細に説明するモデルカードを堅牢に文書化しています。…

フリーティアのGoogle Colabで🧨ディフューザーを使用してIFを実行中
要約:Google Colabの無料ティア上で最も強力なオープンソースのテキストから画像への変換モデルIFを実行する方法を紹介します。 また、Hugging Face Spaceでモデルの機能を直接探索することもできます。 公式のIF GitHubリポジトリから圧縮された画像。 はじめに IFは、ピクセルベースのテキストから画像への生成モデルで、DeepFloydによって2023年4月下旬にリリースされました。モデルのアーキテクチャは、GoogleのクローズドソースのImagenに強く影響を受けています。 IFは、Stable Diffusionなどの既存のテキストから画像へのモデルと比較して、次の2つの利点があります: モデルは、レイテントスペースではなく「ピクセルスペース」(つまり、非圧縮画像上で)で直接動作し、Stable Diffusionのようなノイズ除去プロセスを実行しません。 モデルは、Stable Diffusionでテキストエンコーダとして使用されるCLIPよりも強力なテキストエンコーダであるT5-XXLの出力で訓練されます。 その結果、IFは高周波の詳細(例:人の顔や手など)を持つ画像を生成する能力に優れており、信頼性のあるテキスト付き画像を生成できる最初のオープンソースの画像生成モデルです。 ピクセルスペースで動作し、より強力なテキストエンコーダを使用することのデメリットは、IFが大幅に多くのパラメータを持っていることです。T5、IFのテキストから画像へのUNet、IFのアップスケーラUNetは、それぞれ4.5B、4.3B、1.2Bのパラメータを持っています。それに対して、Stable Diffusion 2.1のテキストエンコーダとUNetは、それぞれ400Mと900Mのパラメータしか持っていません。 しかし、メモリ使用量を低減させるためにモデルを最適化すれば、一般のハードウェア上でもIFを実行することができます。このブログ記事では、🧨ディフューザを使用してその方法を紹介します。 1.)では、テキストから画像への生成にIFを使用する方法を説明し、2.)と3.)では、IFの画像バリエーションと画像インペインティングの機能について説明します。 💡 注意:メモリの利得と引き換えに速度の利得を得るために、IFを無料ティアのGoogle Colab上で実行できるようにしています。A100などの高性能なGPUにアクセスできる場合は、公式のIFデモのようにすべてのモデルコンポーネントをGPU上に残して、最大の速度で実行することをお勧めします。…

StarCoder:コードのための最先端のLLM
StarCoderの紹介 StarCoderとStarCoderBaseは、GitHubからの許可を得たデータを使用してトレーニングされた大規模な言語モデルです。これらのモデルは、80以上のプログラミング言語、Gitのコミット、GitHubの課題、Jupyterノートブックなど、様々な情報源からデータを取得しています。LLaMAと同様に、私たちは1兆トークンのために約15兆パラメータのモデルをトレーニングしました。また、35兆のPythonトークンに対してStarCoderBaseモデルを微調整し、新しいモデルであるStarCoderと呼びます。 StarCoderBaseは、人気のあるプログラミングベンチマークにおいて既存のオープンなコードモデルよりも優れたパフォーマンスを発揮し、GitHub Copilotの初期バージョンで使用された「code-cushman-001」といったクローズドモデルとも匹敵する結果を示しました。