Learn more about Search Results HTML - Page 241

- You may be interested
- 「Amazon SageMakerのトレーニングワーク...
- 「MLの学習に勇気を持つ:L1&L2正則化の...
- PythonでのZeroからAdvancedなPromptエン...
- 「トップAIオーディオエンハンサー(2023...
- CycleGANによる画像から画像への変換
- シンガポール国立大学の研究者が提案するM...
- 「Pythonでのプロトコル」
- 「サーモン 大規模な言語モデルのための一...
- mPLUG-Owl2をご紹介しますこれは、モダリ...
- Google AIがSpectronを導入:スペクトログ...
- これらの新しいツールは、AIビジョンシス...
- 他人のPythonコードを簡単に理解する方法は?
- 実験追跡ツールの構築方法[Neptuneのエン...
- マックス・プランク研究所の研究者たちは...
- 「Stitch FixにおけるMLプラットフォーム...

Pythonを使用して北極の氷の傾向を分析する
Pythonは、データサイエンスのための卓越したプログラミング言語として、計測データを収集・クリーニング・解釈することが容易になりますPythonを使って、予測をバックテストし、モデルを検証することができますそして...

事前学習済みのViTモデルを使用した画像キャプショニングにおけるVision Transformer(ViT)
はじめに 事前学習済みのViTモデルを使用した画像キャプショニングは、画像の詳細な説明を提供するために画像の下に表示されるテキストまたは書き込みのことを指します。つまり、画像をテキストの説明に翻訳するタスクであり、ビジョン(画像)と言語(テキスト)を接続することで行われます。この記事では、PyTorchバックエンドを使用して、画像のViTを主要な技術として使用して、トランスフォーマーを使用した画像キャプショニングの生成方法を、スクラッチから再トレーニングすることなくトレーニング済みモデルを使用して実現します。 出典: Springer 現在のソーシャルメディアプラットフォームや画像のオンライン利用の流行に対応するため、この技術を学ぶことは、説明、引用、視覚障害者の支援、さらには検索エンジン最適化といった多くの理由で役立ちます。これは、画像を含むプロジェクトにとって非常に便利な技術であります。 学習目標 画像キャプショニングのアイデア ViTを使用した画像キャプチャリング トレーニング済みモデルを使用した画像キャプショニングの実行 Pythonを使用したトランスフォーマーの利用 この記事で使用されたコード全体は、このGitHubリポジトリで見つけることができます。 この記事は、データサイエンスブログマラソンの一環として公開されました。 トランスフォーマーモデルとは何ですか? ViTについて説明する前に、トランスフォーマーについて理解しましょう。Google Brainによって2017年に導入されて以来、トランスフォーマーはNLPの能力において注目を集めています。トランスフォーマーは、入力データの各部分の重要性を異なる重み付けする自己注意を採用して区別されるディープラーニングモデルです。これは、主に自然言語処理(NLP)の分野で使用されています。 トランスフォーマーは、自然言語のようなシーケンシャルな入力データを処理しますが、トランスフォーマーは一度にすべての入力を処理します。注意機構の助けを借りて、入力シーケンスの任意の位置にはコンテキストがあります。この効率性により、より並列化が可能となり、トレーニング時間が短縮され、効率が向上します。 トランスフォーマーアーキテクチャ 次に、トランスフォーマーのアーキテクチャの構成を見てみましょう。トランスフォーマーアーキテクチャは、主にエンコーダー-デコーダー構造から構成されています。トランスフォーマーアーキテクチャのエンコーダー-デコーダー構造は、「Attention Is All You Need」という有名な論文で発表されました。 エンコーダーは、各レイヤーが入力を反復的に処理することを担当し、一方で、デコーダーレイヤーはエンコーダーの出力を受け取り、デコードされた出力を生成します。単純に言えば、エンコーダーは入力シーケンスをシーケンスにマッピングし、それをデコーダーに供給します。デコーダーは、出力シーケンスを生成します。 ビジョン・トランスフォーマーとは何ですか?…

