Learn more about Search Results A - Page 243

- You may be interested
- 「OpenAIのAI検出ツールは、AIによって生...
- ウェアラブルテックを革命:エッジインパ...
- 「ハブスポット、ハブスポットAIおよび新...
- わずか3つのステップでOpenAIのGPT-Store...
- Swift 🧨ディフューザー – Mac用の...
- 「ジェネラティブAIを用いたERPと大規模企...
- 「LLMの利点:電子商取引の検索を変革する」
- 「インテルCPU上での安定したディフューシ...
- ブレイブがLeoを紹介:ウェブページやビデ...
- 「ベクトル検索だけでは十分ではありません」
- 「AIと芸術における可能性と破壊」
- 「データ可視化での色の使い方」
- 「マイクロソフト、Azureカスタムチップを...
- あなたのビジネスに適応型AIを実装する方法
- 「ODSC Europe 2023の写真とハイライト」

「ニューロンの多様性を受け入れる:AIの効率と性能の飛躍」
多様性の役割は、生物学から社会学まで、さまざまな分野で議論の対象となってきましたしかし、ノースカロライナ州立大学の非線形人工知能研究所(NAIL)の最近の研究は、この論争において興味深い次元を開くものです:人工知能(AI)ニューラルネットワーク内の多様性自己反省の力:内部でニューラルネットワークを調整するウィリアム・ディットー、[…]
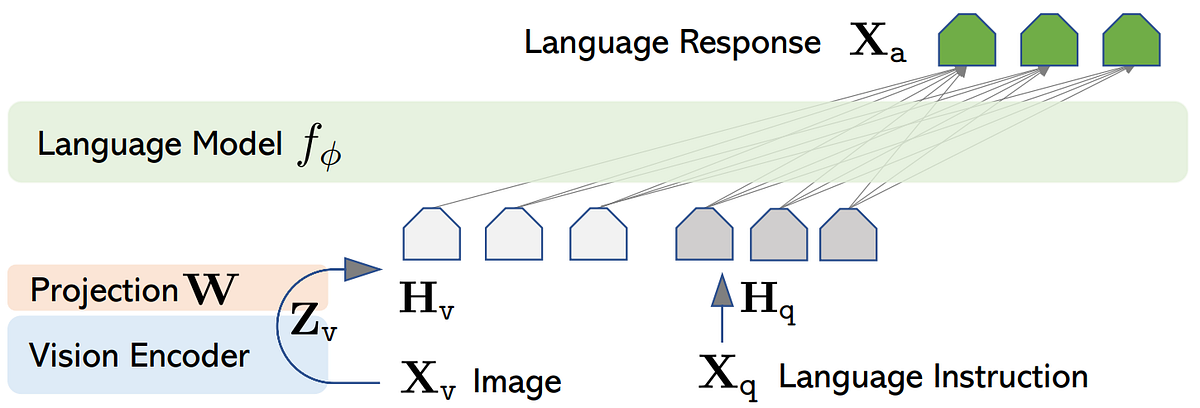
「第一の汎用ビジュアルと言語のAI LLaVA」
GPT-4は非常に強力ですが、それを完全に利用して構築されたAIがあることを知っていましたか? はい、GPT-4は非常に優れているため、他のAIモデルをトレーニングするために十分なデータを生成するために使用することができますそして、どんなモデルでもなく…

新しいChatGPT Promptエンジニアリング技術:プログラムシミュレーション
プロンプトエンジニアリングの世界は、さまざまなレベルで魅力的であり、ChatGPTのようなエージェントが特定の種類の応答を生成するための巧妙な方法は不足していませんテクニックとしては、...
『チュートリアルを超えて LangChainのPandasエージェントでデータ分析を学ぶ』
「Pandasは、豊富なAPIと直感的なデータ構造により、データ処理と分析においてPythonのデファクトライブラリとなりましたしかし、まだ学習のハードルが高いです」

