Learn more about Search Results A - Page 242

- You may be interested
- ODSC West 2023の基調講演:責任ある生成A...
- 大規模言語モデルを使用したアプリを作成...
- 複雑なAIモデルの解読:パデュー大学の研...
- 「PolyLM(Polyglot Large Language Model...
- 2023年のトップDNSプライバシーツール
- 「研究者が量子コンピューティングのため...
- 誰が雨を止めるのか? 科学者が気候協力を...
- バイトダンスの研究者が「ImageDream」を...
- 「12か国がソーシャルメディア巨人に違法...
- 一緒にAIを学びましょう−Towards AIコミュ...
- 「アイデアからAIを活用したビジネスへ:A...
- 「5つの最高のオープンソースLLM」
- “`html ChatGPTでグラフ、チ...
- 「ビカス・アグラワルとともにデータサイ...
- 機械学習によるマルチビューオプティカル...

「AIがあなたの信念をリセットする方法」
AIへの嫌悪感が高まっていますインターネットやソーシャルメディアにはそれで溢れていますChatGPTの公開から数ヶ月後、私たちはますますAIへの嘲笑や冷笑、失望を目にするようになりました
「Declarai、FastAPI、およびStreamlitを使用したLLMチャットアプリケーション— パート2 🚀」
前回のVoAGI記事(リンク🔗)の人気を受けて、LLMチャットアプリケーションの展開について詳しく説明しました皆様からのフィードバックを参考に、この第二部ではさらに高度な内容を紹介します
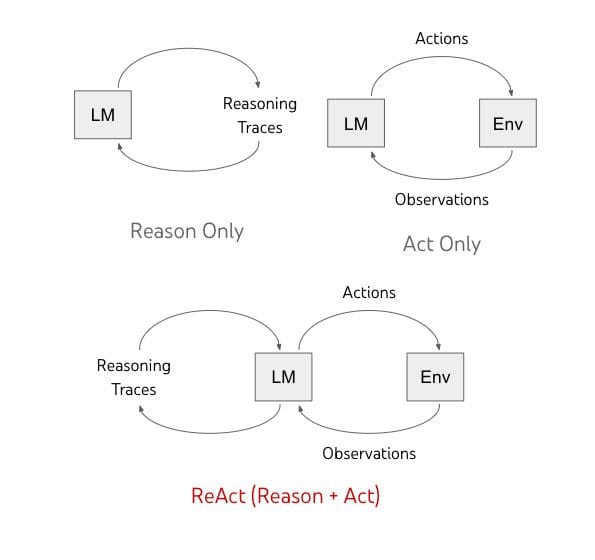
ReAct、Reasoning and Actingは、LLMをツールで拡張します!
「AIは推論と行動を融合させ、人間の知能を模倣するという大胆な新たな一歩を踏み出しています」

「WavJourney:オーディオストーリーライン生成の世界への旅」
「プロンプトからパワーへ:一つのスパークでストーリーや音声を解き放つ!」

アマゾンの研究者たちは、「HandsOff」という手法を紹介しましたこの手法は合成画像データの手動注釈を不要にするものです
機械学習(ML)モデルをコンピュータビジョンタスクに使用する際、ラベル付きのトレーニングデータに大いに依存しています。ただし、このデータを収集し、注釈を付けることは時間と労力がかかります。この問題に対する実現可能な解決策として、合成データが登場しましたが、合成データを生成するにしても、しばしば人間のアナリストによる手作業の注釈が必要です。 この問題に対処するための既存の手法は、一般に敵対的生成ネットワーク(GAN)を使用して合成画像を作成することです。GANは、識別器と生成器からなり、生成器は識別器を騙して本物の画像だと思わせることができる画像を生成することを学習します。GANは合成データの生成において有望な結果を示していますが、トレーニングには大量のラベル付きデータが必要であり、アノテーションされたデータが限られたシナリオでは効果が制限されます。 Amazonの研究者は、コンピュータビジョンとパターン認識会議(CVPR)で発表された「HandsOff」フレームワークという革新的なソリューションを紹介しました。HandsOffは、少数のラベル付き画像とGANを活用して、合成画像データの手動注釈の必要性を排除します。 HandsOffは、GANのパラメータを変更する代わりに、独立したGAN逆変換モデルを訓練して、本物の画像をGANの潜在空間上の点にマッピングするという新しいアプローチを採用しています。これにより、ラベル付き画像に基づいて点とラベルの小さなデータセットを作成し、GANの潜在空間上の点にラベルを付けることができる第3のモデルを訓練することができます。 HandsOffの重要なイノベーションは、学習された知覚的画像パッチ類似性(LPIPS)損失を使用してGAN逆変換モデルを微調整することです。