Learn more about Search Results Gin - Page 233

- You may be interested
- システムデザインのチートシート:Elastic...
- 「ビッグデータプロジェクトに使用するデ...
- 「MLOpsは過学習していますその理由をここ...
- 「私たちのLLMモデルを強化するための素晴...
- クロード2 APIの使い方をはじめる
- 「アマゾンはAIによって書かれた本の到来...
- 進化的アルゴリズム-突然変異の解説
- メタAIの研究者がスタイルテーラリングを...
- 最初のLLMアプリを構築するために知ってお...
- 「ユネスコ、AIチップの埋め込みに関する...
- このAIの論文は、インコンテキスト学習の...
- AWSを使用したジェネレーティブAIを使用し...
- エンジニアからDeclarative MLを使ったML...
- 「生成AIの布地を調整する:FABRICは反復...
- NLPの就職面接をマスターする

より速いデータ検索のためのSQLクエリの最適化方法
今日は、なぜSQLクエリの最適化が重要であり、どのようなテクニックを使用して最適化できるかについて話します

Gorillaに会ってください:UCバークレーとMicrosoftのAPI拡張LLMは、GPT-4、Chat-GPT、およびClaudeを上回ります
モデルは、Torch Hub、TensorFlow Hub、およびHuggingFaceからのAPIによって拡張されています

データサイエンスチートシートのための10のChatGPTプラグイン
データサイエンスに最適なChatGPTプラグインの10選についての概要については、最新のチートシートをご覧ください

AIのマスタリング:プロンプトエンジニアリングソリューションの力
私と一緒にAIプロンプトエンジニアリングの素晴らしさを発見しましょう!ユーモアのある効果的なプロンプトの制作によって、AIモデルのフルポテンシャルを引き出すことができます
Amazon SageMaker 上で MPT-7B を微調整する
毎週新しい大規模言語モデル(LLM)が発表され、それぞれが前任者を打ち負かして評価のトップを狙っています最新のモデルの1つはMPT-7Bです
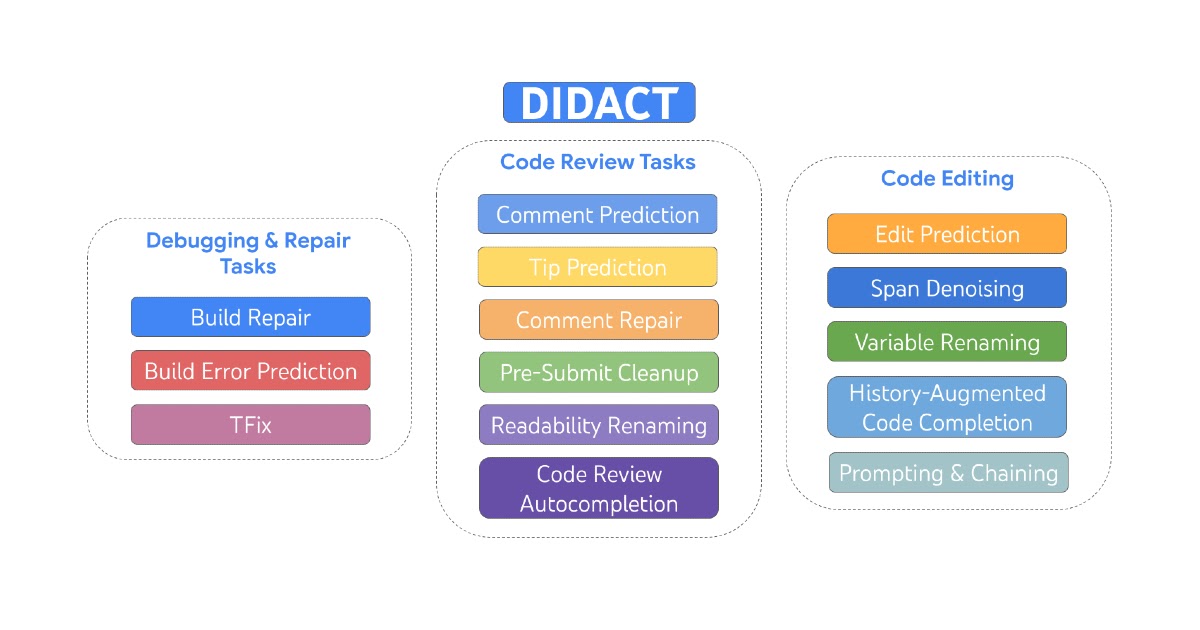
ソフトウェア開発活動のための大規模シーケンスモデル
Google の研究科学者である Petros Maniatis と Daniel Tarlow が投稿しました。 ソフトウェアは一度に作られるわけではありません。編集、ユニットテストの実行、ビルドエラーの修正、コードレビューのアドレス、編集、リンターの合意、そしてより多くのエラーの修正など、少しずつ改善されていきます。ついには、コードリポジトリにマージするに十分な良い状態になります。ソフトウェアエンジニアリングは孤立したプロセスではなく、人間の開発者、コードレビュワー、バグ報告者、ソフトウェアアーキテクト、コンパイラ、ユニットテスト、リンター、静的解析ツールなどのツールの対話です。 今日、私たちは DIDACT(Dynamic Integrated Developer ACTivity)を説明します。これは、ソフトウェア開発の大規模な機械学習(ML)モデルをトレーニングするための方法論です。 DIDACT の新規性は、完成したコードの磨き上げられた最終状態だけでなく、ソフトウェア開発のプロセス自体をトレーニングデータのソースとして使用する点にあります。開発者が作業を行う際に見るコンテキストと、それに対するアクションを組み合わせて、モデルはソフトウェア開発のダイナミクスについて学び、開発者が時間を費やす方法により合わせることができます。私たちは、Google のソフトウェア開発の計装を活用して、開発者活動データの量と多様性を以前の作品を超えて拡大しました。結果は、プロのソフトウェア開発者にとっての有用性と、一般的なソフトウェア開発スキルを ML モデルに注入する可能性という2つの側面で非常に有望です。 DIDACT は、編集、デバッグ、修復、およびコードレビューを含む開発活動をトレーニングするマルチタスクモデルです。 私たちは DIDACT Comment…

