Learn more about Search Results A - Page 236

- You may be interested
- 「Apache SeaTunnel、Milvus、およびOpenA...
- ドメイン固有アプリケーションのためのLLM...
- 「PUGに会ってください:メタAIによるアン...
- ZeROを使用して、DeepSpeedとFairScaleを...
- 「このAI研究は、グラフ上の大規模言語モ...
- 「研究者がWindows Helloの実装に脆弱性を...
- モデルレジストリとAmazon SageMakerモデ...
- アジャイルを用いたデータサイエンスプロ...
- 「NVIDIAがゲームチェンジャーとマーケッ...
- 「物理学と流体力学に応用されたディープ...
- 「ニューロンの多様性を受け入れる:AIの...
- 「OpenAI WhisperとHugging Chat APIを使...
- Google DeepMindの研究者は、機能を維持し...
- バイトダンスとキング・アブドゥッラー科...
- 「初心者向けの14のエキサイティングなPyt...

「ハブスポット、ハブスポットAIおよび新しいセールスハブをINBOUND 2023で発表」
「買い物と売り物の風景は、絶えず変化する経済と生成AIの台頭の影響を受け、根本的な変革を遂げています企業は前例のない課題に直面しており、適応する圧力はこれまでにないほど大きくなっていますこの変化の結果として、HubSpotはHubSpot AIを発表しました新たな...」
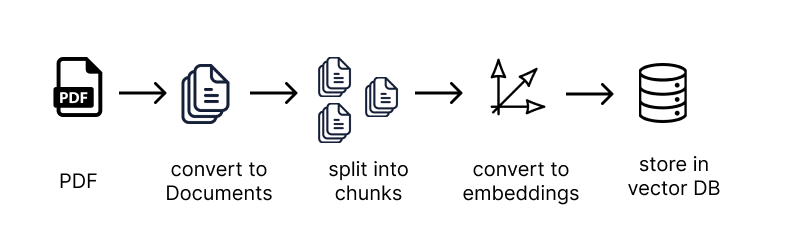
「ワイルドワイルドRAG…(パート1)」
「RAG(Retrieval-Augmented Generation)は、外部の知識源を取り込むことで言語モデルによって生成された応答の品質を向上させるAIフレームワークですこれにより、…のギャップを埋める役割を果たします」

「マイクロソフトリサーチがAIコンパイラを1つではなく、2つでもなく、4つも新たに紹介」
コンパイラは、生成的AIの時代に復活していますAIの文脈では、コンパイラはニューラルネットワークのアーキテクチャを特定の実行可能コードに変換する責任があります...

「AIは本当に低品質な画像から顔の詳細を復元できるのでしょうか? DAEFRとは何か:品質向上のためのデュアルブランチフレームワークに出会う」
画像処理の分野では、劣化した顔写真から高精細な情報を回復することは依然として困難な課題です。これらの画像が受ける多くの劣化により、必要な情報の喪失が頻繁に起こるため、これらの活動は本質的に難しいものです。この問題は、低品質の写真と高品質の写真の間の品質の違いを浮き彫りにします。続く問題は、低品質のドメインの固有の特性を利用して、顔の修復プロセスをより良く理解し改善することが可能かどうかということです。 最近のアプローチでは、この問題に対処するためにコードブックの事前知識、オートエンコーダー、高品質の特徴セットが取り入れられています。しかし、これらの手法には依然として重大な弱点があります。それらは通常、高品質のデータのみで訓練された単一のエンコーダーに依存し、低品質の画像が持つ特殊な複雑さを無視します。革新的であるかもしれませんが、このような手法は意図せずにドメインのギャップを広げ、低品質のデータの微妙な側面を見逃す可能性があります。 最近、これらの問題に取り組むために新しい論文が紹介されました。このアプローチでは、ぼやけたまたははっきりしない画像から重要な詳細を引き出し、それらをより明確な画像の詳細と組み合わせて顔画像の修復を改善するための「低品質」のブランチを追加しています。 彼らの研究の特徴は次の通りです: 1. 低品質の画像のユニークな特徴を捉えるための特別なツールを追加し、明確な画像とはっきりしない画像の間のギャップを埋めます。 2. 彼らの手法は、低品質と高品質の画像の詳細を混ぜ合わせます。この混合により、画像の修復における一般的な問題を克服し、より明確で優れた結果を生み出します。 3. 彼らはぼやけたまたははっきりしない顔画像を処理するためのDAEFRという技術を導入しました。 具体的には、彼らの手法は次の重要なステップから構成されます: 離散コードブック学習ステージ:HQおよびLQ画像のためのコードブックを確立します。