Learn more about Search Results - Page 23

- You may be interested
- 「ビームサーチ:シーケンスモデルでよく...
- 『大数の法則の解明』
- 「教師付き機械学習と集合論を通じた現実...
- 「生成AI、基礎モデル、および大規模言語...
- 「2023年のAIに関するガートナー・ハイプ...
- 「教室外での、オンライン試験による無指...
- このAI研究では、ドライブ可能な3Dガウス...
- 「自然言語処理の技術比較:RNN、トランス...
- 「隠れマルコフモデルの力を解読する」
- マイクロソフトと香港浸会大学の研究者が...
- ChatGPTはナップサック問題を解決できます...
- トゥギャザーアイは、ShortおよびLongコン...
- すべてのMicrosoftとODSCの提携オファリング
- 「LLMの内部構造:言語モデルアーキテクチ...
- 「連邦裁判官 – AI によって生成さ...
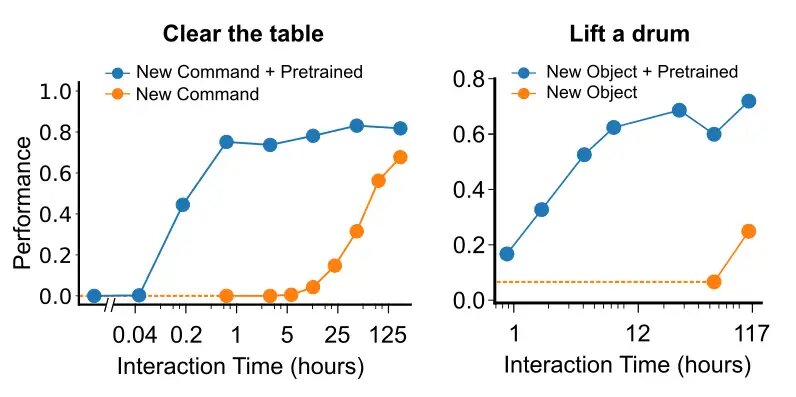
模倣学習を用いたインタラクティブエージェントの作成
私たちは、シミュレートされた世界での人間-人間の相互作用の模倣学習と自己教師あり学習の組み合わせによって、非敵対的な人間との対話に成功する多様なインタラクティブエージェント(MIAと呼ぶ)を生み出すことができることを示しますMIAは、非敵対的な人間との対話において75%の成功率を達成しますさらに、階層的なアクション選択などのアーキテクチャとアルゴリズムの技術を特定し、パフォーマンスを向上させることができます

言語モデルによるレッドチーミング:言語モデルによる言語モデル
私たちの最近の論文では、言語モデル自体を使用して入力を生成することで、言語モデルから有害なテキストを引き出す可能性があることを示しています私たちのアプローチは、ユーザーに影響を与える前に有害なモデルの振る舞いを見つけるためのツールの一つとして提供されますが、見つけた後の有害な行動を見つけるために必要な他の多くの技術と一緒に考えるべきであると強調しています
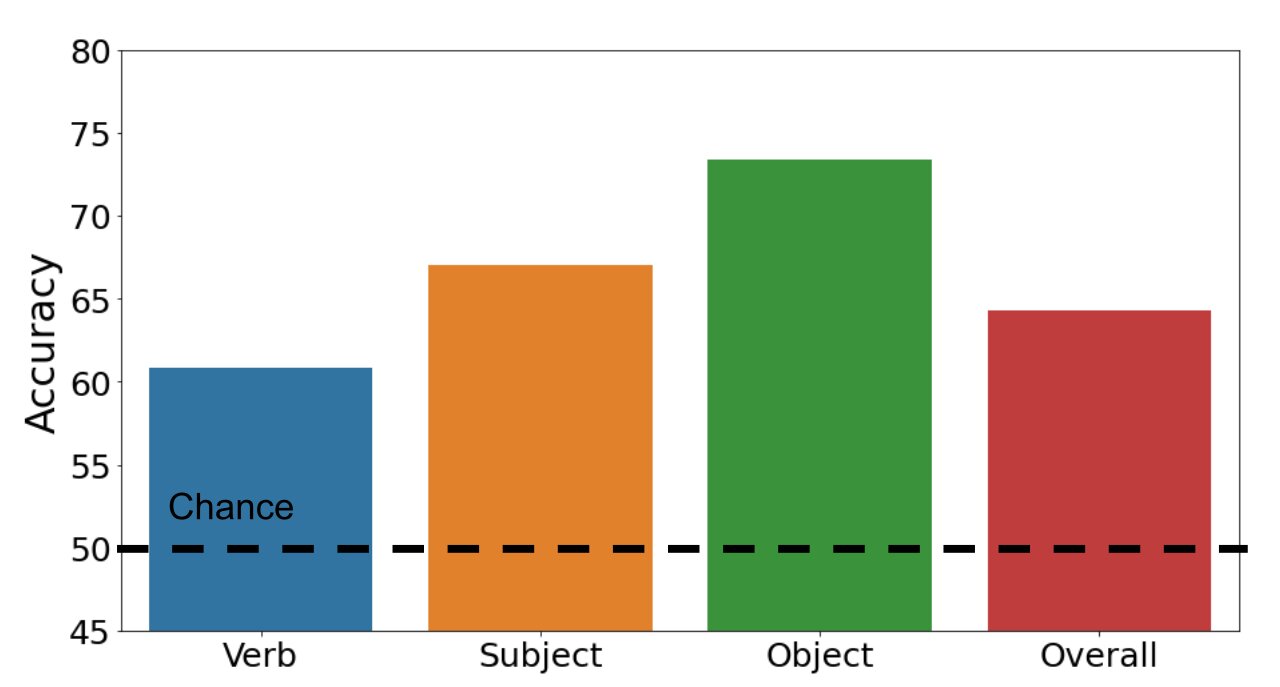
動詞理解のための画像言語トランスフォーマーの調査
マルチモーダル画像言語トランスフォーマーは、微調整に依存するさまざまなタスク(例:視覚的な質問応答や画像検索)で印象的な結果を達成しています私たちは、事前学習された表現の品質について明らかにし、特にこれらのモデルが動詞を区別できるのか、与えられた文において名詞のみを使用するのかどうかに興味がありますそのために、視覚的なものまたは事前学習データ(つまり、Conceptual Captionsデータセット)で一般的に見つかる447の動詞からなる画像-文のペアのデータセットを収集しますこのデータセットを使用して、事前学習モデルをゼロショットで評価します