「インセプション、MBZUAI、そしてCerebrasが『Jais』をオープンソース化:世界最先端のアラビア語大規模言語モデル」の記事が公開されました
大規模言語モデル(GPT-3など)とその社会への影響は、大いに関心と議論の的です。大規模言語モデルは、自然言語処理(NLP)の分野を大きく前進させました。それらは、翻訳、感情分析、要約、質問応答など、さまざまな言語関連のタスクの精度を向上させました。大規模言語モデルによって強化されたチャットボットや仮想アシスタントは、複雑な会話を処理する能力が向上しています。これらは、顧客サポート、オンラインチャットサービス、一部のユーザーにとってはさえ仲間として使用されています。 アラビア語の大規模言語モデル(LLM)を構築することは、アラビア語の特徴やその方言の多様性のために独自の課題を持ちます。他の言語の大規模言語モデルと同様に、アラビア語のLLMはトレーニングデータからバイアスを受け継ぐ可能性があります。これらのバイアスに対処し、アラビア語のコンテキストでのAIの責任ある使用を確保することは、継続的な関心事です。 Inception、Cerebras、Mohamed bin Zayed University of Artificial Intelligence(UAE)の研究者たちは、新しいアラビア語ベースの大規模言語モデルJaisとJais-chatを紹介しました。彼らのモデルは、GPT-3の生成的事前学習アーキテクチャに基づいており、たった13Bのパラメータのみを使用しています。 彼らの主な課題は、モデルのトレーニングのための高品質なアラビア語データを入手することでした。英語のデータに比べて、2兆トークンまでのコーパスが利用可能である一方、アラビア語のコーパスはかなり小さいものでした。コーパスとは、言語学、自然言語処理(NLP)、テキスト分析のための研究や言語モデルのトレーニングに使用される、大規模で構造化されたテキストのコレクションです。コーパスは、言語のパターン、意味論、文法などを研究するための貴重なリソースとして活用されます。 彼らは、これを解決するために、限られたアラビア語の事前トレーニングデータを豊富な英語の事前トレーニングデータで補完するためにバイリンガルモデルをトレーニングしました。彼らは、Jaisを3950億トークン、その中に72 billionのアラビア語トークンと2320億の英語トークンを含むように事前トレーニングしました。彼らは、高品質なアラビア語データを生成するために、徹底的なデータフィルタリングとクリーニングを含む専門のアラビア語テキスト処理パイプラインを開発しました。 彼らは、彼らのモデルの事前学習と微調整の機能が、既知のすべてのオープンソースのアラビア語モデルを上回り、より大規模なデータセットでトレーニングされた最新のオープンソースの英語モデルと同等であると述べています。LLMの固有の安全上の懸念を考慮し、彼らはさらに安全志向の指示で微調整しました。安全プロンプト、キーワードベースのフィルタリング、外部分類器の形で追加のガードレールを設けました。 彼らは、Jaisが中東のNLPとAIの景観の重要な進化と拡大を表していると述べています。それはアラビア語の理解と生成を前進させ、主権的でプライベートな展開オプションを持つ地元のプレーヤーを支援し、応用とイノベーションの活発なエコシステムを育成します。この研究は、より言語的に包括的で文化的に意識の高い時代を築くためのデジタルとAIの転換の広範な戦略的イニシアチブをサポートしています。
YOLOV8によるANPR
YOLO V8は、Ultralyticsチームによって開発された最新のモデルですこれまでの先行モデルと比べて精度と効率の両面で優れた状態にあります使いやすく、…

「データとテクノロジーのリーダーシップの現在の状況- チーフAIオフィサーがチーフデジタライゼーションオフィサーに置き換わるか?」
「私は最近、親しい友人であるテクノロジーの採用担当者と会話をしました私たちは以下の議論をしました:チーフAIオフィサーは、現在のテックリーダーシップの誰かを置き換えるのでしょうか…」
「AIプロジェクトに適したGPU戦略の選択」
「あなたが世界を変える革新的なAIソリューションを目指す新興企業であろうと、次の大きな科学的発見を探し求める熱心な研究者であろうと、疑問は変わりません...」