ベクトル量子化を使用して、ドメイン固有の情報をキャプチャするための自己再構築のためのオートエンコーダーを訓練します。このステージでは、HQおよびLQドメインのためのエンコーダーとコードブックが生成されます。 関連付けステージ:CLIPモデルからのインスピレーションを得て、HQおよびLQドメインの特徴を関連付けます。ドメイン固有のエンコーダーからの特徴はパッチにフラット化され、類似性行列を構成します。この行列は、空間的な位置と特徴レベルの観点でこれらのパッチの近さを測定します。目標は、ドメインのギャップを最小化し、両方のドメインからの情報を統合した関連するエンコーダーを生成することです。 特徴融合とコード予測ステージ:関連するエンコーダーを取得した後、LQ画像は両方のエンコーダーを使用してエンコードされます。マルチヘッドのクロスアテンションモジュールは、これらのエンコーダーからの特徴を統合し、HQおよびLQドメインの情報を包括する融合された特徴を生成します。その後、トランスフォーマーはHQコードブックの関連するコード要素を予測し、それをデコーダーが復元されたHQ画像を生成するために使用します。 著者たちは、自身の手法を一連の実験を通じて評価しました。彼らはPyTorchフレームワークを使用して、70,000枚の高品質の顔画像データセットFFHQでモデルを訓練しました。これらの画像は、トレーニング目的のためにリサイズされ、合成的に劣化させられました。テストには、CelebA-Testと3つの実世界のデータセットを選びました。評価メトリックは、グラウンドトゥルースがあるデータセット用にPSNRとSSIM、グラウンドトゥルースがない実世界のデータセット用にFIDとNIQEを使用しました。最先端の手法と比較して、彼らのDAEFRモデルは実世界のデータセットで優れた知覚品質を示し、合成データセットでは競争力のあるパフォーマンスを発揮しました。また、削除研究では、2つのエンコーダーを使用することが最適であり、提案されたマルチヘッドのクロスアテンションモジュールが特徴融合を改善していることが明らかになり、劣化した画像の修復における手法の有効性を強調しています。 結論として、本記事では、特に低品質の顔写真の画像修復の課題に取り組むために公開された新しい論文を紹介しました。研究者たちは、DAEFRという新しい手法を紹介し、高品質および低品質の画像特徴を活用してより明確で洗練された修復画像を生成します。この手法は、高品質の画像と低品質の画像のためにそれぞれ1つのエンコーダーシステムを使用することにより、既存の2つのドメインの間のギャップを埋めることができます。解決策は厳密に評価され、以前の手法に比べて顕著な改善が示されました。この論文の所見は、DAEFRが画像処理の分野を大幅に推進し、より正確な顔画像の修復を可能にする可能性を強調しています。

「2023年のトップAI画像アップスケーラーと拡大器」
優れた方法で画像を強化およびリサイズするには、AI画像およびアップスケーラーサービスを使用します。研究者は、毎年1兆枚以上の写真が撮影されていると推定しています。デジタル写真は皆の生活を豊かにしますが、ジャーナリズムやソーシャルメディアなどの特定の分野では、写真のアップスケーラープログラムに依存しています。 高品質の画像を使用することは、人々の注意を引く確実な方法です。しかし、ほとんどのオンライン写真はより焦点を絞り、品質を向上させることができます。人工知能は、過去数年間で画像のアップスケール技術を大幅に向上させ、低解像度の写真を高品質なプロフェッショナル画像に変換することをはるかに容易にしました。 最高のAIパワードの写真エンハンサーおよびアップスケーラーのいくつかは次のとおりです: AI Image Enlarger AI Image Enlargerを使用すると、画像の品質を低下させることなく、自動的に低解像度の画像を拡大および強化することができます。ファイルサイズの上限は5 MBで、JPGまたはPNG形式での完全な画像解像度は1200×1200です。AI Image Enlargerツールボックスは、高速かつ高度なAI技術を使用して画像解像度を向上させ、品質を低下させることなく画像を大量にアップスケールします。 VanceAI Image Upscaler もう1つの優れたAI画像エンハンサー、VanceAIは、非常に便利ないくつかの機能を備えています。まず、8倍のAI画像アップスケーラーを使用して低解像度の写真をより良く見せることができます。