Learn more about Search Results arXiv - Page 23

- You may be interested
- 『Re Invent 2023の私のお勧め』
- OpenAIの需要急増により、ChatGPT Plusの...
- 「Apache Sparkにおけるメモリ管理:ディ...
- 「バイオメトリクスをサイバーセキュリテ...
- チャットGPT vs Gemini:AIアリーナでのタ...
- 「AV 2.0、自動運転車における次のビッグ...
- Google DeepMindは、画期的なAI音楽生成器...
- vLLMについて HuggingFace Transformersの...
- 「Amazon SageMakerは、企業がユーザーをS...
- チャットGPTの潜在能力を引き出すためのプ...
- GraphStormによる高速グラフ機械学習:企...
- AIのオリンピック:機械学習システムのベ...
- 「初心者向けの14のエキサイティングなPyt...
- シンガポールがAIワークフォースを3倍に増...
- 「LK-99超伝導体:突破かもしれない、新た...

最初のデシジョン トランスフォーマーをトレーニングする
以前の投稿で、transformersライブラリでのDecision Transformersのローンチを発表しました。この新しい技術は、Transformerを意思決定モデルとして使用するというもので、ますます人気が高まっています。 今日は、ゼロからオフラインのDecision Transformerモデルをトレーニングして、ハーフチータを走らせる方法を学びます。このトレーニングは、Google Colab上で直接行います。こちらで見つけることができます👉 https://github.com/huggingface/blog/blob/main/notebooks/101_train-decision-transformers.ipynb *ジムのHalfCheetah環境でオフラインRLを使用して学習された「専門家」Decision Transformersモデルです。 ワクワクしませんか?では、始めましょう! Decision Transformersとは何ですか? Decision Transformersのトレーニング データセットの読み込みとカスタムデータコレータの構築 🤗 transformers Trainerを使用したDecision Transformerモデルのトレーニング 結論 次は何ですか? 参考文献 Decision Transformersとは何ですか? Decision…
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
BERTopicとHugging Face Hubの統合をご紹介します
私たちは、BERTopic Pythonライブラリの重要なアップデートを発表して大変喜んでいます。これにより、トピックモデリングの愛好家や実践者のためのワークフローがさらに効率化され、機能が拡張されました。BERTopicは、Hugging Face Hubへのトレーニング済みトピックモデルの直接プッシュとプルをサポートするようになりました。この新しい統合により、BERTopicのパワーを生かして製品の使用例でのトピックモデリングが簡単に行えるようになりました。 トピックモデリングとは何ですか? トピックモデリングは、ドキュメントのグループ内に隠れたテーマや「トピック」を明らかにするのに役立つメソッドです。ドキュメント内の単語を分析することで、これらの潜在的なトピックを明らかにするパターンや関連性を見つけることができます。たとえば、機械学習に関するドキュメントは、「勾配」や「埋め込み」といった単語を使用する可能性が高く、パンの焼き方に関するドキュメントとは異なります。 各ドキュメントは通常、異なる比率で複数のトピックをカバーしています。単語の統計を調べることで、これらのトピックを表す関連する単語のクラスタを特定することができます。これにより、ドキュメントの分析と、それぞれのドキュメント内のトピックのバランスを決定することができます。より最近では、トピックモデリングの新しいアプローチでは、単語の使用ではなく、Transformerベースのモデルなど、より豊かな表現を使用するようになりました。 BERTopicとは何ですか? BERTopicは、さまざまな埋め込み技術とc-TF-IDFを使用して、トピックモデリングのプロセスを簡素化し、重要な単語をトピックの説明に保持しながら、密なクラスタを作成する最新のPythonライブラリです。 BERTopicライブラリの概要 BERTopicは初心者でも簡単に始めることができますが、ガイド付き、教師付き、半教師付き、およびマニュアルトピックモデリングなど、トピックモデリングのさまざまな高度なアプローチをサポートしています。最近では、BERTopicはマルチモーダルトピックモデルもサポートしています。BERTopicには、視覚化ツールの豊富なセットもあります。 BERTopicは、テキストコレクション内の重要なトピックを明らかにするための強力なツールを提供し、貴重な洞察を得ることができます。BERTopicを使用すると、顧客のレビューを分析したり、研究論文を探索したり、ニュース記事をカテゴリ分けしたりすることが容易になります。テキストデータから意味のある情報を抽出したいと考えている人にとって、これは必須のツールです。 Hugging Face Hubを使用したBERTopicモデルの管理 最新の統合により、BERTopicのユーザーはトレーニング済みのトピックモデルをHugging Face Hubにシームレスにプッシュおよびプルすることができます。この統合により、異なる環境でのBERTopicモデルの展開と管理が簡素化されるという重要なマイルストーンが達成されました。 BERTopicモデルのトレーニングとハブへのプッシュは、数行で行うことができます from bertopic import BERTopic topic_model…