LPIPSは、各モデル層に対してオブジェクト検出器などのコンピュータビジョンモデルの出力を比較することで、画像の類似性を測定します。真の潜在ベクトルと入力画像の推定潜在ベクトルの間のLPIPSの差を最小化するようにGAN逆変換モデルを最適化することで、研究者は完全に再構築されていないアイデアに対してもラベルの正確性を保証しています。 HandsOffは、セマンティックセグメンテーション、キーポイント検出、深度推定などの重要なコンピュータビジョンタスクで最先端のパフォーマンスを示しています。驚くべきことに、これは50枚未満の既存のラベル付き画像で達成されており、手動注釈を最小限に抑えながら高品質の合成データを生成するフレームワークの能力を示しています。 まとめると、HandsOffフレームワークは、コンピュータビジョンと機械学習の分野における興味深いブレイクスルーです。合成データの広範な手動注釈の必要性を排除することで、MLモデルのトレーニングに必要なリソースと時間を大幅に削減します。GAN逆変換とLPIPS最適化の組み合わせによって、生成されたデータのラベルの正確性が保証されることが示されています。本文では具体的な数量的指標については触れていませんが、最先端のパフォーマンスを達成したという主張は有望であり、さらなる調査が必要です。 全体として、HandsOffは、高品質なラベル付きデータへのアクセスを民主化し、さまざまなドメインや業界での利用を容易にすることにより、コンピュータビジョンの研究と応用の進歩に貢献するものとして期待されています。

このAI研究は、OpenAIの埋め込みを使用した強力なベクトル検索のためのLuceneの統合を提案します
最近、機械学習の検索分野において、深層ニューラルネットワークを応用することで大きな進歩がありました。特に、バイエンコーダーアーキテクチャ内の表現学習に重点を置いています。このフレームワークでは、クエリ、パッセージ、さらには画像などのマルチメディアなど、さまざまな種類のコンテンツが、密なベクトルとして表されるコンパクトで意味のある「埋め込み」として変換されます。このアーキテクチャに基づいて構築されたこれらの密な検索モデルは、大規模な言語モデル(LLM)内の検索プロセスの強化の基盤として機能します。このアプローチは人気があり、現在の生成的AIの広い範囲でLLMの全体的な能力を高めるのに非常に効果的であることが証明されています。 この論文では、多くの密なベクトルを処理する必要があるため、企業は「AIスタック」に専用の「ベクトルストア」または「ベクトルデータベース」を組み込むべきだと示唆しています。一部のスタートアップ企業は、これらのベクトルストアを革新的で不可欠な現代の企業アーキテクチャの要素として積極的に推進しています。有名な例には、Pinecone、Weaviate、Chroma、Milvus、Qdrantなどがあります。一部の支持者は、これらのベクトルデータベースが従来のリレーショナルデータベースをいずれ置き換える可能性さえ示しています。 この論文では、この説に対して反論を示しています。その議論は、既存の多くの組織で存在し、これらの機能に大きな投資がなされているという点を考慮した、簡単なコスト対効果分析を中心に展開されています。生産インフラストラクチャは、Elasticsearch、OpenSearch、Solrなどのプラットフォームによって主導されている、オープンソースのLucene検索ライブラリを中心とした広範なエコシステムによって支配されています。 https://arxiv.org/abs/2308.14963 上記の画像は、標準的なバイエンコーダーアーキテクチャを示しており、エンコーダーがクエリとドキュメント(パッセージ)から密なベクトル表現(埋め込み)を生成します。検索はベクトル空間内のk最近傍探索としてフレーム化されています。実験は、ウェブから抽出された約880万のパッセージから構成されるMS MARCOパッセージランキングテストコレクションに焦点を当てて行われました。評価には、標準の開発クエリとTREC 2019およびTREC 2020 Deep Learning Tracksのクエリが使用されました。 