このアプリには、アニメの画像を最大16倍に増やす人工知能アニメアップスケーラーもあります。VanceAI Image Upscalerには、いくつかの基本的なセキュリティ機能も備わっています。たとえば、24時間後に処理された画像は永久に削除されます。他の推奨プログラムと同様に、このプログラムも画像の拡大プロセスを簡素化しています。手順は、画像をアップロードし、適切なAIモデルを選択し、所望のアップスケーリングファクターを選択することから始まります。 Remini Reminiは、ディープラーニングとAIによって駆動されるウェブベースの写真編集プログラムです。写真に写る顔、色、およびその他の要素を認識する高度なアルゴリズムを使用して、外観を改善するために必要な調整を行います。Reminiを使用すると、クロッピング、リサイズ、明るさやコントラストの調整などの基本的なタスクも簡単に行うことができます。ただし、Reminiから最新の写真を保持する場合は、サブスクリプションが必要です。 Let’s Enhance Let’s Enhanceは、低解像度の画像を4K解像度まで引き上げるオンライン人工知能写真アップスケーラーです。プログラムのAI技術のおかげで、色が向上し、欠落しているテクスチャやディテールが回復し、圧縮がなくなります。Let’s…

この人工知能(AI)の研究では、SAMを医療用2D画像に適用するための最も包括的な研究である、SAM-Med2Dを提案しています
医用画像セグメンテーションは、異なる組織、臓器、または関心領域を認識して分離することにより、医用画像の研究に不可欠です。正確なセグメンテーションを使用することで、診断と治療をより正確に行うため、臨床医は病変領域を特定し、正確に特定するのに役立ちます。また、医用画像の定量的および質的な解析により、さまざまな組織や臓器の形態、構造、機能に関する詳細な洞察を提供し、疾患の研究を可能にします。医用画像の特異性(多岐にわたるモダリティ、複雑な組織および臓器の構造、注釈付きデータの不在など)のため、既存のアプローチのほとんどは特定のモダリティ、臓器、または病理学に制約があります。 この制約のため、アルゴリズムはさまざまな臨床的な文脈で一般化および修正するのが困難です。最近、大規模なモデルに向けた取り組みがAIコミュニティで注目を集めています。ChatGPT2、ERNIE Bot 3、DINO、SegGPT、SAMなどの一般的なAIモデルの開発により、さまざまなタスクに単一のモデルを使用することが可能になりました。SAMを使用すると、最新の大規模ビジョンモデルであるSAMを使用して、ユーザーはインタラクティブなクリック、境界ボックスの描画、口頭の手がかりを使用して、特定の関心領域のマスクを作成できます。そのゼロショットおよび少数ショットの能力には、さまざまな分野で自然な写真に対して大きな注目が集まっています。 SAMのゼロショット能力に関しては、医用画像の文脈での適用も研究が行われています。しかし、SAMはマルチモーダルおよびマルチオブジェクトの医用データセットに対して一般化することが困難であり、データセット間で変動するセグメンテーションのパフォーマンスを引き起こします。これは、自然な画像と医用画像の間に相当なドメインの隔たりがあるためです。その原因は、データの収集に使用される方法に関連しています。特定の臨床目的のため、医用画像は特定のプロトコルとスキャナを使用して取得され、さまざまなモダリティ(電子、レーザー、X線、超音波、核物理学、磁気共鳴)で表示されます。そのため、これらの画像はさまざまな物理学的特徴とエネルギー源に依存しているため、実際の画像から大きく逸脱しています。 図1に示すように、自然な画像と医用画像はピクセル強度、色、テクスチャ、およびその他の分布特性において大きく異なります。SAMは自然な写真のみで訓練されているため、医療画像に関する専門的な情報がさらに必要です。したがって、医療分野に直接適用することはできません。医療情報をSAMに提供することは、注釈付けのコストの高さと一貫性のない注釈付けの質のために困難です。医療データの準備には専門的な知識が必要であり、このデータの品質は施設や臨床試験によって大きく異なります。これらの困難により、医療画像および自然な画像の量は大きく異なります。 図1の棒グラフは、公開されている自然な画像データセットと医用画像データセットのデータボリュームを比較しています。例えば、医療領域で最も大規模なセグメンテーションデータセットであるTotalsegmentorは、Open Image v6およびSA-1Bと比較しても大きなギャップがあります。本研究では、四川大学と上海AI研究所の研究者が提案した、医療2D画像へのSAMの適用に関する最も包括的な研究であるSAM-Med2Dを紹介します。