StarCoderモデルは、8,000以上のトークンのコンテキスト長を持つため、他のオープンなLLMよりも多くの入力を処理することができます。これにより、さまざまな興味深いアプリケーションが可能となります。例えば、StarCoderモデルに対して対話のシリーズをプロンプトとして与えることで、技術アシスタントとしての機能を果たすことができます。さらに、これらのモデルはコードの自動補完、指示に基づいたコードの変更、コードスニペットの自然言語による説明などにも使用することができます。私たちは、改善されたPIIの削除パイプライン、新しい帰属追跡ツールなど、安全なオープンモデルのリリースに向けていくつかの重要な手順を踏んでいます。また、StarCoderは改良されたOpenRAILライセンスのもとで一般に公開されています。この更新されたライセンスにより、企業がモデルを製品に統合するプロセスが簡素化されます。StarCoderモデルの強力なパフォーマンスにより、コミュニティは自分たちのユースケースや製品に適応させるための堅固な基盤としてこれを活用することができると考えています。 評価 私たちはStarCoderといくつかの類似モデルについて、さまざまなベンチマークで徹底的に評価を行いました。人気のあるPythonベンチマークであるHumanEvalでは、関数のシグネチャとドキュメント文字列に基づいてモデルが関数を完成させることができるかどうかをテストしました。StarCoderとStarCoderBaseは、PaLM、LaMDA、LLaMAなどの最大のモデルを上回るパフォーマンスを発揮しましたが、それらよりも遥かに小さなサイズであるという特徴も持っています。また、CodeGen-16B-MonoやOpenAIのcode-cushman-001(12B)モデルよりも優れた結果を示しました。私たちはまた、モデルの失敗例として、通常は練習の一部として使用されるため、# Solution hereというコードを生成することがあることに気付きました。実際の解決策を生成させるために、プロンプトとして<filename>solutions/solution_1.py\n# Here is the correct implementation of the code exerciseを追加しました。これにより、StarCoderのHumanEvalスコアは34%から40%以上に向上し、オープンモデルの最新のベンチマーク結果を更新しました。CodeGenとStarCoderBaseに対してもこのプロンプトを試しましたが、あまり違いは観察されませんでした。 StarCoderの興味深い特徴の一つは、多言語対応であることです。そのため、MultiPL-Eという多言語の拡張を使用して評価を行いました。その結果、StarCoderは多くの言語においてcode-cushman-001と匹敵または優れたパフォーマンスを発揮することがわかりました。また、DS-1000というデータサイエンスのベンチマークでも、StarCoderは他のオープンアクセスモデルを圧倒する結果を示しました。しかし、コード補完以外にもモデルができることを見てみましょう! 技術アシスタント 徹底的な評価の結果、StarCoderはコードの記述に非常に優れていることがわかりました。しかし、ドキュメンテーションやGitHubの課題などの情報を大量に学習しているため、技術アシスタントとして使用できるかどうかもテストしたかったのです。AnthropicのHHHプロンプトに触発されて、私たちはTech Assistant Promptを作成しました。驚くべきことに、プロンプトだけでモデルは技術アシスタントとして機能し、プログラミングに関連する要求に答えることができます! トレーニングデータ このモデルは、The…