このAI論文では、Complexity-Impacted Reasoning Score(CIRS)を紹介していますこれは、大規模な言語モデルの推論能力を向上させるためのコードの複雑さの役割を評価するものです
大規模言語モデル(LLM)は、具現化された人工知能の問題解決における汎用的なアプローチとなっています。効率的な制御のためにエージェントが環境の意味的な微妙さを理解する必要がある場合、LLMの推論能力は具現化されたAIにおいて重要です。最近の方法である「思考のプログラム」では、プログラミング言語を課題を解決するための改善されたプロンプトシステムとして使用しています。思考のプログラムプロンプトは、チェーン思考プロンプトとは異なり、問題を実行可能なコードセグメントに分割し、それらを一度に処理します。ただし、プログラミング言語の使用とLLMの思考能力の関係については、まだ十分な研究が行われていません。思考のプログラムプロンプトは、どのような場合に推論に対して機能するのか、依然として重要な問いとなります。 本論文では、コードの推論段階とLLMの推論能力との関係を評価するための包括的な指標である「複雑度に影響を与える推論スコア(CIRS)」を提案しています。彼らは、プログラミング言語が複雑な構造のモデリングの改善された手法であるために、直列化された自然言語よりも優れていると主張しています。また、手続き志向の論理は、複数のステップを含む困難な思考を解決するのに役立ちます。そのため、彼らが提案する指標は、構造と論理の両面からコードの複雑さを評価します。具体的には、彼らは抽象構文木(AST)を使用してコードの推論段階(根拠)の構造的複雑さを計算します。彼らの方法では、ASTを木として表現するために3つのAST指標(ノード数、ノードタイプ、深さ)を使用し、コードの構造情報を包括的に理解します。 浙江大学、東海研究所、シンガポール国立大学の研究者は、HalstedとMcCabeの考え方に触発され、コーディングの難易度とサイクロマティック複雑度を組み合わせることで論理の複雑さを決定する方法を開発しました。したがって、コードの演算子、オペランド、制御フローを考慮することが可能です。彼らはコード内の論理の複雑さを明示的に計算することができます。彼らが提案するCIRSを使用した経験的な調査により、現在のLLMがコードなどの象徴的な情報を制限された理解しか持っていないこと、すべての複雑なコードデータがLLMによって教えられ理解されるわけではないことが明らかになりました。低複雑度のコードブロックは必要な情報が不足していますが、高複雑度のコードブロックはLLMにとって理解するのが難しすぎる場合があります。LLMの推論能力を効果的に向上させるためには、適切な複雑度(構造と論理の両方)を持つコードデータのみが必要です。 彼らは、推論能力に最も優れたデータを生成および除外するデータを自動的に合成して分類する方法を提供しています。彼らはこのアプローチを2つの異なる状況で使用しています:(1)数学的思考を必要とする活動のための手順の作成の指示の指示。 (2)コード作成を含む活動のためのコードデータのフィルタリング。彼らの提案する戦略は、数学的な推論においてベースラインモデルよりも優れた成績を収め、コード作成の課題においても成功を示しています。 この論文への彼らの貢献は以下の通りです: • 推論データの難しさを測定する独自のアプローチであるCIRSを提案しています。論理的および構造的な観点からコードデータを分析する彼らの方法は、コードの複雑さと推論能力の関係を正確に測定することができます。 • 異なる複雑度レベルの影響を経験的に分析し、LLMが学習できる適切な程度のコード言語をプログラムの思考プロンプトの推論能力の鍵として特定しています。 • 自動合成および分類アルゴリズムを作成し、数学的思考を必要とする仕事のためのコードデータのフィルタリングと指示の作成に彼らの方法を使用しています。多くの結果が彼らの提案する視点の有効性を支持しています。