ビジュアルキャプション:大規模言語モデルを使用して、動的なビジュアルを備えたビデオ会議を補完する
Google Augmented Realityのリサーチサイエンティスト、Ruofei DuとシニアスタッフリサーチサイエンティストのAlex Olwalが投稿しました。 ライブキャプションやノイズキャンセリングなどの機能により、ビデオ会議の最近の進歩により、リモートビデオ通信は大幅に改善されました。しかし、複雑で微妙な情報をより良く伝えるために、動的な視覚的拡張が役立つ場面があります。たとえば、日本食レストランで何を注文するか話し合う場合、友達があなたが「すき焼き」を注文することに自信を持つのに役立つビジュアルを共有することができます。また、最近の家族旅行について話しているときに、個人的なアルバムから写真を見せたい場合があります。 ACM CHI 2023 で発表された「Visual Captions: Augmenting Verbal Communication With On-the-fly Visuals」では、私たちは、口頭の手がかりを使用してリアルタイムのビジュアルを使って同期ビデオ通信を拡張するシステムを紹介します。私たちは、この目的のためにキュレーションしたデータセットを使用して、オープンボキャブラリーの会話で関連するビジュアルを積極的に提案するために、大規模な言語モデルを微調整しました。私たちは、実時間の転写とともに拡張されたコミュニケーションの急速なプロトタイピングに設計されたARChatプロジェクトの一部としてVisual Captionsをオープンソース化しました。 Visual Captionsは、リアルタイムのビジュアルで口頭コミュニケーションを容易にします。このシステムは、リアルタイムの音声からテキストへの転写でよく見られる誤りにも対応しています。たとえば、文脈から外れて、転写モデルは「pier」という単語を「pair」と誤解しましたが、Visual Captionsはそれでもサンタモニカのピアの画像を推奨します。 動的なビジュアルで口頭コミュニケーションを拡張するための設計空間 私たちは、ソフトウェアエンジニア、研究者、UXデザイナー、ビジュアルアーティスト、学生など、様々な技術的および非技術的なバックグラウンドを持つ10人の内部参加者を招待し、潜在的なリアルタイムビジュアル拡張サービスの特定のニーズと欲求を議論しました。2つのセッションで、私たちは想定されるシステムの低保守性のプロトタイプを紹介し、その後、既存のテキストから画像へのシステムのビデオデモを示しました。これらの議論により、以下のようにD1からD8とラベル付けされた8つの次元の設計空間が生まれました。 ビジュアル拡張は、会話と同期または非同期に行われる場合があります(D1:時間)、話題の表現と理解の両方に使用できる場合があります(D2:主題)、さまざまなビジュアルコンテンツ、ビジュアルタイプ、ビジュアルソースを使用して適用できる場合があります(D3:ビジュアル)。このような視覚的拡張は、ミーティングの規模(D4:スケール)や、共同設置またはリモート設定でミーティングが行われているかどうか(D5:スペース)によって異なる場合があります。これらの要因はまた、ビジュアルが個人的に表示されるべきか、参加者間で共有されるべきか、あるいはすべての人に公開されるべきかを決定するのにも影響します(D6:プライバシー)。参加者はまた、会話をしながらシステムとやり取りするさまざまな方法を特定しました(D7:起動)。たとえば、人々は「プロアクティブ」の異なるレベルを提案しました。これは、ユーザーがモデルがイニシアチブを取る程度を示します。最後に、参加者は、入力に音声やジェスチャーを使用するなど、異なる相互作用方法を想定しました(D8:相互作用)。…

