Learn more about Search Results A - Page 232

- You may be interested
- Google DeepMindは、画期的なAI音楽生成器...
- レコメンダーシステムにおけるPrecision@N...
- 現代のデータエンジニアリング
- ゼロから大規模言語モデルを構築するため...
- 高度な言語モデルの世界における倫理とプ...
- AIが想像を絶する抗体を作成します:LabGe...
- 「アトムコンピューティング、1000以上の...
- 特徴変換:PCAとLDAのチュートリアル
- 科学者たちは、エイジ・オブ・エンパイア...
- Scikit-Learnを使用した特徴選択の方法
- 「トップAIベースのアートインペインティ...
- 「アナコンダのCEO兼共同創業者、ピーター...
- サイボーグゴキブリが迷路を進むことができる
- 企業がOpenAIのChatGPTに類似した自社の大...
- 「Amazon SageMaker JumpStartでのテキス...
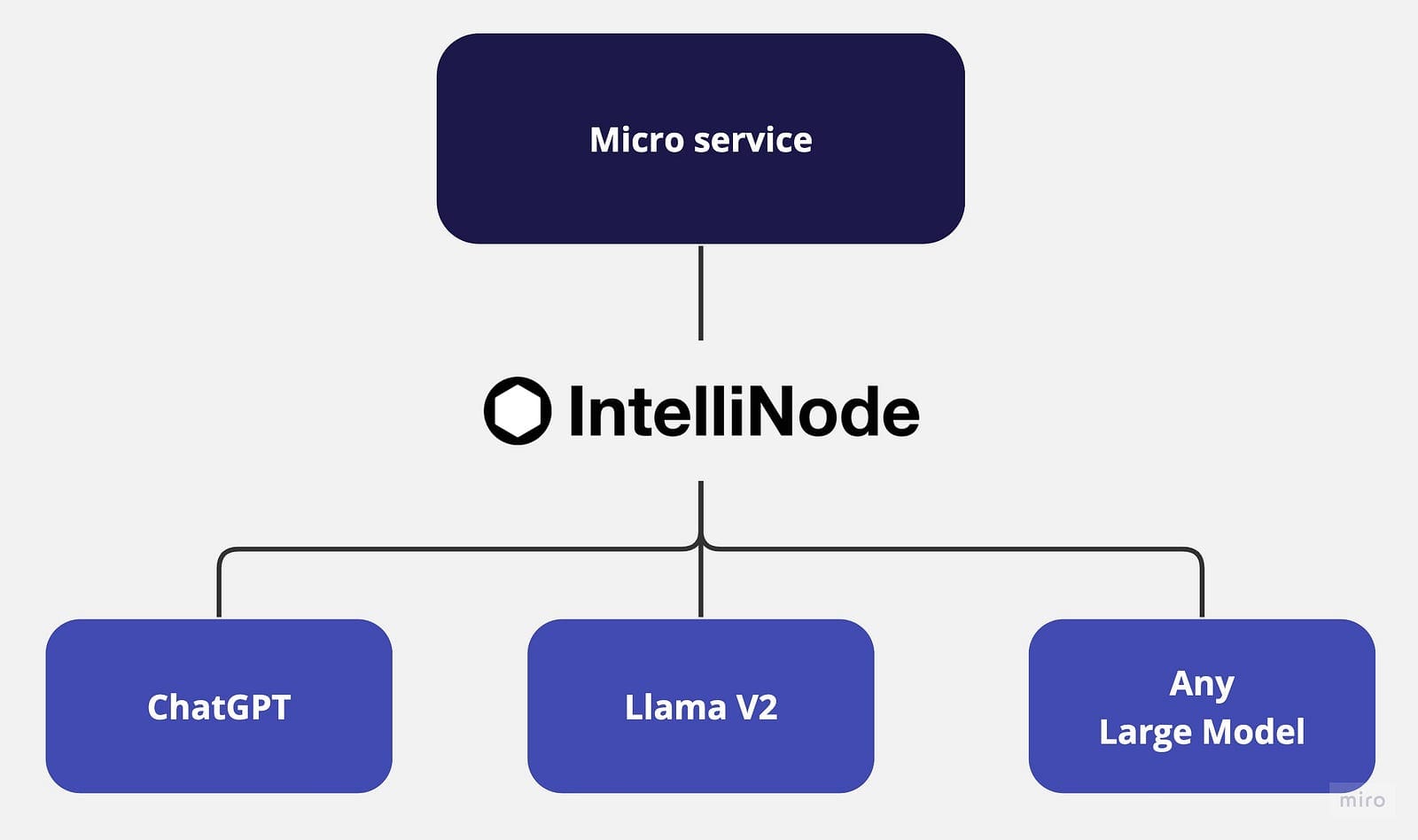
ラマとChatGPTを使用してマルチチャットバックエンドのマイクロサービスを構築する
LLM(Language Model)が進化し続けるにつれて、複数のモデルを統合したり、それらを切り替えることはますます困難になっていますこの記事では、モデルの統合をビジネスアプリケーションから分離し、プロセスを単純化するために、マイクロサービスアプローチを提案しています

