Learn more about Search Results HTML - Page 237

- You may be interested
- Pythonアプリケーション | 速度と効率の向...
- 「SQLで移動平均と累積合計をマスターする...
- 人工知能の台頭に備えるために、高校生を...
- MLOps(エムエルオプス):ドリフトの監視...
- MLモデルのトレーニングパイプラインの構...
- 「明日のAIによるサイバーセキュリティの...
- NVIDIAとHexagonが、産業のデジタル化を加...
- ニューラル輝度場の不確実性をどのように...
- 『データサイエンスをマスターするための5...
- お客様との関係を革新する:チャットとRea...
- メタAIは、リアルタイムに高品質の再照明...
- このAI論文は、ChatGPTを基にしたテキスト...
- 「生成AIはその環境への足跡に値するのか?」
- 「脳と体をモニターするイヤホン」
- 「GPTモデルのTransformerアーキテクチャー」
PlotlyとPandas:効果的なデータ可視化のための力の結集
昔々、私たちの多くがこの問題にぶつかったことがありましたもし才能がないか、前もってデザインのコースを受講したことがなければ、視覚的なものを作ることはかなり困難で時間がかかるかもしれません…

「ChatGPTコードインタプリタは、すべてのプラスユーザーに利用可能です」
データ分析のためのChatGPTコードインタープリターの力を解き放ちましょうVoAGIの収益統計を革新し、データアナリストの能力を向上させましょう

ゼロからdbtモデルを設計する方法
「dbtの究極ガイドを調査していた時、実際にモデルをゼロから構築するための資料がほとんどないことに驚きました具体的な手順はツールの中ですべてカバーされていますが、...」

TransformersとRay Tuneを使用したハイパーパラメータの検索
Anyscale チームの Richard Liaw によるゲストブログ投稿 最先端の研究実装や数千ものトレーニング済みモデルへの簡単なアクセスが可能な Hugging Face transformers ライブラリは、自然言語処理の成功と成長において重要な存在となっています。 良いパフォーマンスを達成するために、ほとんどのユーザーはパラメータのチューニングを行う必要があります。しかし、ほとんどの人はハイパーパラメータのチューニングを無視するか、小さな探索空間で簡素なグリッドサーチを行うことを選択します。 しかし、簡単な実験でも高度なチューニング手法の利点を示すことができます。以下は、Hugging Face transformers の BERT モデルを RTE データセットで実行した最近の実験結果です。PBT のような遺伝的最適化手法は、標準的なハイパーパラメータ最適化手法と比較して大幅なパフォーマンス向上を提供できます。 アルゴリズム 最高の検証精度 最高のテスト精度 合計…