このAI研究は、「ComCLIP:組成画像とテキストの整列におけるトレーニングフリーな方法」を公開しています
組成画像とテキストのマッチングは、ビジョン言語研究のダイナミックなフィールドにおいて、大きな課題を提起しています。このタスクには、画像とテキストの記述の中で主語、述語/動詞、および目的語の概念を正確に整列させる必要があります。この課題は、画像検索、コンテンツ理解など、さまざまなアプリケーションに重要な影響を与えます。CLIPなどの事前学習済みのビジョン言語モデルによっても大きな進展がありましたが、既存のシステムではしばしば実現が困難な組成パフォーマンスの向上がますます求められています。この課題の核心は、広範なトレーニングプロセス中にこれらのモデルに根付いてしまうバイアスと不正確な相関です。この文脈で、研究者はこの核心の問題に取り組み、ComCLIPという画期的な解決策を紹介しています。 CLIPが大きな進歩を遂げた画像テキストマッチングの現在の状況では、従来のアプローチでは画像とテキストを統一体として扱っています。このアプローチは多くの場合効果的に機能しますが、細粒度な組成理解を必要とするタスクでは改善が必要な場合があります。ここで、ComCLIPは従来の常識から大胆に逸脱します。画像とテキストを一塊のまま扱うのではなく、ComCLIPは入力画像をその構成要素である主語、目的語、およびアクションのサブイメージに分解します。これはセグメンテーションプロセスを制御する特定のエンコーディングルールに従って行われます。このような方法で画像を分解することにより、ComCLIPはこれらの異なるコンポーネントが果たす役割の深い理解を得ます。さらに、ComCLIPは動的な評価戦略を採用し、正確な組成マッチングを達成するためにこれらのさまざまなコンポーネントの重要性を評価します。この革新的なアプローチにより、事前学習済みモデルから引き継がれるバイアスと不正確な相関の影響を軽減する可能性があり、追加のトレーニングや微調整は必要ありません。 ComCLIPの方法論には、組成画像とテキストのマッチングの課題に対処するために調和するいくつかの重要な要素が含まれています。まず、元の画像は密なキャプションモジュールを使用して処理され、シーン内のオブジェクトに焦点を当てた密な画像キャプションが生成されます。同時に、入力テキスト文は解析プロセスを経ます。解析中に、エンティティの単語が抽出され、主語-述語-目的語の形式で緻密に整理され、ビジュアルコンテンツで見つかる構造を反映します。ComCLIPが行うマジックは、これらの密な画像キャプションと抽出されたエンティティの単語との間に堅牢な整列を確立することです。この整列は、エンティティの単語を密なキャプションに基づいて画像内の対応する領域に効果的にマッピングする橋となります。 ComCLIPの中での主要なイノベーションの1つは、述語のサブイメージの作成です。これらのサブイメージは、テキストの入力で説明されるアクションまたは関係を反映するように、関連するオブジェクトと主語のサブイメージを緻密に組み合わせて作成されます。結果として得られる述語のサブイメージは、モデルの理解をさらに豊かにするアクションまたは関係を視覚的に表現します。元の文と画像、およびそれぞれの解析された単語とサブイメージとともに、ComCLIPはCLIPテキストとビジョンエンコーダーを使用します。これらのエンコーダーは、テキストとビジュアルの入力を埋め込みに変換し、各コンポーネントの本質を効果的に捉えます。ComCLIPは、各画像埋め込みと対応する単語埋め込み間のコサイン類似度スコアを計算し、これらの埋め込みの関連性と重要性を評価します。これらのスコアは、softmax層によって処理され、モデルが異なるコンポーネントの重要性を正確に評価できるようになります。最後に、ComCLIPはこれらの重み付けされた埋め込みを組み合わせて最終的な画像埋め込みを取得します-入力全体の本質を包括した表現です。 