倫理と社会ニュースレター#4:テキストから画像へのモデルにおけるバイアス
要約: テキストから画像へのモデルのバイアスを評価するためにより良い方法が必要です はじめに テキストから画像(TTI)生成は最近のトレンドであり、数千のTTIモデルがHugging Face Hubにアップロードされています。各モダリティは異なるバイアスの影響を受ける可能性がありますが、これらのモデルのバイアスをどのように明らかにするのでしょうか?このブログ投稿では、TTIシステムのバイアスの源泉、それらに対処するためのツールと潜在的な解決策について、私たち自身のプロジェクトと広範なコミュニティのものを紹介します。 画像生成における価値観とバイアスのエンコード バイアスと価値観には非常に密接な関係があります。特に、これらが与えられたテキストから画像モデルのトレーニングやクエリに埋め込まれている場合、この現象は生成された画像に大きな影響を与えます。この関係は、広範なAI研究分野で知られており、それに対処するためのかなりの努力が進行中ですが、特定のモデルで進化する人々の価値観を表現しようとする複雑さは依然として存在しています。これは、適切に明らかにし、対処するための持続的な倫理的な課題を提起します。 たとえば、トレーニングデータが主に英語である場合、それはおそらく西洋の価値観を伝えています。その結果、異なる文化や遠い文化のステレオタイプな表現が得られます。以下の例では、同じプロンプト「北京の家」に対してERNIE ViLG(左)とStable Diffusion v 2.1(右)の結果を比較すると、この現象が顕著に現れます: バイアスの源泉 近年、自然言語処理(Abidら、2021年)およびコンピュータビジョン(BuolamwiniおよびGebru、2018年)の両方の単一モダリティのAIシステムにおけるバイアス検出に関する重要な研究が行われています。MLモデルは人々によって構築されるため、すべてのMLモデル(そして技術全般)にはバイアスが存在します。これは、画像の中で特定の視覚的特性が過剰または過少に表現される(たとえば、オフィスワーカーのすべての画像にネクタイがある)ことや、文化的および地理的なステレオタイプの存在(たとえば、白いドレスとベールを着た花嫁のすべての画像、代表的な花嫁のイメージである赤いサリーの花嫁など)が現れることで現れます。AIシステムは広く異なるセクターやツール(例:Firefly、Shutterstock)に展開される社会技術的なコンテキストで展開されるため、既存の社会的なバイアスや不平等を強化する可能性があります。以下にバイアスの源泉の非徹底的なリストを示します: トレーニングデータのバイアス:テキストから画像への変換のための人気のあるマルチモーダルデータセット(たとえば、テキストから画像へのLAION-5B、画像キャプショニングのMS-COCO、ビジュアルクエスチョンアンサリングのVQA v2.0など)には、多数のバイアスや有害な関連が含まれていることが判明しています(Zhaoら、2017年、PrabhuおよびBirhane、2021年、Hirotaら、2022年)。これらのデータセットでトレーニングされたモデルには、画像生成の多様性の欠如や、文化やアイデンティティグループの共通のステレオタイプが永続化するという初期の結果がHugging Face Stable Biasプロジェクトから示されています。