2023年に知っておくべきトップ10のパワフルなデータモデリングツール
イントロダクション データ駆動型の意思決定の時代において、競争力を維持するために正確なデータモデリングツールを持つことは企業にとって不可欠です。新しい開発者として、堅牢なデータモデリングの基礎は、データベースを効果的に扱うために重要です。適切に構成されたデータ構造は、スムーズなワークフローを確保し、データの損失や誤配置を防止します。 大規模で複雑なタスクに取り組むために、データモデリングツールを利用することがますます重要になっています。これらのツールは時間を節約するだけでなく、データモデリングのプロセスを簡素化することができます。 トランスフォーメーションに寄与するトップ10のデータモデリングツールを発見してください。効率性を求める経験豊富なプロフェッショナルから、ユーザーフレンドリーなソリューションを求める初心者まで、あなたのニーズに合わせて提供します。データの真のポテンシャルを引き出し、自信を持って賢い決定をする旅に出ましょう! データモデリングツールとは何ですか? データモデルは、UML図を使用してしばしば視覚的にデータ仕様を表します。データはSQLまたはNoSQLデータベースに格納され、データモデリングにはどの情報を収集し、どのように格納するかを決定することが含まれます。 データモデリングツールは、データモデリングプロセスを効率化するために使用されます。これらのツールは、データとその複数のモデル層との間のギャップを埋めます。これらのツールは、既存のデータベースをリバースエンジニアリングし、スキーマとモデルを比較およびマージし、自動的にデータベーススキーマまたはDTDを生成することができます。 効果的なデータモデリングソフトウェアは、魅力的な視覚的表現とデータベースとのシームレスな統合を提供します。ユーザーフレンドリーなデータモデリングツールは、概念的なデータモデリングをよりアクセスしやすくします。 データモデリングツールを選ぶ際に考慮すべきことは何ですか? データモデリングツールを選ぶ際には、特定のニーズを決定することが重要です。必須要件と望ましい要件を分類し、後者を優先させます。この決定は長期的な影響を持つ可能性があるため、組織内のさまざまな視点からの意見を考慮してください。 すべてのデータモデリングツールが物理モデルと論理モデルの作成、リバースエンジニアリング、およびフォワードエンジニアリングなどの基本的なタスクを処理できますが、追加の要因も考慮する必要があります。これには、チームベースのモデリング機能、バージョニング、図のカスタマイズオプション、モデルリポジトリの機能、概念的なデータモデルのサポート、エンタープライズメタデータリポジトリとの統合、および異なるモデルレベル(概念的、論理的、物理的)にわたるオブジェクトラインの維持のためのデータ合理化が含まれます。これらの要因は、あなたのデータモデリングニーズについての情報を提供し、適切な選択をするのに役立ちます。 トップ10のデータモデリングツール 1. ER/Studio Embarcadero Technologiesが開発したER/Studioは、データアーキテクト、モデラー、DBA、ビジネスアナリストにとって有用であり、データベース設計とデータ再利用を管理するために役立ちます。ツールによって、データベースコードを自動的に生成することができます。 属性と定義の完全なドキュメントを備えたツールは、ビジネスコンセプトをモデリングするのに役立ちます。 特徴 論理モデルと物理モデルの両方をサポート ツールによって、新しいデータベースの変更に対する影響分析が実施されます。 自動化とスクリプトのサポート サポートされるプレゼンテーションファイルの種類には、HTML、PNG、JPEG、RTF、XML、Schema、DTDが含まれます。 ER/Studioによって、モデルとデータベースの一貫性が保証されます。 価格…

紛争のトレンドとパターンの探索:マニプールのACLEDデータ分析
はじめに データ分析と可視化は、複雑なデータセットを理解し、洞察を効果的に伝えるための強力なツールです。この現実世界の紛争データを深く掘り下げる没入型探索では、紛争の厳しい現実と複雑さに深く踏み込みます。焦点は、長期にわたる暴力と不安定状態によって悲惨な状況に陥ったインド北東部のマニプール州にあります。私たちは、武装紛争ロケーション&イベントデータプロジェクト(ACLED)データセット[1]を使用し、紛争の多面的な性質を明らかにするための詳細なデータ分析の旅に出ます。 学習目標 ACLEDデータセットのデータ分析技術に熟達する。 効果的なデータ可視化のスキルを開発する。 脆弱な人口に対する暴力の影響を理解する。 紛争の時間的および空間的な側面に関する洞察を得る。 人道的ニーズに対処するための根拠に基づくアプローチを支援する。 この記事は、データサイエンスブログマラソンの一環として公開されました。 利害の衝突 このブログで提示された分析と解釈に責任を持つ特定の組織や団体はありません。目的は、紛争分析におけるデータサイエンスの潜在力を紹介することです。さらに、これらの調査結果には個人的な利益や偏見が含まれておらず、紛争のダイナミクスを客観的に理解するアプローチが確保されています。データ駆動型の方法を促進し、紛争分析に関する広範な議論に情報を提供するために、積極的に利用することを推奨します。 実装 なぜACLEDデータセットを使用するのか? ACLEDデータセットを活用することで、データサイエンス技術の力を活用することができます。これにより、マニプール州の状況を理解するだけでなく、暴力に関連する人道的側面にも光を当てることができます。ACLEDコードブックは、このデータセット[2]で使用されるコーディングスキームと変数に関する詳細な情報を提供する包括的な参考資料です。 ACLEDの重要性は、共感的なデータ分析にあります。これにより、マニプール州の暴力に関する理解が深まり、人道的ニーズが明らかにされ、暴力の解決と軽減に貢献します。これにより、影響を受けるコミュニティに平和で包摂的な未来が促進されます。 このデータ駆動型の分析により、貴重な洞察力を得るだけでなく、マニプール州の暴力の人的コストにも光が当てられます。ACLEDデータを精査することで、市民人口、強制的移動、必要なサービスへのアクセスなど、地域で直面する人道的現実の包括的な描写が可能になります。 紛争のイベント まず、ACLEDデータセットを使用して、マニプール州の紛争のイベントを調査します。以下のコードスニペットは、インドのACLEDデータセットを読み込み、マニプール州のデータをフィルタリングして、形状が(行数、列数)のフィルタリングされたデータセットを生成します。フィルタリングされたデータの形状を出力します。 import pandas as pd # ACLEDデータをダウンロードして国別のcsvをインポートする…