調査結果は、今日ではLuceneを直接使用してOpenAIの埋め込みを使用したベクトル検索のプロトタイプを構築することが可能であることを示唆しています。埋め込みAPIの人気の増加は、私たちの主張を支持しています。これらのAPIは、コンテンツから密なベクトルを生成する複雑なプロセスを簡素化し、実践者にとってよりアクセスしやすくしています。実際には、今日の検索エコシステムを構築する際に必要なのはLuceneだけです。しかし、時間が経って初めて正しいかどうかがわかります。最後に、これはコストと利益を比較することが主要な考え方であり続けることを思い起こさせてくれるものです。急速に進化するAIの世界でも同様です。
「NumPyとPandasの入門」
「Pythonでの数値計算とデータ操作におけるNumpyとPandasの使用方法についての入門書」

「ChatGPTをより優れたソフトウェア開発者にする:SoTaNaはソフトウェア開発のためのオープンソースAIアシスタントです」
私たちが行っている方法は、近年急速に変化しています。私たちはほとんどのタスクに仮想アシスタントを使用し、自分たちがタスクをAIエージェントに委任し続ける必要性を感じるようになっています。 これらの進歩をすべて推進する鍵となるのは、ソフトウェアです。ますます技術主導の世界で、ソフトウェア開発は、医療からエンターテイメントまで、さまざまなセクターでのイノベーションの鍵となります。ただし、ソフトウェア開発の道のりはしばしば複雑さと課題に満ちており、開発者に迅速な問題解決と創造的な思考を求めます。 そのため、AIアプリケーションはソフトウェア開発の領域で急速に広まっています。それらはプロセスを容易にし、開発者にコーディングに関するタイムリーな回答を提供し、彼らの努力をサポートします。つまり、おそらくあなたも使っているでしょう。ChatGPTの代わりにStackOverflowに行ったのはいつですか?また、GitHubのコパイロットをインストールしているときにTabキーを何回押しますか? ChatGPTとCopilotは素晴らしいですが、ソフトウェア開発でより良く機能するためには、適切に指示する必要があります。今日は、新しいプレイヤー、SoTaNaに会いましょう。 SoTaNaは、LLMsの能力を活用してソフトウェア開発の効率を向上させるソフトウェア開発アシスタントです。ChatGPTやGPT4などのLLMsは、人間の意図を理解し、人間らしい応答を生成する能力を示しています。テキストの要約やコード生成など、さまざまなドメインで価値を持っています。ただし、特定の制約のためにアクセシビリティが制限されていましたが、SoTaNaはこれに対処することを目指しています。 SoTaNaは、開発者とLLMsの広大な潜在能力とのギャップを埋めることを目指すオープンソースのソフトウェア開発アシスタントとして中心的な役割を果たします。この取り組みの主な目的は、限られた計算リソースを使用しながら、基礎となるLLMsが開発者の意図を理解する能力を高めることです。この研究では、ChatGPTを使用してソフトウェアエンジニアリングのタスクに基づいた高品質な指示ベースのデータを生成するための多段階のアプローチを取ります。 SoTaNaの概要。出典:https://arxiv.org/pdf/2308.13416.pdf プロセスは、新しいインスタンスを生成するための要件を詳細に説明する特定のプロンプトを使用してChatGPTをガイドすることから始まります。正確さと所望の出力との整合性を確保するために、ソフトウェアエンジニアリングに関連するインスタンスの手動で注釈付けされたシードプールが参照として機能します。このプールはさまざまなソフトウェアエンジニアリングのタスクを網羅し、新しいデータの生成の基盤となります。巧妙なサンプリング技術を使用することで、このアプローチはデモンストレーションのインスタンスを効果的に多様化し、要件を満たす高品質なデータの作成を確保します。 人間の意図をよりよく理解するために、SoTaNaは、限られた計算リソースを使用して、オープンソースの基礎モデルであるLLaMAを強化するために、パラメータ効率の良いファインチューニング手法であるLoraを採用しています。