fairseqのwmt19翻訳システムをtransformersに移植する
Stas Bekmanさんによるゲストブログ記事 この記事は、fairseq wmt19翻訳システムがtransformersに移植された方法をドキュメント化する試みです。 私は興味深いプロジェクトを探していて、Sam Shleiferさんが高品質の翻訳者の移植に取り組んでみることを提案してくれました。 私はFacebook FAIRのWMT19ニュース翻訳タスクの提出に関する短い論文を読み、オリジナルのシステムを試してみることにしました。 最初はこの複雑なプロジェクトにどう取り組むか分からず、Samさんがそれを小さなタスクに分解するのを手伝ってくれました。これが非常に助けになりました。 私は、両方の言語を話すため、移植中に事前学習済みのen-ru / ru-enモデルを使用することを選びました。ドイツ語は話せないので、de-en / en-deのペアで作業するのははるかに難しくなります。移植プロセスの高度な段階で出力を読んで意味を理解することで翻訳の品質を評価できることは、多くの時間を節約することができました。 また、最初の移植をen-ru / ru-enモデルで行ったため、de-en / en-deモデルが統合されたボキャブラリを使用していることに全く気づいていませんでした。したがって、2つの異なるサイズのボキャブラリをサポートするより複雑な作業を行った後、統合されたボキャブラリを動作させるのは簡単でした。 手抜きしましょう 最初のステップは、もちろん手抜きです。大きな努力をするよりも小さな努力をする方が良いです。したがって、fairseqへのプロキシとして機能し、transformersのAPIをエミュレートする数行のコードで短いノートブックを作成しました。 もし基本的な翻訳以外のことが必要なければ、これで十分でした。しかし、もちろん、完全な移植を行いたかったので、この小さな勝利の後、より困難な作業に移りました。 準備 この記事では、~/portingの下で作業していると仮定し、したがってこのディレクトリを作成します:…
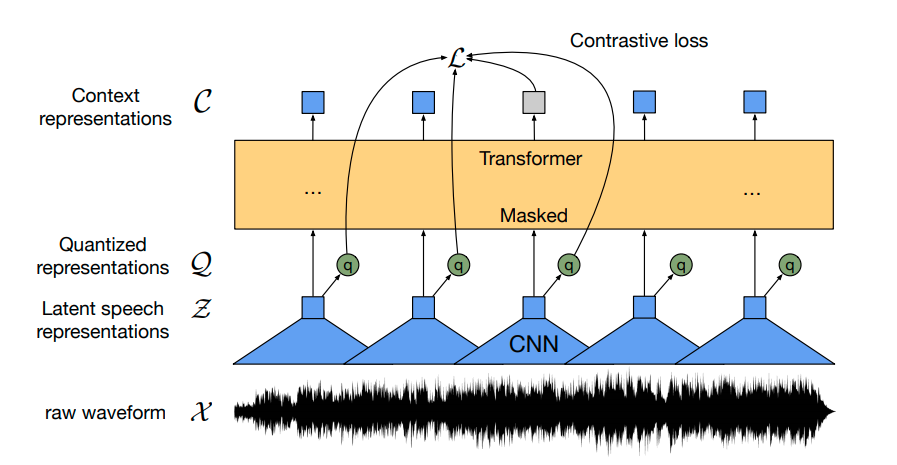
Hugging Faceを使用してWav2Vec2を英語音声認識のために微調整する