マルチヘッドアテンションを使用した注意機構の理解
はじめに Transformerモデルについて詳しく学ぶ良い方法は、アテンションメカニズムについて学ぶことです。特に他のタイプのアテンションメカニズムを学ぶ前に、マルチヘッドアテンションについて学ぶことは良い選択です。なぜなら、この概念は少し理解しやすい傾向があるためです。 アテンションメカニズムは、通常の深層学習モデルに追加できるニューラルネットワークレイヤーと見なすことができます。これにより、重要な部分に割り当てられた重みを使用して、入力の特定の部分に焦点を当てるモデルを作成することができます。ここでは、マルチヘッドアテンションメカニズムを使用して、アテンションメカニズムについて詳しく見ていきます。 学習目標 アテンションメカニズムの概念 マルチヘッドアテンションについて Transformerのマルチヘッドアテンションのアーキテクチャ 他のタイプのアテンションメカニズムの概要 この記事は、データサイエンスブログマラソンの一環として公開されました。 アテンションメカニズムの理解 まず、この概念を人間の心理学から見てみましょう。心理学では、注意は他の刺激の影響を除外して、イベントに意識を集中することです。つまり、他の注意を引くものがある場合でも、私たちは選択したものに焦点を合わせます。注意は全体の一部に集中します。 これがTransformerで使用される概念です。彼らは入力のターゲット部分に焦点を当て、残りの部分を無視することができます。これにより、非常に効果的な方法で動作することができます。 マルチヘッドアテンションとは? マルチヘッドアテンションは、Transformerにおいて中心的なメカニズムであり、ResNet50アーキテクチャにおけるskip-joiningに相当します。場合によっては、アテンドするべきシーケンスの複数の他の点があります。全体の平均を見つける方法では、重みを分散させて多様な値を重みとして与えることができません。