人間のデータなしでの堅牢なリアルタイム文化伝達の学習
この研究では、ディープ強化学習を使用して、テスト時の文化的伝達が可能な人工エージェントを生成します訓練後、私たちのエージェントは、専門家が示したナビゲーションの知識を推測し、思い出すことができますこの知識の転送はリアルタイムで行われ、以前に見たことのないタスクの広範な領域に一般化します

アイザカと共に過去を予測する
人類の文章の誕生は、歴史の夜明けを告げ、過去の文明と私たちが今日生きている世界の理解に不可欠です例えば、約2,500年前、ギリシャ人は石、陶器、金属に書き込みを始め、借用契約や法律、カレンダーや神託など、地中海地域に関する詳細な情報を記録しました残念ながら、これは不完全な記録です多くの保存された碑文は、数世紀にわたって損傷を受けたり、元の場所から移動されたりしていますさらに、放射性炭素年代測定などの現代の年代測定技術は、これらの資料には使用できないため、碑文の解釈は困難で時間がかかります

コンピュート最適な大規模言語モデルトレーニングの経験的分析
私たちは次の問いに取り組みます「与えられた計算予算に対して、最適なモデルのサイズとトレーニングトークンの数は何か?」この質問に答えるために、私たちはさまざまなサイズのモデルをトレーニングし、さまざまなトークンの数で推定を行います私たちの主な結論は、現在の大規模言語モデルは、計算予算に対して非常に大きすぎる上に、十分なデータでトレーニングされていないということです