メタAIのコンピュータビジョンにおける公平性のための2つの新しい取り組み:DINOv2のためのライセンス導入とFACETのリリースの紹介
コンピュータビジョンの絶え間ない進化の中で、公平性を確保することが急務となっています。この記事では、AI技術、特にコンピュータビジョンにおける広範な可能性について解説し、エコロジーの保護活動から画期的な科学的探求を支援するまで、さまざまなセクターで変革的な突破口となるカタリストとしての役割を果たしていることを明らかにしています。しかし、この技術の台頭に伴う潜在的なリスクについても率直に語っています。 Meta AIの研究者は、急速なイノベーションのリズムと必要とされる慎重な開発プラクティスの間で重要な均衡を取ることを強調しています。これらのプラクティスは単なる選択肢ではなく、歴史的に弱い立場にあるコミュニティにこの技術が誤って与える可能性のある損害から守るための重要な盾です。 Meta AIの研究者は、この多面的な課題に対応する包括的なロードマップを策定しています。まず、自己教師あり学習のための試練を経て鍛造された先進的なコンピュータビジョンモデルであるDINOv2を、オープンソースのApache 2.0ライセンスの下でより広範なユーザーに提供します。DINOv2は、コンピュータビジョンモデルの大幅な進歩を表すものです。セルフサプライズ学習の技術を利用して、普遍的な特徴を作り出し、高い柔軟性で画像を理解し解釈することができます。 DINOv2の能力は、従来の画像分類を超えています。セマンティックイメージセグメンテーションという多くのタスクで優れたパフォーマンスを発揮し、オブジェクトの境界を正確に識別し、意味のある領域に画像をセグメント化します。また、単眼の深度推定においても優れたパフォーマンスを発揮し、画像内のオブジェクトの空間的な奥行きを知覚することができます。この多様性により、DINOv2はコンピュータビジョンアプリケーションのパワーハウスとなります。このアクセシビリティの拡大により、開発者や研究者はDINOv2の強力な機能をさまざまなアプリケーションに活用し、コンピュータビジョンイノベーションのフロンティアをさらに押し進めることができます。 Metaのコンピュータビジョンにおける公平性への取り組みの核心は、FACET(FAirness in Computer Vision Evaluation)の導入によって明らかになります。FACETは、約50,000人を特集した驚異的なベンチマークデータセットであり、専門の人間注釈者による細心の注釈が特徴です。これらの専門家は、データセットを細心の注意を払って注釈付けし、さまざまな次元で分類しています。これには、認識されるジェンダープレゼンテーション、年齢層、認識される肌の色合いや髪型などの人口統計属性が含まれます。驚くべきことに、FACETは「バスケットボール選手」や「医師」といった職業など、人に関連するクラスを導入しています。さらに、研究目的のために69,000のマスクのラベルも含まれており、その意義が高まっています。 FACETを用いた初期の探索では、最先端のモデルが異なる人口集団間でのパフォーマンスの差異を明らかにしました。たとえば、これらのモデルは、より暗い肌色を持つ個人や巻き毛のある個人を正確に検出することに頻繁に課題を抱えており、注意深い検討が必要な潜在的なバイアスを明らかにしています。 FACETを使用したパフォーマンス評価では、最先端のモデルが人口集団間でのパフォーマンスの差異を示しています。たとえば、モデルはより暗い肌色を持つ個人を検出することに苦労し、巻き毛のある個人に対してはさらに困難を抱えることがあります。これらの差異は、コンピュータビジョンモデルにおけるバイアスの評価と軽減の必要性を強調しています。 FACETは主に研究評価のために設計されており、トレーニング目的ではありませんが、コンピュータビジョンモデルの公平性を評価するための第一級の基準として台頭する可能性があります。これにより、従来の人口統計属性を超えて人に関連するクラスを取り入れた、深い洞察に基づく公平性の評価が可能となります。 まとめると、Metaの記事は、コンピュータビジョン内の公平性問題についての警笛を鳴らし、FACETによって明らかになったパフォーマンスの差異を明るみに出しています。Metaの方法論は、DINOv2のような先進モデルへのアクセスの拡大と、先駆的なベンチマークデータセットの導入を含めた多面的なアプローチを強調しています。これにより、イノベーションの促進と倫理基準の維持、公平性の問題の緩和に対する彼らの不断の取り組みが浮き彫りになっています。それは、技術がすべての人々の福祉のために活用される公正なAIの景観を実現するための航海図を描いています。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.