24GBのコンシューマーGPUでRLHFを使用して20B LLMを微調整する
私たちは、trlとpeftの統合を正式にリリースし、Reinforcement Learningを用いたLarge Language Model (LLM)のファインチューニングを誰でも簡単に利用できるようにしました!この投稿では、既存のファインチューニング手法と競合する代替手法である理由を説明します。 peftは一般的なツールであり、多くのMLユースケースに適用できますが、特にメモリを多く必要とするRLHFにとって興味深いです! コードに直接深く入りたい場合は、TRLのドキュメンテーションページで直接例のスクリプトをチェックしてください。 イントロダクション LLMとRLHF 言語モデルとRLHF(Reinforcement Learning with Human Feedback)を組み合わせることは、ChatGPTなどの非常に強力なAIシステムを構築するための次の手段として注目されています。 RLHFを用いた言語モデルのトレーニングは、通常以下の3つのステップを含みます: 1- 特定のドメインまたは命令のコーパスで事前学習されたLLMをファインチューニングする 2- 人間によって注釈付けされたデータセットを収集し、報酬モデルをトレーニングする 3- ステップ1で得られたLLMを報酬モデルとデータセットを用いてRL(例:PPO)でさらにファインチューニングする ここで、ベースとなるLLMの選択は非常に重要です。現時点では、多くのタスクに直接使用できる「最も優れた」オープンソースのLLMは、命令にファインチューニングされたLLMです。有名なモデルとしては、BLOOMZ、Flan-T5、Flan-UL2、OPT-IMLなどがあります。これらのモデルの欠点は、そのサイズです。まともなモデルを得るには、少なくとも10B+スケールのモデルを使用する必要がありますが、モデルを単一のGPUデバイスに合わせるだけでも40GBのGPUメモリが必要です。 TRLとは何ですか? trlライブラリは、カスタムデータセットとトレーニングセットアップを使用して、誰でも簡単に自分のLMをRLでファインチューニングできるようにすることを目指しています。他の多くのアプリケーションの中で、このアルゴリズムを使用して、ポジティブな映画のレビューを生成するモデルをファインチューニングしたり、制御された生成を行ったり、モデルをより毒性のないものにしたりすることができます。…
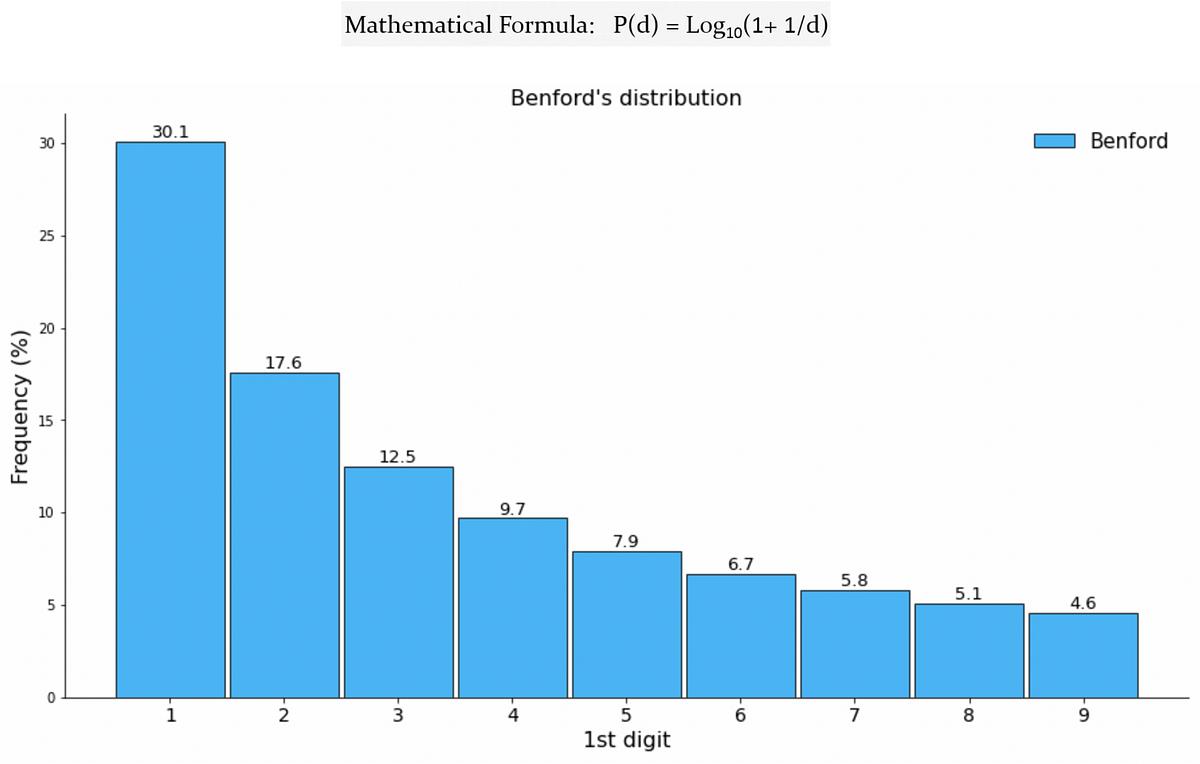
Benfordの法則が機械学習と出会って、偽のTwitterフォロワーを検出する
ソーシャルメディアの広大なデジタル領域において、ユーザーの真正性は最も重要な懸念事項ですTwitterなどのプラットフォームが成長するにつれ、フェイクアカウントの増加も増えていますこれらのアカウントは本物のアカウントを模倣します