Wav2Vec2は、自動音声認識(ASR)のための事前学習済みモデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。 Wav2Vec2は、革新的な対比的事前学習目標を使用して、50,000時間以上の未ラベル音声から強力な音声表現を学習します。BERTのマスクされた言語モデリングと同様に、モデルはトランスフォーマーネットワークに渡す前に特徴ベクトルをランダムにマスクすることで、文脈化された音声表現を学習します。 初めて、事前学習に続いてわずかなラベル付き音声データで微調整することで、最先端のASRシステムと競合する結果が得られることが示されました。Wav2Vec2は、わずか10分のラベル付きデータを使用しても、LibriSpeechのクリーンテストセットで5%未満の単語エラーレート(WER)を実現します – 論文の表9を参照してください。 このノートブックでは、Wav2Vec2の事前学習チェックポイントをどの英語のASRデータセットでも微調整する方法について詳しく説明します。このノートブックでは、言語モデルを使用せずにWav2Vec2を微調整します。言語モデルを使用しないWav2Vec2は、エンドツーエンドのASRシステムとして非常にシンプルであり、スタンドアロンのWav2Vec2音響モデルでも印象的な結果が得られることが示されています。デモンストレーションの目的で、わずか5時間のトレーニングデータしか含まれていないTimitデータセットで「base」サイズの事前学習チェックポイントを微調整します。 Wav2Vec2は、コネクショニスト時系列分類(CTC)を使用して微調整されます。CTCは、シーケンス対シーケンスの問題に対してニューラルネットワークを訓練するために使用されるアルゴリズムであり、主に自動音声認識および筆記認識に使用されます。 Awni Hannunによる非常にわかりやすいブログ記事Sequence Modeling with CTC(2017)を読むことを強くお勧めします。 始める前に、datasetsとtransformersを最新バージョンからインストールすることを強くお勧めします。また、オーディオファイルを読み込むためにsoundfileパッケージと、単語エラーレート(WER)メトリックを使用して微調整モデルを評価するためにjiwerが必要です1 {}^1 1 。 !pip install datasets>=1.18.3 !pip install…
分散トレーニング:🤗 TransformersとAmazon SageMakerを使用して、要約のためにBART/T5をトレーニングする
見逃した場合: 3月25日にAmazon SageMakerとのコラボレーションを発表しました。これにより、最新の機械学習モデルを簡単に作成し、先進的なNLP機能をより速く提供できるようになりました。 SageMakerチームと協力して、🤗 Transformers最適化のDeep Learning Containersを構築しました。AWSの皆さん、ありがとうございます!🤗 🚀 SageMaker Python SDKの新しいHuggingFaceエスティメーターを使用すると、1行のコードでトレーニングを開始できます。 発表のブログ投稿では、統合に関するすべての情報、”はじめに”の例、ドキュメント、例、および機能へのリンクが提供されています。 以下に再掲します: 🤗 Transformers ドキュメント: Amazon SageMaker サンプルノートブック Hugging Face用のAmazon SageMakerドキュメント Hugging Face用のPython…