たとえば、CEO(右)とマネージャー(左)のDall-E 2の生成結果を比較すると、両方とも多様性に欠けていることがわかります: 事前トレーニングデータのフィルタリングにおけるバイアス:モデルのトレーニングに使用される前に、データセットに対して何らかの形のフィルタリングが行われることがよくあります。これにより、異なるバイアスが導入されます。たとえば、Dall-E 2の作者たちは、トレーニングデータのフィルタリングが実際にバイアスを増幅することを発見しました。これは、既存のデータセットが女性をより性的な文脈で表現するというバイアスや、使用されるフィルタリング手法の固有のバイアスに起因する可能性があると彼らは仮説を立てています。 推論におけるバイアス:Stable…
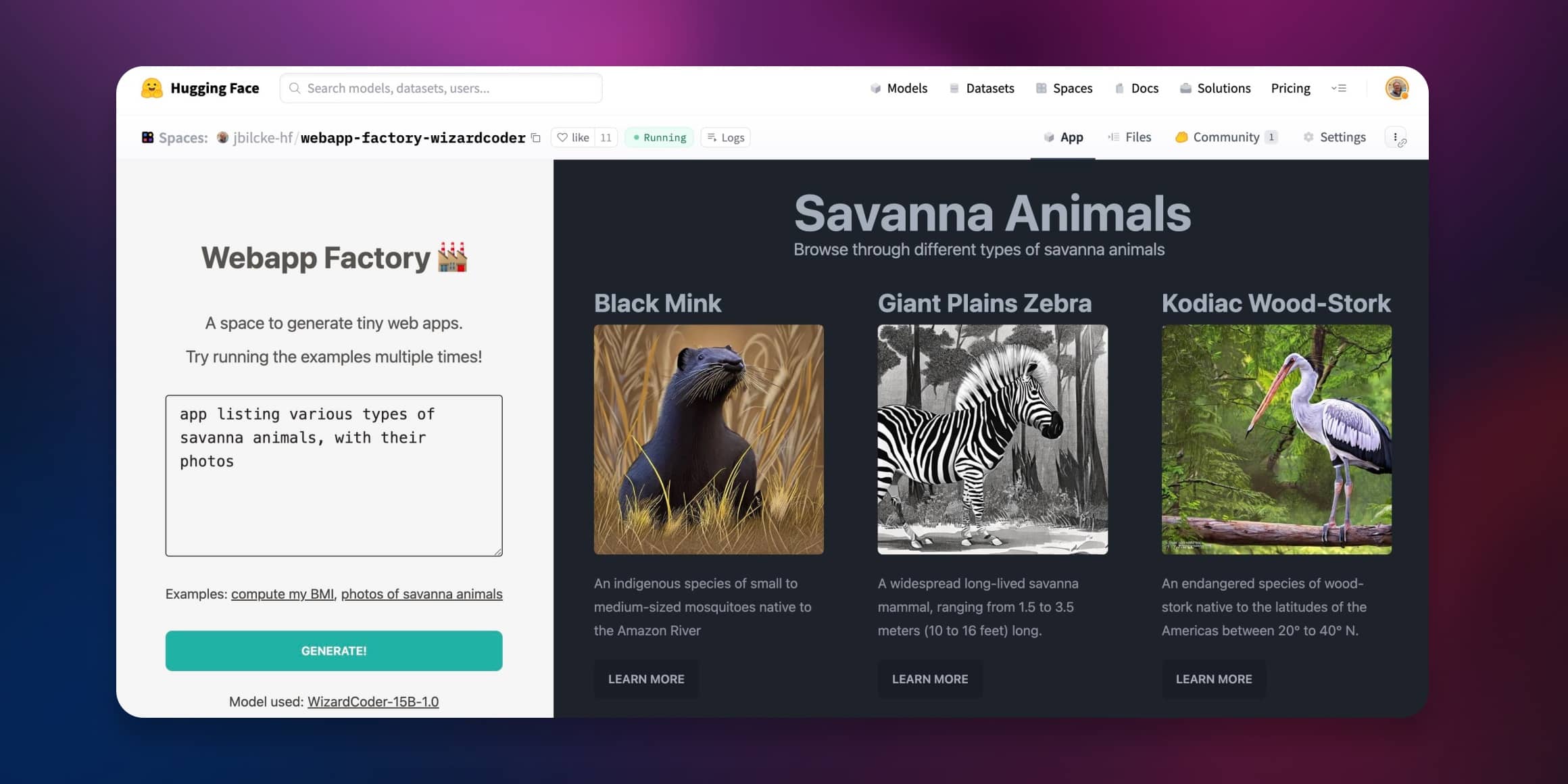
オープンなMLモデルを使用してWebアプリジェネレータを作成する
コード生成モデルがますます一般公開されるようになると、以前には想像もできなかった方法でテキストからウェブやアプリへの変換が可能になりました。 このチュートリアルでは、コンテンツのストリーミングとレンダリングを一度に行うことで、AIウェブコンテンツ生成への直接的なアプローチを紹介します。 ここでライブデモを試してみてください! → Webapp Factory NodeアプリでのLLMの使用方法 AIやMLに関連するすべてのことをPythonで行うと思われがちですが、ウェブ開発コミュニティではJavaScriptとNodeに大いに依存しています。 このプラットフォームで大きな言語モデルを使用する方法をいくつか紹介します。 ローカルでモデルを実行する JavaScriptでLLMを実行するためのさまざまなアプローチがあります。ONNXを使用したり、コードをWASMに変換して他の言語で書かれた外部プロセスを呼び出したりする方法などがあります。 これらの技術のいくつかは、次のような使いやすいNPMライブラリとして利用できます: コード生成をサポートするtransformers.jsなどのAI/MLライブラリの使用 ブラウザ用のllama-node(またはweb-llm)など、専用のLLMライブラリの使用 Pythoniaなどのブリッジを介してPythonライブラリを使用 ただし、このような環境で大きな言語モデルを実行すると、リソースをかなり消費することがあります。特にハードウェアアクセラレーションを使用できない場合はさらにリソースが必要です。 APIを使用する 現在、さまざまなクラウドプロバイダが言語モデルの使用を提案しています。以下はHugging Faceの提供するオプションです: コミュニティから小さなモデルからVoAGIサイズのモデルまで使用できる無料の推論API。 より高度で本番向けの推論エンドポイントAPIで、より大きなモデルやカスタム推論コードが必要な方向けのもの。 これらの2つのAPIは、NPM上のHugging Face推論APIライブラリを使用してNodeから利用できます。 💡…

GPT-3がMLOpsの将来に与える意味とは?デビッド・ハーシーと共に
この記事は元々MLOps Liveのエピソードであり、ML実践者が他のML実践者からの質問に答えるインタラクティブなQ&Aセッションです各エピソードは特定のMLトピックに焦点を当てており、このエピソードではGPT-3とMLOpsの特徴についてDavid Hersheyと話しましたYouTubeで視聴することができます Or...