まとめると、この研究は、ビジョン言語研究内での組成的な画像とテキストのマッチングの重要な課題を明らかにし、先駆的な解決策であるComCLIPを紹介しています。ComCLIPは因果推論と構造的因果モデルの原則にしっかりと基づいた革新的なアプローチであり、組成的な理解に取り組む方法を革新します。ComCLIPは、ビジュアル入力を細かく分割されたサブイメージに分解し、動的なエンティティレベルのマッチングを行うことにより、画像とテキストの組成要素を理解し、操作する能力を大幅に向上させることを約束します。CLIPやSLIPなどの既存の手法はその価値を示していますが、ComCLIPは、分野内の基本的な問題に対処し、研究と応用の新たな可能性を開拓する有望な進歩として際立っています。

このAI論文は、大規模な言語モデルにおける長期的な会話の一貫性を向上させるための再帰的なメモリ生成手法を提案しています
チャットボットや他のオープンドメインのコミュニケーションシステムは、近年の関心と研究の急増を見ています。長期的な議論の設定は、前回の会話の重要なポイントを知り、覚える必要があるため、困難です。 ChatGPTやGPT-4などの大規模言語モデル(LLM)は、最近の自然言語タスクで励みになる結果を示しています。その結果、オープンドメイン/タスクチャットボットは、LLMの能力をプロンプティングに利用して作成されます。しかし、長時間の議論では、ChatGPTでも文脈を見失い、一貫性のない回答を提供することがあります。 中国科学院とシドニー大学の研究者は、ラベル付きデータや追加のツールなしでLLMを長期的な会話に効果的に使用できるかどうかを調査しています。研究者は、メモリとして再帰的な要約を構築するためにLLMを使用し、進行中の会話から重要な情報を保存します。これは、メモリ拡張アプローチからのインスピレーションを得ています。実際の使用では、LLMにはまず簡単な背景を与え、それを要約するように求めます。次に、以前の文と後続の文を組み合わせて新しい要約/メモリを生成します。最後に、LLMに最新の情報に基づいて決定するように指示します。 提案されたスキーマは、非常に長いコンテキスト(対話セッション)をモデル化するために現在のLLMを可能にするための実現可能なソリューションとして機能する可能性があります。設定の最大長さのコスト増加や長期的な論述のモデリングは必要ありません。 提案されたスキーマの有用性は、簡単に使用できるLLM API ChatGPTとtext-davinci-003を使用して公開の長期データセットで実験的にデモンストレーションされています。さらに、研究は、単一のラベル付きサンプルを使用することで提案された戦略のパフォーマンスを大幅に向上させることを示しています。 研究者は、メモリ管理と回答生成のタスクを任された任意の大規模言語モデルについて調査しています。前者は進行中の会話の重要な詳細を反復的に要約する役割を担い、後者はメモリを組み込んで適切な回答を生成します。 この研究では、提案された手法の効果を判断するために自動的な指標のみを使用していますが、これはオープンドメインのチャットボットに最適ではありません。実際のアプリケーションでは、巨大なモデルを呼び出すコストを無視することはできません。これは彼らの解決策には考慮されていません。 将来、研究者は、彼らのアプローチがストーリープロダクションを含む他の長期コンテキストのモデリングにおいてどのように効果的かをテストする予定です。また、高価なオンラインAPIではなく、ローカルに監督された微調整されたLLMを使用して、彼らの手法の要約能力を向上させる予定です。

「フラミンゴとDALL-Eはお互いを理解しているのか?イメージキャプションとテキストから画像生成モデルの相互共生を探る」
テキストとビジュアルのコンピュータ理解を向上させるマルチモーダル研究は、最近大きな進歩を遂げています。DALL-EやStable Diffusion(SD)などのテキストからイメージを生成するモデルや、FlamingoやBLIPのようなイメージからテキストを生成するモデルは、現実の状況からの複雑な言語的記述を高精度のビジュアルに変換することができます。しかし、テキストからイメージを生成するモデルと画像キャプション生成モデルの間には近接性がありながらも、独立して研究されることが多く、これらのモデルの相互作用は探求される必要があります。テキストからイメージを生成するモデルと画像からテキストを生成するモデルがお互いを理解できるかどうかという問題は興味深いものです。 