アクセラレータの加速化:科学者がGPUとAIでCERNのHPCを高速化
注:これは、高性能コンピューティングを利用した科学を前進させる研究者のシリーズの一環です。 Maria Gironeは、高速コンピューティングとAIを用いて、世界最大の科学コンピュータネットワークを拡大しています。 2002年以来、粒子物理学の博士号を持つ彼女は、40以上の国の170以上のサイトにまたがるシステムのグリッドで、CERNの大型ハドロン衝突型加速器(LHC)をサポートしています。HL-LHCと呼ばれる巨大加速器の高輝度版は、1年にエクサバイト単位のデータを生成する10倍の陽子衝突を生み出します。これは、2012年に2つの実験で宇宙の科学者たちの理解を確認したサブ原子粒子であるヒッグスボソンを発見したときに生成されたものよりも桁違いに多いです。 ジュネーブの呼び声 彼女は南イタリアで育った最初の日から科学が大好きでした。 「大学で、宇宙を支配する基本的な力について学びたかったので、物理学に焦点を合わせました」と彼女は言います。「私はCERNに惹かれました。それは、世界中の異なる地域の人々が科学に共通の情熱を持って一緒に働く場所です。」 レマン湖とジュラ山脈の間にある欧州原子核研究機構は、1万2千人以上の物理学者の中心地です。 CERNとフランス・スイス国境にあるLHCの地図(CERN提供の画像) 27キロメートルのリングは、陽子が光速の99.9999991%で疾走する世界最速のレーシングトラックと呼ばれることがあります。超伝導磁石は絶対零度に近く動作し、太陽よりも一時的に何百万倍も熱い衝突を生み出します。 ラボのドアを開く 2016年、Gironeは、革新を加速し、将来のコンピューティング課題に取り組むために学術および産業研究者を集めるグループであるCERN openlabのCTOに任命されました。彼女は、イタリアのHPCおよびAIの専門家であるE4 Computer Engineeringとの協力を通じて、NVIDIAと密接に協力しています。 最初の行動の1つで、GironeはCERN openlabのAIに関する最初のワークショップを開催しました。 産業界の参加者たちは、その技術に熱心でした。物理学者たちは、課題について説明しました。 「その日の終わりに、私たちは2つの異なる世界から来たことに気づきましたが、人々はお互いに耳を傾け、熱心に次に何をするか提案しました」と彼女は言います。 物理AIの高まり 今日、高エネルギー物理学全体のデータ処理チェーンにAIを適用する出版物の数が増加しているとGironeは報告しています。彼女は、複雑な問題をAIで解決する機会を見出す若い研究者を引き付けると述べています。 一方、研究者たちは物理ソフトウェアをGPUアクセラレータに移植し、GPU上で実行される既存のAIプログラムを使用しています。 「NVIDIAの支援なしに、私たちの研究者が問題を解決し、質問に答え、記事を書くために協力することは、これほど迅速には起こりませんでした」と彼女は言います。「NVIDIAの人々が、科学が技術と並行して進化する方法、およびGPUを用いたアクセラレーションをどのように利用できるかを理解していることは、非常に重要でした。」 エネルギー効率は、Gironeのチームの別の優先事項です。…