これにより、複数のアテンションメカニズムを個別に作成するアイデアが生まれ、複数のアテンションメカニズムが生じます。実装では、1つの機能に複数の異なるクエリキー値トリプレットが表示されます。 出典:Pngwing.com 計算は、アテンションモジュールが何度も反復し、アテンションヘッドとして知られる並列レイヤーに組織化される方法で実行されます。各別のヘッドは、入力シーケンスと関連する出力シーケンスの要素を独立して処理します。各ヘッドからの累積スコアは、すべての入力シーケンスの詳細を組み合わせた最終的なアテンションスコアを得るために組み合わされます。 数式表現 具体的には、キーマトリックスとバリューマトリックスがある場合、値をℎサブクエリ、サブキー、サブバリューに変換し、アテンションを独立して通過させることができます。連結すると、ヘッドが得られ、最終的な重み行列でそれらを組み合わせます。 学習可能なパラメータは、アテンションに割り当てられた値であり、各パラメータはマルチヘッドアテンションレイヤーと呼ばれます。以下の図はこのプロセスを示しています。 これらの変数を簡単に見てみましょう。Xの値は、単語埋め込みの行列の連結です。 行列の説明 クエリ:シーケンスのターゲットについての洞察を提供する特徴ベクトルです。クエリは、何がアテンションを必要としているかをシーケンスに要求します。 キー:要素に含まれるものを説明する特徴ベクトルです。クエリによってアテンションが与えられ、要素のアイデンティティを提供します。 値:…
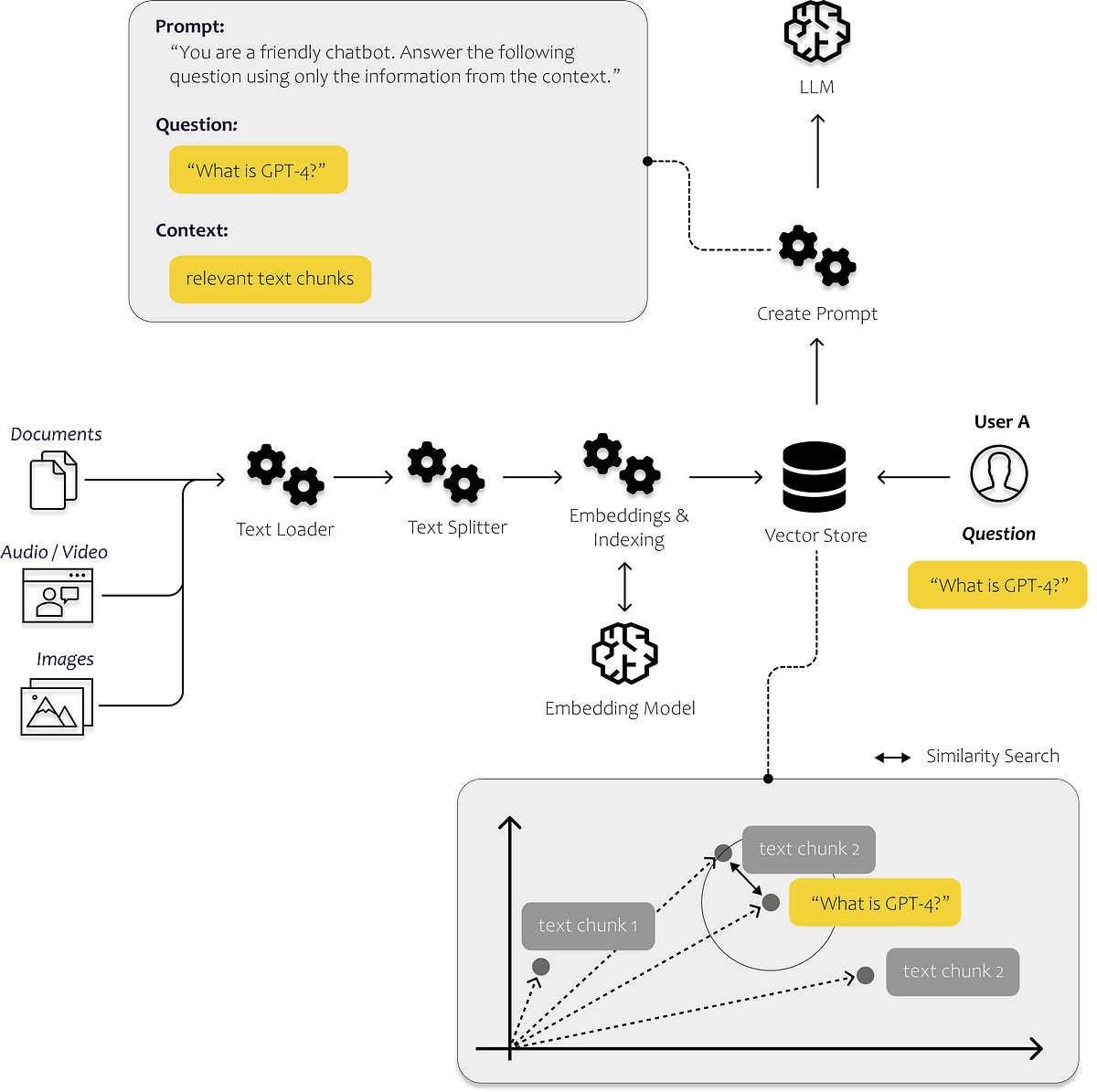
最初のLLMアプリを構築するために知っておく必要があるすべて
言語の進化は、私たち人類を今日まで非常に遠くまで導いてきましたそれによって、私たちは知識を効率的に共有し、現在私たちが知っている形で協力することができるようになりましたその結果、私たちのほとんどは...