このファインチューニングプロセスにより、モデルはソフトウェアエンジニアリングのドメイン内での人間の意図の理解が洗練されます。 データ生成に使用されるプロンプト。出典:https://arxiv.org/pdf/2308.13416.pdf SoTaNa(ソータナ)の機能は、Stack Overflowの質問応答データセットを使用して評価され、人間の評価を含めて、開発者の支援におけるモデルの効果を強調しています。 SoTaNa(ソータナ)は、開発者の意図を理解し、関連する回答を生成することができるLLMをベースにしたオープンソースソフトウェア開発アシスタントを世界に紹介します。さらに、ソフトウェアエンジニアリングに特化した高品質の指示ベースのデータセットとモデルの重みを公開することで、コミュニティへの重要な貢献を行っています。これらのリソースは、将来の研究とイノベーションを加速する可能性を秘めています。

「NTUシンガポールの研究者が、3Dポイントクラウドからの正確な人間のポーズと形状の推定のためのAIフレームワークであるPointHPSを提案する」という文です
人工知能の分野でのいくつかの進歩により、最近では人の姿勢と形状の推定(HPS)はますます重要な研究分野となっています。モーションキャプチャ、バーチャル試着、混合現実など、さまざまな実用的な応用があり、3Dの人体復元は大きな課題となっています。ポーズの推定や体の配置、さらには3D空間での個人の形状や物理的特性の分析は、このプロセスの一部です。例えば、SMPLモデルのようなパラメトリックな人体モデルを使用することがあります。これらのモデルは、人体の形状や位置の特徴を表現します。 最近の研究では、実世界の環境で取得されたポイントクラウドからの正確な3D HPSのための体系的なフレームワークであるPointHPSが導入されました。PointHPSは、各イテレーションでポイントの特性を繰り返し改良する階層的な設計を使用しています。入力のポイントクラウドデータは、各段階でさまざまなダウンサンプリングとアップサンプリングの技術によって処理される反復的な改良プロセスを経ます。これらのプロセスは、データからローカルおよびグローバルな手がかりを抽出するためのものです。 PointHPSには、特徴抽出手法を改善するための2つの最先端のモジュールが組み込まれています。1つ目はクロスステージ特徴融合(CFF)で、これは複数のスケールの特徴伝播を可能にするモジュールであり、さまざまなネットワークステージ間で効率的な情報伝達を可能にします。これにより、文脈の保存と情報のキャプチャが支援されます。2つ目はIFE(中間特徴強化)で、これは人体の構造を意識した特徴の収集に焦点を当てています。各ステージの後、特徴の品質が向上し、正確な姿勢と形状の推定に適しています。 チームは、さまざまな条件下での徹底的な評価を提供するために2つの大規模なベンチマークでテストを実施しました。 実世界のデータセット:このデータセットには、実際の商用センサを使用してラボで記録されたさまざまな参加者とアクションが含まれています。より困難で現実的な環境を表しています。 データセット生成:このデータセットは、忙しい屋外のような実際の条件を考慮して入念に作成されました。さまざまな環境パラメータを制御することも可能です。 広範なテストにより、PointHPSがポイント特徴の抽出と処理において最先端の手法を凌駕していることが明らかになりました。CFFおよびIFEモジュールによって改善された提案された階層的なアーキテクチャの効果は、削除実験によってさらに裏付けられています。チームは、追加のポイントクラウド研究におけるHPSに使用するために、事前学習済みモデル、コード、データをリリースする予定です。将来の研究では、実世界のポイントクラウドデータから正確な3D人体位置と形状を推定する能力が向上し、この分野での研究がより容易になるでしょう。

XLang NLP研究所の研究者がLemurを提案:テキストとコードの能力をバランスさせた最先端のオープンプリトレーニング済み大規模言語モデル