「Anthropicは、AIチャットボットプラットフォームのClaudeの有料サブスクリプションを導入します」
会話型AI産業において画期的な瞬間となり、人工知能のリーディング企業であるAnthropicが、最先端のチャットボットに有料のサブスクリプションプラン(Claude Pro)を導入しましたこの動向は、AIチャットボットセクターの変化する景色を浮き彫りにし、企業がデジタル提供物の価値を評価する方法についての洞察を提供します提供する旅程[…]

「HuggingFaceを使用したLlama 2 7B Fine-TunedモデルのGPTQ量子化」
前の記事では、Meta AIが最近リリースした新しいLlama 2モデルを使用して、わずか数行のコードでPythonコードジェネレータを構築する方法を紹介しました今回は、...と説明します
「ジェネレーティブAIをマスターしたいなら、すべてを無視して(ただ2つだけを除いて)ツールに集中せよ」という文です
私たちは、生成型AIの疲労感がひどい状態です
「モデルの説明可能性、再考:SHAPとそれ以上」
「大規模言語モデルの急速な台頭は、最近のAIに関する議論の大部分を占めていますこれは理解できることですLLMの新奇さとその統合の速さを考えれば...」

「LLaSMと出会う:音声と言語の指示に従うクロスモーダルな対話能力を持つエンドツーエンドで訓練された大規模なマルチモーダル音声言語モデル」
音声はトーンなどの意味論的およびパラ言語的情報を含むため、書き込みよりも多くの情報を伝えます。さらに、話すことは人々がAIとのコミュニケーションを行うためのより実践的で有機的な方法です。そのため、一般的な目的のアシスタントを作成する際には、音声と言語のガイドラインに従うことが重要です。しかし、多くの大規模言語モデルはテキスト入力のみを受け付けるため、その潜在能力は制限されます。マルチモーダルなビジョンと言語のモデルにより、一般的な人工知能(AGI)の進歩が可能になりましたが、人間がテキストの指示を入力することは依然として手間がかかります。 音声認識(ASR)モデルは、カスケードパラダイムアプローチで使用され、音声入力をテキスト入力に変換し、モデルがジョブを処理するために使用できます。声からテキストへのモーダルの移行は、情報の消費を引き起こし、ASRシステムのエラーを導入する可能性があります。最近では、音声言語のマルチモーダルモデルが大規模言語モデルを使用して音声とテキストを理解し、生成することができるようになりました。音声信号は異なるトークンに分割され、LLMの語彙に拡張されます。この意味では、LLMは広範なマルチモーダルデータと強力な計算リソースを再トレーニングする必要があります。 LinkSoul.AI、北京大学、01.aiの著者らは、この研究で音声と言語の相互作用を理解し、話された命令に従う能力を持つ大規模な音声と言語のモデルLLaSMを提案しています。彼らは、LLaVAと同様に、訓練済みの音声モーダルエンコーダとLLMを使用しており、これによりLLaSMはリソースを節約できます。彼らは特に、音声エンコーダとしてWhisperを使用し、音声信号を組み込みます。大規模言語モデルの入力テキスト埋め込みは、モーダルアダプタを使用して音声埋め込みと一致させます。音声とテキストの埋め込みを組み合わせて、交互になったシーケンスを作成します。交互になったシーケンスは、監督付きの微調整のためにLLMに供給されます。 トレーニング手順には2つのフェーズがあります。初期段階では、パブリックのASRデータセットを使用してモーダルアダプタの事前トレーニングを行います。モーダルアダプタのみがトレーニングされ、音声エンコーダとLLMはロックされます。この段階では、モーダルアダプタの一部のパラメータが導入されるため、モデルのパラメータの大部分はまだ修正が必要ですが、リソースを消費することはありません。2番目のステップでは、クロスモーダルな指示データを使用して、モデルがマルチモーダルな指示を処理し、クロスモーダルな相互作用を分析できるようにします。クロスモーダル教育のために言語モデルとモーダルアダプタの設定が変更される間、音声エンコーダは固定されます。 重要なことは、オープンソースの音声テキストクロスモーダル指示フォローのデータセットはほとんど存在しないということです。したがって、彼らはLLaSM-Audio-Instructionsデータセットを作成し、公開しました。このデータセットは、GPT4-LLM、ShareGPT、WizardLMからの会話を慎重に選び、テキスト読み上げ技術を使用して大量の会話音声データを作成しています。彼らの知る限り、これは最大の中国語と英語の音声テキストクロスモーダル指示フォローのデータセットであり、199,000の対話、80,000の中国語の音声サンプル、428,000の英語の音声サンプルを含んでいます。 彼らの研究は以下の貢献をしています: • 音声と言語を理解し、音声と言語のコマンドを実行できる音声言語のマルチモーダルモデルを作成しました。これにより、人々が人工知能とコミュニケーションを取るためのより実践的で有機的な方法が提供されます。 • 中国語と英語の音声とテキストを組み合わせたクロスモーダルな指示フォローの大規模データセットLLaSM-Audio-Instructionsを作成し、公開しました。 • デモはHuggingFaceのオンラインで、コードはGitHubで閲覧できます。