LlamaIndex インデックスと検索のための究極のLLMフレームワーク
LlamaIndex(以前はGPT Indexとして知られていました)は、データ取り込みを容易にする必須ツールを提供することで、LLMを使用したアプリケーションの構築を支援する注目すべきデータフレームワークです
超幾何分布の理解
二項分布は、データサイエンスの内外でよく知られた分布ですしかし、あなたはその人気のないいところのいとこである超幾何分布について聞いたことがありますか?もしそうでない場合、この投稿をご覧ください...

SparkとPlotly Dashを使用したインタラクティブで洞察力のあるダッシュボードの開発
クラウドデータレイクは、すべてのタイプ(構造化および非構造化)のデータのスケーラブルで低コストなリポジトリとして、エンタープライズ組織に広く採用されています分析には多くの課題があります...

PDFの変換:PythonにおけるTransformerを用いた情報の要約化
はじめに トランスフォーマーは、単語の関係を捉えることにより正確なテキスト表現を提供し、自然言語処理を革新しています。PDFから重要な情報を抽出することは今日不可欠であり、トランスフォーマーはPDF要約の自動化に効率的な解決策を提供します。トランスフォーマーの適応性により、これらのモデルは法律、金融、学術などのさまざまなドキュメント形式を扱うのに貴重なものになっています。この記事では、トランスフォーマーを使用したPDF要約を紹介するPythonプロジェクトを紹介します。このガイドに従うことで、読者はこれらのモデルの変革的な可能性を活かし、広範なPDFから洞察を得ることができます。自動化されたドキュメント分析のためにトランスフォーマーの力を活用し、効率的な旅に乗り出しましょう。 学習目標 このプロジェクトでは、読者は以下の学習目標に沿った重要なスキルを身につけることができます。 トランスフォーマーの複雑な操作を深く理解し、テキスト要約などの自然言語処理タスクの取り組み方を革新する。 PyPDF2などの高度なPythonライブラリを使用してPDFのパースとテキスト抽出を行う方法を学び、さまざまなフォーマットとレイアウトの扱いに関する複雑さに対処する。 トークン化、ストップワードの削除、ユニークな文字やフォーマットの複雑さに対処するなど、テキスト要約の品質を向上させるための必須の前処理技術に精通する。 T5などの事前学習済みトランスフォーマーモデルを使用して、高度なテキスト要約技術を適用することで、トランスフォーマーの力を引き出す。PDFドキュメントの抽出的要約に対応する実践的な経験を得る。 この記事はData Science Blogathonの一部として公開されました。 プロジェクトの説明 このプロジェクトでは、Pythonトランスフォーマーの可能性を活かして、PDFファイルの自動要約を実現することを目的としています。PDFから重要な詳細を抽出し、手動分析の手間を軽減することを目指しています。トランスフォーマーを使用してテキスト要約を行うことで、文書分析を迅速化し、効率性と生産性を高めることを目指しています。事前学習済みのトランスフォーマーモデルを実装することで、PDFドキュメント内の重要な情報を簡潔な要約にまとめることを目指しています。トランスフォーマーを使用して、プロジェクトでPDF要約を合理化するための専門知識を提供することがプロジェクトの目的です。 問題の説明 PDFドキュメントから重要な情報を抽出するために必要な時間と人的労力を最小限に抑えることは、大きな障壁です。長いPDFを手動で要約することは、手間のかかる作業であり、人的ミスによる限界と、膨大なテキストデータを扱う能力の限界があります。これらの障壁は、PDFが多数存在する場合には効率性と生産性を著しく阻害します。 トランスフォーマーを使用してこのプロセスを自動化する重要性は過小評価できません。トランスフォーマーの変革的な能力を活用することで、PDFドキュメントから重要な洞察、注目すべき発見、重要な議論を包括する重要な詳細を自律的に抽出することができます。トランスフォーマーの展開により、要約ワークフローが最適化され、人的介入が軽減され、重要な情報の取得が迅速化されます。この自動化により、異なるドメインの専門家が迅速かつ適切な意思決定を行い、最新の研究に精通し、PDFドキュメントの膨大な情報を効果的にナビゲートできるようになります。 アプローチ このプロジェクトにおける私たちの革新的なアプローチは、トランスフォーマーを使用してPDFドキュメントを要約することです。私たちは、完全に新しい文を生成するのではなく、元のテキストから重要な情報を抽出する抽出的テキスト要約に重点を置くことにします。これは、PDFから抽出された重要な詳細を簡潔かつ分かりやすくまとめることがプロジェクトの目的に合致しています。 このアプローチを実現するために、以下のように進めます。 PDFのパースとテキスト抽出: PyPDF2ライブラリを使用してPDFファイルをナビゲートし、各ページからテキストコンテンツを抽出します。抽出されたテキストは、後続の処理のために細心の注意を払ってコンパイルされます。 テキストエンコードと要約: transformersライブラリを使用して、T5ForConditionalGenerationモデルの力を利用します。事前に学習された能力を持つこのモデルは、テキスト生成タスクにとって重要な役割を果たします。モデルとトークナイザを初期化し、T5トークナイザを使用して抽出されたテキストをエンコードし、後続のステップで適切な表現を確保します。 要約の生成:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.