Learn more about Search Results HTML - Page 234

- You may be interested
- 「Kubernetesに対応した無限スケーラブル...
- ソロプレナーズ向けの11の最高のAIツール...
- 機械学習洞察のディレクター【パート4】
- 二党間の法案が提出され、AIのリスクや規...
- 新しいNVIDIA GPUベースのAmazon EC2イン...
- 「衛星画像のための基礎モデル」
- 複数モードモデルとは何ですか?
- 「2023年のトップ10オープンソースデータ...
- 「オンラインプログラムの中で第3位のデー...
- 「統計的検定を用いたデータセットの多重...
- 「Pythonを使用した地理空間データの分析...
- 無料でGoogle Colab上でQLoraを使用してLL...
- ChatHNに会いましょう:ハッカーニュース...
- 「サンフランシスコ大学データサイエンス...
- このフィンランド拠点のAIスタートアップ...

Agents.jsをご紹介します:JavaScriptを使用して、あなたのLLMにツールを提供します
最近、私たちはhuggingface.jsでAgents.jsに取り組んでいます。これはJavaScriptからLLMsに対するツールアクセスを提供するための新しいライブラリで、ブラウザまたはサーバーのどちらでも使用できます。デフォルトでいくつかのマルチモーダルツールが付属しており、独自のツールや言語モデルで簡単に拡張することができます。 インストール 始めるのは非常に簡単です。次のコマンドでnpmからライブラリを取得できます: npm install @huggingface/agents 使用方法 このライブラリはHfAgentオブジェクトを公開しており、これがライブラリへのエントリーポイントです。次のようにインスタンス化することができます: import { HfAgent } from "@huggingface/agents"; const HF_ACCESS_TOKEN = "hf_..."; // https://huggingface.co/settings/tokensでトークンを取得してください const agent = new…

「2023年の機械学習のアンラーニング:現在の状況と将来の方向性」
「夜中に目が覚めたまま、脳が何度も再生するほど恥ずかしい記憶の一部を忘れたいと思ったことはありますか?特定の記憶を心に残すことは…」

2023年にフォローすべきAI YouTuberトップ15選
人工知能は現在、さまざまな分野で指数関数的な成長を遂げています。その拡大により、この領域は学び、マスターするための数々の機会を持つ志望者にとって、多くの可能性を提供しています。その中で、いくつかのAI愛好家が登場し、それぞれの専門分野で優れた成績を収め、教えることへの情熱によって駆り立てられています。彼らは他の学習者の旅をより簡単にすることを目指しています。はい、YouTuberはYouTubeで無料で情報提供するための教育コンテンツを作成しています。ここでは、人工知能、深層学習、および機械学習に関する高く評価されたさまざまなビデオを持つ15人のAI YouTuberを紹介します。 3Blue1Brown 登録日: 2015年3月4日 登録者数: 5.33M ビデオ数: 132 ウェブサイト: https://www.3blue1brown.com リンク: https://www.YouTube.com/@3blue1brown Grant Sandersonは、このチャンネルを所有するAI YouTuberです。彼はアニメーションを使用して複雑な数学や機械学習のコンセプトを説明しています。彼の最も人気のあるビデオはフーリエ級数についてです。対象領域にはデータサイエンス、機械学習、数学が含まれます。このチャンネルは最高の機械学習YouTubeチャンネルの一つとされています。 Joma Tech 登録日: 2016年9月1日 登録者数: 2.21M ビデオ数: 111…