🤗 Transformersを使用して、低リソースASRのためにXLSR-Wav2Vec2を微調整する
新着(11/2021):このブログ投稿は、XLSRの後継であるXLS-Rを紹介するように更新されました。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、Alex Conneauによって2020年9月にリリースされました。Wav2Vec2の優れた性能が、ASRの最も人気のある英語データセットであるLibriSpeechで示されるとすぐに、Facebook AIはWav2Vec2の多言語版であるXLSRを発表しました。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習できる能力を指します。 XLSRの後継であるXLS-R(「音声用のXLM-R」という意味)は、Arun Babu、Changhan Wang、Andros Tjandraなどによって2021年11月にリリースされました。XLS-Rは、自己教師付き事前学習のために128の言語で約500,000時間のオーディオデータを使用し、パラメータ数が30億から200億までのサイズで提供されています。事前学習済みのチェックポイントは、🤗 Hubで見つけることができます: Wav2Vec2-XLS-R-300M Wav2Vec2-XLS-R-1B Wav2Vec2-XLS-R-2B BERTのマスクされた言語モデリング目的と同様に、XLS-Rは自己教師付き事前学習中に特徴ベクトルをランダムにマスクしてからトランスフォーマーネットワークに渡すことで、文脈化された音声表現を学習します(左側の図)。 ファインチューニングでは、事前学習済みネットワークの上に単一の線形層が追加され、音声認識、音声翻訳、音声分類などのラベル付きデータでモデルをトレーニングします(右側の図)。 XLS-Rは、公式論文のTable 3-6、Table 7-10、Table 11-12で、以前の最先端の結果に比べて音声認識、音声翻訳、話者/言語識別の両方で印象的な改善を示しています。 セットアップ このブログでは、XLS-R(具体的には事前学習済みチェックポイントWav2Vec2-XLS-R-300M)をASRのためにファインチューニングする方法について詳しく説明します。 デモンストレーションの目的で、我々は低リソースなASRデータセットのCommon Voiceでモデルをファインチューニングします。このデータセットには検証済みのトレーニングデータが約4時間しか含まれていません。…