言語とテクノロジーの交差点によってますます推進される世界において、多目的かつ強力な言語モデルの需要はかつてなく高まっています。従来の大規模言語モデル(LLM)は、テキストの理解やコーディングのタスクに優れていましたが、両者の間に調和の取れたバランスを築くことはめったにありませんでした。この不均衡は、テキストの推論やコーディングの能力をシームレスにナビゲートできるモデルの市場においてギャップを残しました。そこで、このギャップを埋めることを目指す、オープンな事前学習済みおよび監督されたファインチューニングされたLLMの分野に革新的な貢献をする2つのプロジェクト、LemurとLemur-chatが登場します。 テキストとコードの両方を適切に処理できる言語モデルを作成することは、長年の課題でした。既存のLLMは通常、テキストの理解またはコーディングのタスクに特化していましたが、両方に優れているものはほとんどありませんでした。この特化は、開発者や研究者が一方の領域で優れているモデルと他方では不十分なモデルの選択を迫られることになりました。その結果、理解、推論、計画、コーディング、コンテキストの基礎を含む多面的なスキルセットを提供できるLLMの需要が生じました。 従来のLLMの形でいくつかの解決策が存在しますが、その限界は明白でした。業界には、テキストとコードに関連するタスクの複雑な要求を真にバランスさせることができるモデルが不足していました。これにより、言語モデルエージェントの風景には、理解、推論、コーディングの統合的なアプローチが必要とされる空白が生じました。 XLang LabとSalesforce Researchの共同研究によって率いられるLemurプロジェクトは、この言語モデル技術における重要なギャップを埋めることを目指しています。LemurとLemur-chatは、テキストとコードに関連するタスクの両方に優れた性能を発揮するオープンで事前学習済みで監督されたファインチューニングされたLLMを開発する先駆的な試みを表しています。この取り組みの基盤は、Llama 2の広範な事前学習による、約1000億行のコード集中データのコーパスです。この事前学習フェーズの後には、公開された教育および対話データの約30万のインスタンスでの監督されたファインチューニングが続きます。その結果、テキストの推論と知識のパフォーマンスを競争力を維持しながら、コーディングと基礎づけの能力が向上した言語モデルが得られます。 LemurとLemur-chatの性能指標は、その能力を証明しています。Lemurは、コーディングのベンチマークで他のオープンソース言語モデルを凌駕し、そのコーディング能力を示しています。同時に、テキストの推論と知識ベースのタスクにおいて競争力を維持し、その多目的なスキルセットを示しています。一方、Lemur-chatは、さまざまな次元で他のオープンソースの監督されたファインチューニングモデルを大きく上回る優れた能力を示しており、テキストとコードを結ぶ会話の文脈での優れた能力を示しています。 Lemurプロジェクトは、XLang LabとSalesforce Researchの共同研究によるものであり、Salesforce Research、Google Research、Amazon AWSの寛大な寄付による支援を受けています。バランスの取れたオープンソース言語モデルに向けた旅はまだ途中ですが、Lemurの貢献は既に言語モデル技術の風景を変え始めています。テキストとコードに関連するタスクの両方で優れた性能を発揮するモデルを提供することで、Lemurは、言語とテクノロジーの複雑な交差点を航海しようとする開発者、研究者、組織にとって、強力なツールを提供します。 まとめると、Lemurプロジェクトは、言語モデルの世界における革新の象徴です。テキストとコードに関連するタスクを調和的にバランスさせる能力は、この分野における長年の課題に取り組んできました。Lemurは、さらなる研究を推進し、オープンソース言語モデルのより強力でバランスの取れた基盤を確立することを約束しながら、進化し続けることで、言語モデル技術の未来はこれまで以上に明るく多目的になります。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.