「当社の独占的なマークダウンチートシートをチェックしてください」
Markdownは、複雑なHTMLや他の書式言語の必要性なく、さまざまな目的でテキストを簡単に書式設定する方法を提供する軽量のマークアップ言語です。そのシンプルさと使いやすさから、ドキュメンテーション、ブログ、その他の執筆プラットフォームで広く使用されています。このMarkdownチートシートでは、さまざまな書式オプションとそれらを効果的に使用する方法について説明します。 Markdownファイル Markdownは、プレーンテキストの書式設定を使用して豊かに書式設定されたドキュメントを作成する軽量のマークアップ言語です。これらのファイルは通常、.mdまたは.markdownの拡張子を持っています。ドキュメンテーションの作成、ブログ投稿の執筆、Webページのテキストの書式設定に一般的に使用されます。 マークダウンファイルをオフラインで開く方法 マークダウンファイルをオフラインで開くには、テキストエディタまたは専用のマークダウンエディタを使用できます。マークダウンファイルをオフラインで開く手順は次のとおりです: コンピュータ上のマークダウンファイルを見つけます。 ファイルを右クリックし、「開く」を選択します。 使用可能なプログラムのリストからテキストエディタまたはマークダウンエディタを選択します。 選択したエディタでマークダウンファイルが開き、その内容を表示および編集できます。 オンラインマークダウンエディタ オンラインマークダウンエディタは、ウェブブラウザで直接マークダウンファイルを作成およびプレビューするためのWebベースのツールです。これらのエディタは通常、リアルタイムのプレビュー、シンタックスハイライト、その他のマークダウンの作業に役立つ機能を提供します。 Markdownファイルの利点 学習と使用が容易: Markdownは、理解しやすく書きやすいシンプルな構文を持っています。HTMLやCSSのような複雑な書式設定コードは必要ありません。 プラットフォームに依存しない: Markdownファイルは、互換性のあるテキストエディタやマークダウンビューアを使用して、どのデバイスやオペレーティングシステムでも開いて表示することができます。 軽量: Markdownファイルはプレーンテキストファイルであり、小さくて読み込みが速いです。重い書式設定やスタイル情報は含まれていません。 バージョン管理に対応: MarkdownファイルはGitなどのバージョン管理システムとうまく機能します。マークダウンファイルへの変更は簡単に追跡、比較、マージすることができます。 ポータブル: Markdownファイルはさまざまなツールやコンバータを使用してHTML、PDF、Wordなどの他の形式に簡単に変換できます。このポータビリティにより、コンテンツを異なるプラットフォームやアプリケーションで共有することができます。 広くサポートされています:多くのテキストエディタ、コンテンツ管理システム(CMS)、パブリッシングプラットフォームがMarkdownをサポートしています。Web上でのコンテンツ作成において人気のある選択肢となっています。 では、Markdownチートシートを見てみましょう!…
1時間以内に初めてのディープラーニングアプリを作成しましょう
私はもう10年近くデータ分析をしています時折、データから洞察を得るために機械学習の技術を使用しており、クラシックな機械学習を使うことにも慣れています
LLMのトレーニングの異なる方法
大規模言語モデル(LLM)の領域では、さまざまなトレーニングメカニズムがあり、異なる手段、要件、目標がありますそれぞれが異なる目的を果たすため、混同しないようにすることが重要です...