テクニカルアーティストがNVIDIA Omniverse USD Composerを使用して、優れたウールリーマンモスを構築しました今週の「In the NVIDIA Studio」
Editor’s note: この記事は、週刊NVIDIA Studioシリーズの一環であり、注目のアーティストを紹介し、クリエイティブなヒントやトリックを提供し、NVIDIA Studioテクノロジーがクリエイティブなワークフローを改善する方法を示しています。 3Dを専門とするシニアテクニカルアーティストのKeerthan Sathyaは、信じられないほど詳細で、熟練した作り方で作られ、見事な美しさを誇るアニメーション「Tiny Mammoth」で、NVIDIA Studioの中で勝利した。 Sathyaは、Adobe Substance 3D Modeler、Painter、Autodesk 3ds Maxなどの人気のある3Dアプリのコレクションをプロジェクトで使用し、ステージング、環境の準備、ライティング、レンダリングは、NVIDIA OmniverseのUSD Composerアプリで完了しました。 さらに、3Dの服を作成、編集、再利用するためのMarvelous Designerソフトウェアが、NVIDIA Omniverse Connectorで発売されました。 Universal Scene Description(OpenUSD)フレームワークは、ブリッジとして機能し、ユーザーがOmniverse…
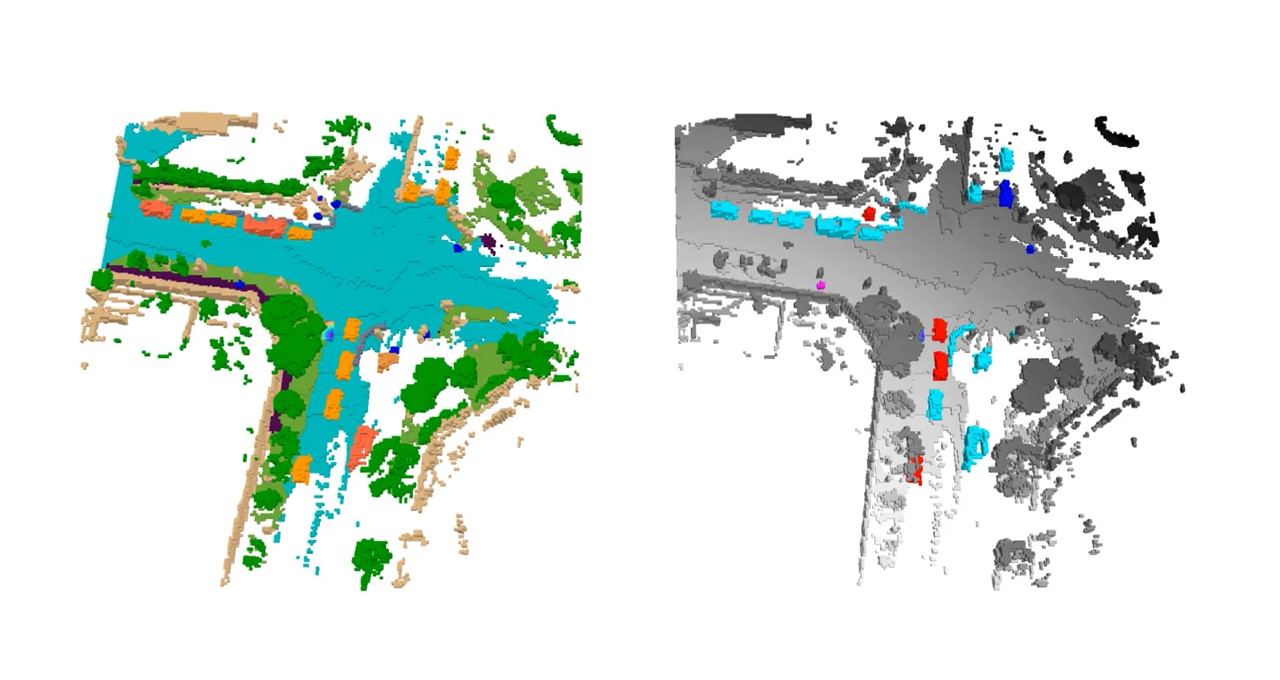
NVIDIAリサーチがCVPRで自律走行チャレンジとイノベーション賞を受賞
NVIDIAは、カナダのバンクーバーで開催されるComputer Vision and Pattern Recognition Conference(CVPR)において、自律走行開発の3D占有予測チャレンジで激戦を制し、優勝者として紹介されます。 この競技には、10地域にまたがる約150チームから400以上の投稿がありました。 3D占有予測とは、シーン内の各ボクセルの状態を予測するプロセスであり、つまり3Dバードアイビューグリッド上の各データポイントを指します。ボクセルは、フリー、占有、または不明として識別することができます。 安全で堅牢な自動運転システムの開発に不可欠な3D占有グリッド予測は、NVIDIA DRIVEプラットフォームによって可能になる最新の畳み込みニューラルネットワークやトランスフォーマーモデルを使用して、自律車両(AV)の計画および制御スタックに情報を提供します。 「NVIDIAの優勝ソリューションには、2つの重要なAVの進歩があります」と、NVIDIAの学習と知覚のシニアリサーチサイエンティストであるZhiding Yu氏は述べています。「優れたバードアイビュー認識を生み出す最新のモデル設計を実証することができます。さらに、3D占有予測での10億パラメーターまでのビジュアルファウンデーションモデルの効果と大規模な事前学習の有効性を示しています。」 自動運転の知覚は、画像内のオブジェクトや空きスペースなどの2Dタスクの処理から、複数の入力画像を使用して3Dで世界を理解することに進化しています。 これにより、複雑な交通シーン内のオブジェクトについて柔軟で精密な細かい表現が提供されるようになり、これはNVIDIAのAV応用研究および著名な科学者であるJose Alvarez氏によれば、「自律走行の安全感知要件を達成するために重要です。」 Yu氏は、NVIDIA Researchチームの受賞作品を、6月18日(日)10:20 a.m. PTに開催されるCVPRのEnd-to-End Autonomous Driving Workshopおよび6月19日(月)4:00 p.m. PTに開催されるVision-Centric…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.