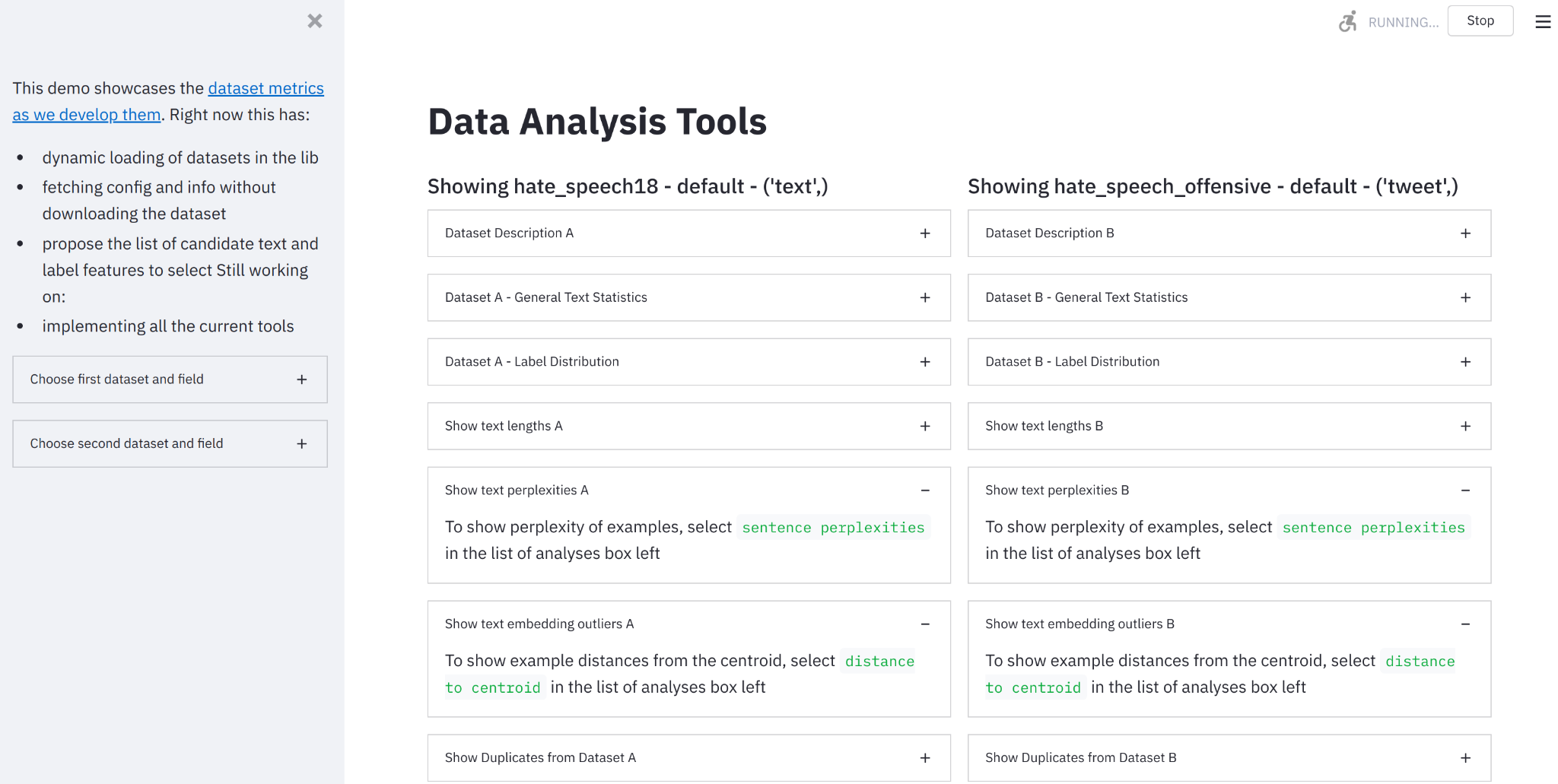
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…
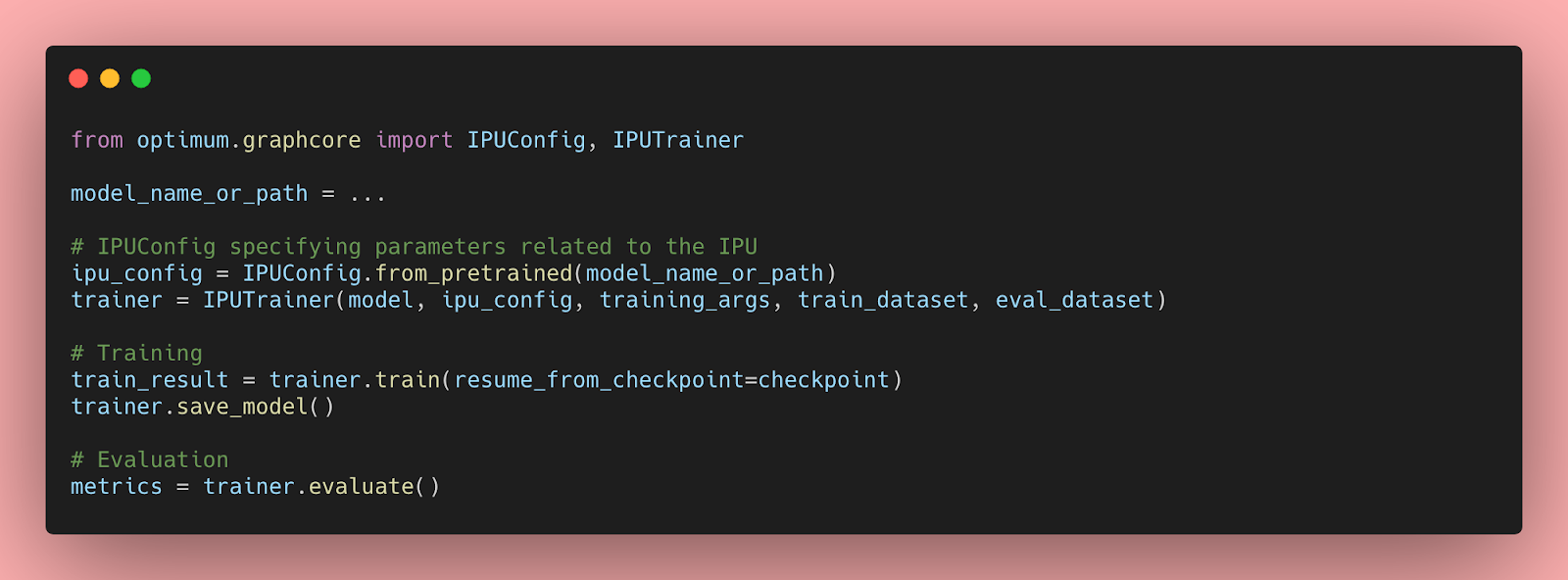
IPUを使用したHugging Face Transformersの始め方と最適化について
Transformerモデルは、自然言語処理、音声処理、コンピュータビジョンなど、さまざまな機械学習タスクで非常に効率的であることが証明されています。しかし、これらの大規模なモデルの予測速度は、会話型アプリケーションや検索などのレイテンシに敏感なユースケースでは実用的ではありません。さらに、実世界でのパフォーマンスを最適化するには、多くの企業や組織には到底手の届かない時間、労力、スキルが必要です。 幸いなことに、Hugging FaceはOptimumというオープンソースのライブラリを導入しました。このライブラリを使用すると、さまざまなハードウェアプラットフォーム上でTransformerモデルの予測レイテンシを大幅に削減することが容易になります。このブログ記事では、AIワークロードに最適化されたGraphcore Intelligence Processing Unit(IPU)向けにTransformerモデルを高速化する方法を学びます。 OptimumがGraphcore IPUと出会う GraphcoreとHugging Faceのパートナーシップにより、最初のIPUに最適化されたモデルとしてBERTが導入されました。今後数ヶ月にわたり、ビジョン、音声、翻訳、テキスト生成など、さまざまなアプリケーションに対応したIPUに最適化されたモデルをさらに導入していく予定です。 Graphcoreのエンジニアは、Hugging Faceのトランスフォーマーを使用してBERTをIPUシステムに実装し、最新のモデルを簡単にトレーニング、微調整、高速化できるように最適化しました。 IPUとOptimumの始め方 OptimumとIPUの使用を始めるために、BERTを例にして説明します。 このガイドでは、Graphcoreのクラウドベースの機械学習プラットフォームであるGraphcloudのIPU-POD16システムを使用し、Getting Started with Graphcloud のPyTorchのセットアップ手順に従います。 GraphcloudサーバーにはすでにPoplar SDKがインストールされています。別のセットアップを使用している場合は、PyTorch for the IPU:…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.