「Gensimを使ったWord2Vecのステップバイステップガイド」
はじめに 数か月前、Office Peopleで働き始めた当初、私は言語モデル、特にWord2Vecに興味を持ちました。ネイティブのPythonユーザーとして、私は自然にGensimのWord2Vecの実装に集中し、論文やオンラインのチュートリアルを探しました。私は複数の情報源から直接コードの断片を適用し、複製しました。私はさらに深く探求し、自分の方法がどこで間違っているのかを理解しようとしました。Stackoverflowの会話、GensimのGoogleグループ、およびライブラリのドキュメントを読みました。 しかし、私は常にWord2Vecモデルを作成する上で最も重要な要素の一つが欠けていると考えていました。私の実験の中で、文をレンマ化することやフレーズ/バイグラムを探すことが結果とモデルのパフォーマンスに重要な影響を与えることを発見しました。前処理の影響はデータセットやアプリケーションによって異なりますが、この記事ではデータの準備手順を含め、素晴らしいspaCyライブラリを使って処理することにしました。 これらの問題のいくつかは私をイライラさせるので、自分自身の記事を書くことにしました。完璧だったり、Word2Vecを実装する最良の方法だったりすることは約束しませんが、他の多くの情報源よりも良いと思います。 学習目標 単語の埋め込みと意味的な関係の捉え方を理解する。 GensimやTensorFlowなどの人気のあるライブラリを使用してWord2Vecモデルを実装する。 Word2Vecの埋め込みを使用して単語の類似度を計測し、距離を算出する。 Word2Vecによって捉えられる単語の類推や意味的関係を探索する。 Word2Vecを感情分析や機械翻訳などのさまざまな自然言語処理のタスクに適用する。 特定のタスクやドメインに対してWord2Vecモデルを微調整するための技術を学ぶ。 サブワード情報や事前学習された埋め込みを使用して未知語を処理する。 Word2Vecの制約やトレードオフ、単語の意味の曖昧さや文レベルの意味について理解する。 サブワード埋め込みやWord2Vecのモデル最適化など、高度なトピックについて掘り下げる。 この記事はData Science Blogathonの一部として公開されました。 Word2Vecについての概要 Googleの研究チームは2013年9月から10月にかけて2つの論文でWord2Vecを紹介しました。研究者たちは論文とともにCの実装も公開しました。Gensimは最初の論文の後すぐにPythonの実装を完了しました。 Word2Vecの基本的な仮定は、文脈が似ている2つの単語は似た意味を持ち、モデルからは似たベクトル表現が得られるというものです。例えば、「犬」、「子犬」、「子犬」は似た文脈で頻繁に使用され、同様の周囲の単語(「良い」、「ふわふわ」、「かわいい」など)と共に使用されるため、Word2Vecによると似たベクトル表現を持ちます。 この仮定に基づいて、Word2Vecはデータセット内の単語間の関係を発見し、類似度を計算したり、それらの単語のベクトル表現をテキスト分類やクラスタリングなどの他のアプリケーションの入力として使用することができます。 Word2vecの実装 Word2Vecのアイデアは非常にシンプルです。単語の意味は、それが関連する単語と共に存在することによって推測できるという仮定をしています。これは「友だちを見せて、君が誰かを教えてあげよう」という言葉に似ています。以下はword2vecの実装例です。…
「倫理的かつ説明可能なAIのための重要なツール」
「機械学習モデルは、驚くべき予測能力を提供することにより、多くの分野を革命化しましたしかし、これらのモデルがますます普及するにつれて、公正さと...」
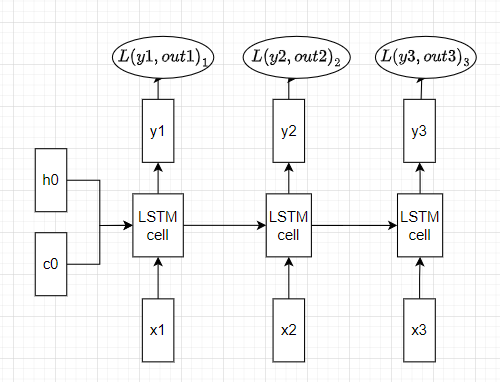
「RNNにおける誤差逆伝播法と勾配消失問題(パート2)」
このシリーズの第1部では、RNNモデルのバックプロパゲーションを解説し、数式と数値を用いてRNNにおける勾配消失問題を説明しましたこの記事では、次のことを行います...

「Amazon LexをLLMsで強化し、URLの取り込みを使用してFAQの体験を向上させる」
「現代のデジタル世界では、ほとんどの消費者は、ビジネスやサービスプロバイダに問い合わせるために時間をかけるよりも、自分自身でカスタマーサービスの質問に対する回答を見つけることを好む傾向にありますこのブログ記事では、ウェブサイトの既存のFAQを使用して、Amazon Lexで質問応答チャットボットを構築する革新的なソリューションについて探求します[...]」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.