FermiNet(フェルミネット):第一原理に基づく量子物理学と化学
最近Physical Review Researchに掲載された論文では、ディープラーニングが現実世界のシステムの量子力学の基礎方程式を解くのにどのように役立つかを示していますこれは重要な基礎科学的な問題だけでなく、将来的には実用的な用途につながる可能性がありますこれにより、研究者は実験室で作る前に、シリコン上で新しい材料や化学合成を試作することができます本日、この研究からのコードも公開される予定ですこれにより、計算物理学や化学のコミュニティは私たちの研究を基にさまざまな問題に応用することができます私たちは、大きな電子の集合体である化学結合の量子状態をモデル化するのに適した新しいニューラルネットワークアーキテクチャ、Fermionic Neural NetworkまたはFermiNetを開発しましたFermiNetは、原子や分子のエネルギーを最初の原理から計算するためのディープラーニングの最初のデモンストレーションであり、これまでで最も正確なニューラルネットワーク手法ですDeepMindのAI研究で開発されたツールやアイデアが自然科学の基本的な問題の解決に役立ち、FermiNetはタンパク質の折りたたみ、ガラス状のダイナミクス、格子量子色力学などのプロジェクトとともに、そのビジョンを実現するための取り組みに加わります

データ、アーキテクチャ、または損失:マルチモーダルトランスフォーマーの成功に最も貢献する要素は何ですか?
この研究では、マルチモーダルトランスフォーマーの成功において、注意機構、損失関数、事前学習データといった要素が重要であるかどうかを検証します私たちは、言語と画像のトランスフォーマーが互いに注意を払うマルチモーダルな注意機構が、これらのモデルの成功に重要であることを発見しました他の種類の注意機構を持つモデル(深さやパラメーターが増えていても)は、マルチモーダルな注意機構を持つ浅くて小さいモデルと比較して同等の結果を達成することができません

世界のデータを処理できるアーキテクチャの構築
今日のAIシステムで使用されるほとんどのアーキテクチャは、専門的なものです2Dの残差ネットワークは画像処理には適していますが、自動運転車で使用されるLidar信号やロボット工学で使用されるトルクなどの他の種類のデータには最適な選択肢ではありませんさらに、標準的なアーキテクチャは通常、1つのタスクのみを考慮して設計されており、エンジニアはしばしば入出力を再構築、歪曲、または他の方法で変更する必要がありますこれによって標準的なアーキテクチャが問題を正しく処理できるように期待します音声や画像など、複数の種類のデータを扱う場合はさらに複雑であり、単純なタスクでも多くの異なる部品から構成される複雑で手動チューニングされたシステムが必要になることが通常ですDeepMindの使命である科学と人類の進歩のために知能を解決するために、私たちは多くの種類の入力と出力を使用する問題を解決できるシステムを構築したいと考え、あらゆる種類のデータを処理できるより一般的かつ柔軟なアーキテクチャを探求し始めました

新しい方法で純粋な数学の美しさを探索する
100年以上前、スリニヴァーサ・ラマヌジャンは、他の誰も気づかなかった数の驚くべきパターンを見る非凡な能力で数学界を驚かせましたこのインド出身の独学の数学者は、彼の洞察を深く直感的で霊的なものとしており、パターンはしばしば鮮やかな夢の中で彼に現れました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.