この問題に取り組むために、特定の画像に対してテキストの説明を生成するためにBLIPという画像からテキストのモデルを使用します。このテキストの説明は、SDというテキストからイメージを生成するモデルに供給され、新しい画像が作成されます。彼らは、作成された画像が元の画像に似ている場合、BLIPとSDがコミュニケーションできると主張しています。共有された理解によって、各モデルの基本的なアイデアを理解する能力が向上し、キャプションの作成と画像合成がより良くなる可能性があります。このコンセプトは図1に示されており、上のキャプションは元の画像のより正確な再構成を導き、下のキャプションよりも入力画像をよりよく表現しています。 https://arxiv.org/abs/2212.12249 LMU Munich、Siemens AG、およびUniversity of Oxfordの研究者は、DALL-EがFlamingoが特定の画像に対して生成する説明を使用して新しい画像を合成する再構成タスクを開発しました。この仮定をテストするために、テキスト-イメージ-テキストとイメージ-テキスト-イメージの2つの再構成タスクを作成します(図1を参照)。最初の再構成タスクでは、事前学習済みのCLIPイメージエンコーダで抽出された画像の特徴の距離を計算し、再構成された画像と入力画像の意味がどれだけ似ているかを判断します。次に、生成されたテキストの品質を人間によって注釈付けされたキャプションと比較します。彼らの研究は、生成されたテキストの品質が再構成のパフォーマンスにどのように影響するかを示しています。これにより、彼らの最初の発見が導かれます:生成モデルが元の画像を再構成するための説明は、画像に最も適した説明であるということです。 同様に、SDがテキストの入力から画像を作成し、その作成された画像からBLIPがテキストを作成する逆のタスクを作成します。彼らは、元のテキストを生成した画像がテキストにとって最も優れたイラストであることを発見します。彼らは、再構成プロセス中に入力画像からの情報がテキストの記述に正確に保持されると仮定しています。この意味のある説明は、画像モダリティへの忠実な回復につながります。彼らの研究は、テキストからイメージやイメージからテキストのモデルがお互いとコミュニケーションするのを容易にする独自のフレームワークを示唆しています。 具体的には、彼らのパラダイムでは、生成モデルは再構成損失と人間のラベルからトレーニング信号を受け取ります。1つのモデルは、他のモダリティの特定の画像またはテキストの入力の表現を最初に作成し、異なるモデルはこの表現を入力モダリティに戻します。再構成コンポーネントは、初期モデルの微調整を指示する正則化損失を作成します。このようにして、彼らは自己および人間の監督を得て、生成がより正確な再構成に結果をもたらす可能性を高めます。たとえば、画像キャプションモデルは、ラベル付きの画像テキストのペアに対応するだけでなく、信頼性のある再構成につながるキャプションを好む必要があります。 エージェント間の通信は彼らの仕事と密接に関連しています。エージェント間の主要な情報交換手段は言語です。しかし、最初のエージェントと2番目のエージェントが猫や犬の定義を同じく持っていることを確信することはできますか?この研究では、最初のエージェントに画像を調査し、それを説明する文を生成するように求めます。テキストを受け取った後、2番目のエージェントはそれに基づいて画像をシミュレーションします。後者の段階は具現化プロセスです。彼らの仮説によれば、通信は効果的である場合、2番目のエージェントの入力画像のシミュレーションが最初のエージェントが受け取った入力画像に近い場合です。本質的には、彼らは人間の主要なコミュニケーション手段である言語の有用性を評価しています。特に、新たに確立された大規模な事前学習済みの画像キャプションモデルと画像生成モデルが彼らの研究で使用されています。さまざまな生成モデルに対して、トレーニングフリーおよび微調整の状況の両方で彼らの提案されたフレームワークの利点が証明されました。特に、トレーニングフリーのパラダイムでは、キャプションと画像の作成が大幅に改善されました。一方、微調整では、両方の生成モデルに対してより良い結果が得られました。 