ベースとブラスへの情熱が、より良いツールの構築に役立つとき
今週、私たちはDevToolsチームのソフトウェアエンジニアであるケビン・ミリキンに会いました彼はSalt Lake Cityで行われるPyCon USという、オープンソースのPythonプログラミング言語を使用および開発する人々のための最大の年次イベントでプレゼンを行います
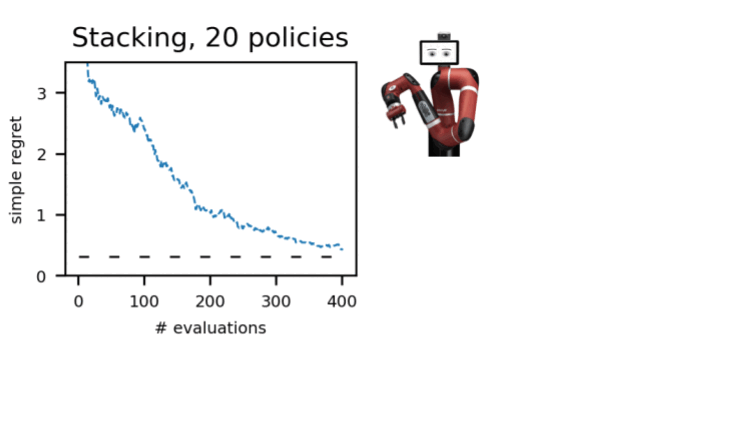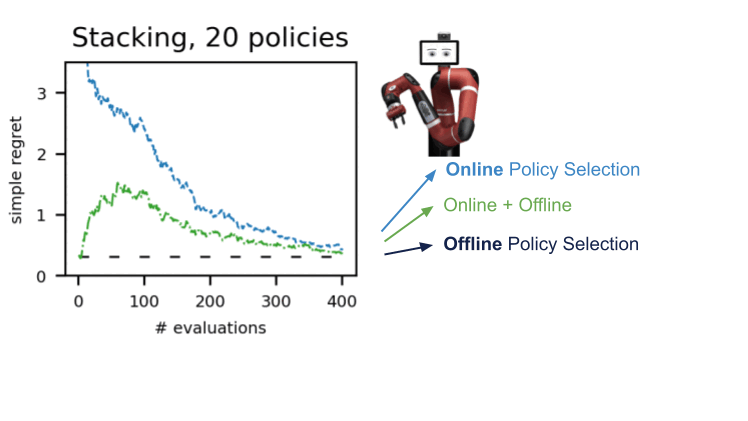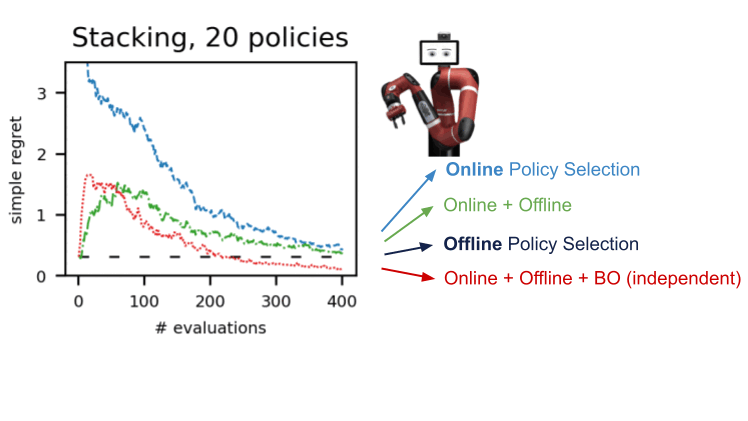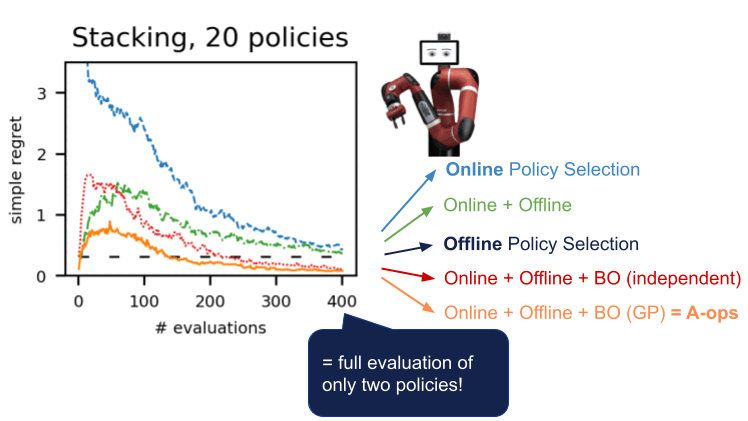
オフラインでのアクティブなポリシー選択
実際のロボット工学などの現実世界のアプリケーションに強化学習をより適用可能にするために、私たちは展開に適した方針を選択するための知的な評価手法、アクティブオフラインポリシー選択(A-OPS)を提案しますA-OPSでは、事前に録画されたデータセットを活用し、限定的な実環境との相互作用を許可することで、選択の品質を向上させます
.png)
キルギスタンからキングスクロスまで:コードを作り上げるスターベーカー
私の一日はさまざまですそれは本当にプロジェクトのどのフェーズにいるかによりますたとえば、製品に機能を追加したいとします私の仕事は、最適な解決策を設計したり、チームと協力して最適な解決策を見つけたりすることから、新しい機能を本番環境に展開したり、メンテナンスを行ったりすることまで様々です途中で、変更内容を利害関係者に伝えたり、ドキュメントを作成したり、コードを書いたり、ソリューションをテストしたり、分析ダッシュボードを作成したり、古いコードを整理したり、バグを修正したりします

LEGOのコンテストからDeepMindのロボット研究室まで
DeepMindに入りたいなら、躊躇せずに進んでください応募し、面接を受けて、ただ試してみてください最初に受からなくても、それは諦めることではありません私もDeepMindに受け入れられるとは思っていませんでしたし、受け入れられたときは間違いではないかと思いました誰もが自信を持てないものです私は決して自分が一番頭のいい人間ではないと感じることがよくありますしかし、そうした感情にもかかわらず、私はここに属していて、こうした場所で働く価値があると学びましたそして、私にとってその旅は、ただ試してみることから始まりました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.