「Google Researchが探求:AIのフィードバックは、大規模な言語モデルの効果的な強化学習において人間の入力を置き換えることができるのか?」
人間のフィードバックは、機械学習モデルを改善し最適化するために不可欠です。近年、人間のフィードバックからの強化学習(RLHF)は、大規模な言語モデル(LLM)を人間の好みに合わせるのに非常に効果的であることが証明されていますが、高品質の人間の好みのラベルを収集するという重要な課題があります。Google AIの研究者たちは、研究の中でRLHFとAIフィードバックからの強化学習(RLAIF)を比較しようと試みました。 RLAIFは、人間のアノテーターに頼らずに事前に訓練されたLLMによって優先順位が付けられる技術です。 この研究では、研究者たちは要約タスクの文脈でRLAIFとRLHFを直接比較しました。彼らは、テキストが与えられた場合に2つの候補応答の優先順位ラベルを提供することを課されました。これには、市販の大規模言語モデル(LLM)を利用して推測された優先順位に基づいて報酬モデル(RM)をトレーニングし、対照的な損失を組み込むことが含まれています。最後のステップでは、強化学習の技術を用いてポリシーモデルを微調整することが求められました。上記の画像は、RLAIF(上)とRLHF(下)を示すダイアグラムを示しています。 上記の画像は、Redditの投稿に対してSFT、RLHF、RLAIFのポリシーによって生成された例の要約を示しています。SFTはキーポイントを捉えることができず、RLHFとRLAIFはより高品質の要約を生成しました。 この研究で示された結果は、次の2つの異なる方法で評価された場合に、RLAIFがRLHFと同等のパフォーマンスを達成していることを示しています: まず、RLAIFとRLHFのポリシーはそれぞれの場合において、監視された微調整(SFT)ベースラインよりも人間の評価者から好意を受け取ったことが71%と73%のケースで観察されました。重要なことに、統計分析によって2つのアプローチ間の勝率に有意差は見られませんでした。 次に、RLAIFとRLHFによって生成された結果を直接比較するように人間に求めた場合、両方に対して同等の好みが表明され、それぞれの方法について50%の勝率となりました。これらの結果から、RLAIFは人間の注釈に依存せず、魅力的なスケーラビリティ特性を持つRLHFの代替手段であることが示唆されます。 この研究では要約タスクのみを探求しており、他のタスクへの一般化についてのオープンな問題が残されています。さらに、この研究では、費用対効果の観点から人間のラベリングと比較して大規模言語モデル(LLM)の推論がどれほど費用対効果があるかの推定は含まれていません。研究者は将来的にこの領域を探求することを望んでいます。

「Pandasのスピードを向上させ、ミリ秒単位で1000万行のデータセットを処理する方法」
「私は過去3年間Pandasを使用してきた中で、何度も言ったと思います最も最近見たものでは、「Pandasを71,803倍速くする」と言っていましたでも、そんなものは与えません…」

MatplotlibとSeabornを使ったビジュアルの作成
「仕事に役立つ基本的なPythonパッケージの可視化を学びましょう」

「AIを活用したポッドキャストの始め方と成長方法」
「誰でもポッドキャストを持っているように感じるかもしれませんが、ポッドキャストを始めることはまだ大きなチャンスです特にAIの助けを借りれば、さらに大きな機会があります」
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.