2023年のMLOpsの景色:トップのツールとプラットフォーム
2023年のMLOpsの領域に深く入り込むと、多くのツールやプラットフォームが存在し、モデルの開発、展開、監視の方法を形作っています総合的な概要を提供するため、この記事ではMLOpsおよびFMOps(またはLLMOps)エコシステムの主要なプレーヤーについて探求します...

ジョージア工科大学の研究者が「ChattyChef」という料理レシピデータセットを紹介し、料理体験を革新します
人工知能(AI)は、ショッピングから計画立案、さらには文章作成まで、私たちの生活のさまざまな側面を革新しました。しかし、料理に関しては、AIは手順通りにステップバイステップのレシピを追うことに苦労してきました。この課題に気付いたジョージア工科大学のコンピュータ学部の研究者たちは、新たな研究によりこの分野で大きな進歩を遂げました。 研究チームは、ChattyChefというデータセットを開発しました。このデータセットは、自然言語処理モデルを利用してユーザーを料理のレシピにガイドするものです。オープンソースの大規模言語モデルGPT-Jの力を活用したChattyChefのデータセットは、ユーザーがレシピを進めるための料理の対話を含んでいます。 研究論文「Recipe-Grounded Conversationにおける改善された手順順序」では、研究者たちは大規模言語モデルを使用してAIシェフを構築する際の複雑さについて詳しく説明しています。これまでの料理における言語モデルのいくつかの試みは、ユーザーの意図を理解し、レシピの進行状況を正確に追跡することができないというモデルの能力不足により失敗に終わってきました。さらに、これらのモデルは、材料の量や調理時間に関する明確な回答を提供することにも苦労しています。 これらの課題に対処するために、研究者たちはモデルに2つの重要な機能を組み込みました。1つ目の機能は、ユーザーの意図を検出することで、ユーザーの意図が予め定義された可能性のあるセット内にあるかどうかを判断するのに役立ちます。2つ目の機能は、手順の進行状況を追跡することで、モデルがユーザーがどの具体的なステップにいるのかを識別することができ、80%の正確性を達成しています。 ユーザーの意図の検出と手順の進行状況の追跡の組み合わせにより、ChattyChefの第3のイノベーションである応答生成が可能となります。ユーザーの意図を活用することで、モデルはユーザーの質問に最も適した回答を生成します。同時に、手順の進行状況により、レシピの最も関連性のある部分を選択することができます。このアプローチは、料理の過程での混乱や不要なステップによるユーザーの負担を防ぐことを目指しています。 ChattyChefのデータセットは、WikiHowのレシピを基にしており、高評価を受け、8つのステップ以下のレシピが含まれています。研究者たちは、データセットを作成するためにクラウドソーシングを活用し、最適な手順を含めるためのシナリオプレイを行いました。 ChattyChefのイノベーションの潜在的な応用範囲は、料理の領域を超えて広がっています。研究者たちは、このアプローチが修理マニュアルやソフトウェアのドキュメンテーションなど、さまざまなドメインで活用できると考えています。 まとめると、研究チームは、大規模言語モデルを使用してAIシェフを構築する際の課題において大きな進歩を遂げました。ユーザーの意図の検出、手順の進行状況の追跡、最適化された応答生成を組み合わせることにより、彼らのChattyChefシステムは、ユーザーが料理のレシピに正確にアシストするという約束のある潜在能力を示しています。この研究は、AIの力により、ユーザーの体験を向上させ、複雑なタスクを簡素化する他のドメインへの広範な応用の可能性を開くものです。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.