以下は彼らの主な貢献の要点です: • フレームワーク:従来の単独の画像からテキストへの生成モデルとテキストから画像への生成モデルが、簡単に理解できるテキストと画像の表現を介して通信する方法について初めて調査したと彼らは最もよく知っています。一方、同様の研究ではテキストと画像の作成を埋め込み空間を介して暗黙的に統合します。 • 結果:彼らは、テキストから画像へのモデルによって作成された画像の再構成を評価することが、キャプションの品質を判断するのに役立つことを発見しました。元の画像の最も正確な再構成を可能にするキャプションが、その画像に使用すべきキャプションです。同様に、元のテキストの最も正確な再構成を可能にするキャプションが最良のキャプション画像です。 • 改善:彼らの研究に基づいて、テキストから画像へのモデルと画像からテキストへのモデルの両方を改善する包括的なフレームワークを提案しました。テキストから画像へのモデルによって計算された再構成損失は、画像からテキストへのモデルの微調整に正則化として使用され、画像からテキストへのモデルによって計算された再構成損失は、テキストから画像へのモデルの微調整に使用されます。彼らは自身のアプローチの有効性を調査し、確認しました。

自動小売りチェックアウトは、ラベルのない農産物をどのように認識するのか? PseudoAugmentコンピュータビジョンアプローチとの出会い
機械学習とディープラーニングの技術の進歩により、さまざまな次元の自動化が増えています。自動化により、特に小売業において、日常生活の様々なルーチン的な側面での人間の介入の必要性が徐々に減少しています。 これらは、自然資源の追跡や環境の持続可能性にも貢献しています。自動化システムは、在庫管理、需要予測、物流調整の向上により、サプライチェーンを最適化するのに役立ちます。しかし、自動化が困難で複雑な場合もあります。バーコードのない製品の識別はその一例です。 自動精算ステーションで消費者に適切に請求するためには、重さのあるオブジェクトを識別する能力が必要です。このようなシステムは、様々な種類の包装されていない生鮮食品、穀物、その他の商品を識別できなければなりません。一般的に、多くの小売店では、顧客は製品コードを覚え、部門で商品を計量して果物や野菜の種類を識別する必要があります。 この問題を解決するために、Skoltechと他の機関の研究者がスーパーマーケットで重量物を識別する新しい方法を考案しました。研究者たちは、このプロセスを支援するためにコンピュータビジョンを使用しました。このアプローチにより、新しい品種が導入されてもニューラルネットワークのトレーニングを高速化することができます。 研究者たちは、この研究を支援するためにさまざまなタイプの画像を収集しました。収集した画像は、庭園、地元の食料品店、研究室の設定で撮影されました。クラスごとに1000枚の自然画像を撮り、合計で5000枚の自然画像を使用しました。彼らはさらに、多くのオブジェクトがトップビューで表示されたトップビューコンテナ画像のタイプの画像を使用しました。クラスごとに70個のトップビュー画像を使用し、平均して1枚の画像あたり7.1個のオブジェクトが含まれていました。さまざまな画像や背景を組み合わせ、さまざまな変換を適用し、トレーニング画像の数よりも多くのトリミングオブジェクトを生成しました。 研究者たちはまた、画像を増強することで、検出品質の劣化がPseudoAugmentを使用しない場合よりも低くなるようにしました。 研究チームは、以前のプロセスにはいくつかの制限があると述べました。スーパーマーケットには視覚的に似ている果物や野菜が多くあり、新しい種類が頻繁に出現するため、クラシックなコンピュータビジョンシステムは新しい品種が納品されるたびに再トレーニングする必要があります。また、多くのデータを収集して手動でラベル付けする必要があるため、時間がかかります。 このアプローチの正確性とパフォーマンスをチェックするために、研究者は5つの異なる種類の果物を分類し、自然なトレーニング写真の数が50未満の場合、デフォルトのパイプラインの出力は基本的に推測に過ぎなかったことがわかりました。彼らはこのアプローチの利点は、元のトレーニング画像が250以下の場合に見られると強調しました。研究者たちはさらに、このアプローチの正確性を果物の分類問題でテストし、自然なトレーニング画像がない場合でも98.3%の正確性に達することができることを観察しました。
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.