Learn more about Search Results Ford - Page 22

- You may be interested
- 「GPT-4の能力と限界を探索する」
- MITの研究者が、生成プロセスの改善のため...
- OpenAIのAI安全性へのアプローチ
- 「メタのMusicGenを使用してColabで音楽を...
- 「デロイトの「Generative AI Dossier」を...
- 「LangChain、Activeloop、そしてGPT-4を...
- AIの今週、8月18日:OpenAIが財政的な問題...
- データサイエンスの成功への道は、学習能...
- 日本の介護施設はビッグデータを活用して...
- 「DeepMind AIが数百万の動画のために自動...
- LLM黙示録:オープンソースクローンの復讐
- 機械学習によるストレス検出の洞察を開示
- 「Andrej Karpathy LLM Paper Reading Lis...
- 「最高のAI音楽生成器(2023年9月)」
- 2023年9月のトップAIメールアシスタント

現代のNLP:詳細な概要パート2:GPT
シリーズの第一部では、Transformerが自然言語処理と理解のシーケンスモデリング時代を終了させたことについて話しましたこの記事では、私たちは...に焦点を当てることを目指しています

DPT(Depth Prediction Transformers)を使用した画像の深度推定
イントロダクション 画像の深度推定は、画像内のオブジェクトがどれだけ遠いかを把握することです。これは、3Dモデルの作成、拡張現実、自動運転などのコンピュータビジョンの重要な問題です。過去には、ステレオビジョンや特殊センサなどの技術を使用して深度を推定していました。しかし、今では、ディープラーニングを利用するDepth Prediction Transformers(DPT)と呼ばれる新しい方法があります。 DPTは、画像を見ることで深度を推定することができるモデルの一種です。この記事では、実際のコーディングを通じてDPTの動作原理、その有用性、およびさまざまなアプリケーションでの利用方法について詳しく学びます。 学習目標 密な予測トランスフォーマ(DPT)の概念と画像の深度推定における役割。 ビジョントランスフォーマとエンコーダーデコーダーフレームワークの組み合わせを含むDPTのアーキテクチャの探索。 Hugging Faceトランスフォーマライブラリを使用したDPTタスクの実装。 さまざまな領域でのDPTの潜在的な応用の認識。 この記事はData Science Blogathonの一部として公開されました。 深度推定トランスフォーマの理解 深度推定トランスフォーマ(DPT)は、画像内のオブジェクトの深度を推定するために特別に設計されたディープラーニングモデルの一種です。DPTは、元々言語データの処理に開発されたトランスフォーマと呼ばれる特殊なアーキテクチャを利用して、ビジュアルデータを処理するために適応し適用します。DPTの主な強みの1つは、画像のさまざまな部分間の複雑な関係をキャプチャし、長距離にわたる依存関係をモデル化する能力です。これにより、DPTは画像内のオブジェクトの深度や距離を正確に予測することができます。 深度推定トランスフォーマのアーキテクチャ 深度推定トランスフォーマ(DPT)は、ビジョントランスフォーマをエンコーダーデコーダーフレームワークと組み合わせて画像の深度を推定します。エンコーダーコンポーネントは、セルフアテンションメカニズムを使用して特徴をキャプチャしてエンコードし、画像のさまざまな部分間の関係を理解する能力を向上させます。これにより、細かい詳細を捉えることができます。デコーダーコンポーネントは、エンコードされた特徴を元の画像空間にマッピングすることで密な深度予測を再構築し、アップサンプリングや畳み込み層のような手法を利用します。DPTのアーキテクチャにより、モデルはシーンのグローバルなコンテキストを考慮し、異なる画像領域間の依存関係をモデル化することができます。これにより、正確な深度予測が可能になります。 要約すると、DPTはビジョントランスフォーマとエンコーダーデコーダーフレームワークを組み合わせて画像の深度を推定します。エンコーダーは特徴をキャプチャし、セルフアテンションメカニズムを使用してそれらをエンコードし、デコーダーは密な深度予測を再構築します。このアーキテクチャにより、DPTは細かい詳細を捉え、グローバルなコンテキストを考慮し、正確な深度予測を生成することができます。 Hugging Face Transformerを使用したDPTの実装 Hugging Faceパイプラインを使用してDPTの実践的な実装を見ていきます。コードの全体はこちらでご覧いただけます。…

「Amazon SageMakerを使用して、効率的にカスタムアンサンブルをトレーニング、チューニング、デプロイする」
「人工知能(AI)は、テクノロジーコミュニティで重要かつ人気のあるトピックとなっていますAIが進化するにつれて、さまざまなタイプの機械学習(ML)モデルが登場してきましたアンサンブルモデリングとして知られるアプローチは、データサイエンティストや実践者の間で急速に注目を集めていますこの記事では、アンサンブルモデルとは何かについて議論します...」
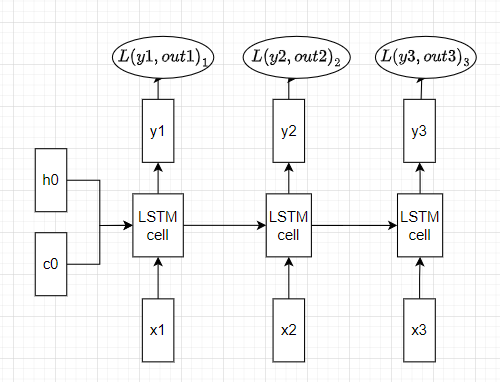
「RNNにおける誤差逆伝播法と勾配消失問題(パート2)」
このシリーズの第1部では、RNNモデルのバックプロパゲーションを解説し、数式と数値を用いてRNNにおける勾配消失問題を説明しましたこの記事では、次のことを行います...
「PythonでPandasを使うための包括的なガイド」
データ分析、エンジニアリング、または科学の文脈でPythonを使用し始めるとき、おそらく最初に学ぶべきライブラリの1つがpandasですこの素晴らしいライブラリは…

私の物理学の博士号へのオード
「1年前、私は博士論文を守りました部屋は通りすがりの人々がのぞき込めるように壁一面に窓があるため、俗に「ガラス張りの部屋」と呼ばれていましたそれは金曜日の午後4時でした...」

「Hugging Faceにおけるオープンソースのテキスト生成とLLMエコシステム」
テキスト生成と対話技術は古くから存在しています。これらの技術に取り組む上での以前の課題は、推論パラメータと識別的なバイアスを通じてテキストの一貫性と多様性を制御することでした。より一貫性のある出力は創造性が低く、元のトレーニングデータに近く、人間らしさに欠けるものでした。最近の開発により、これらの課題が克服され、使いやすいUIにより、誰もがこれらのモデルを試すことができるようになりました。ChatGPTのようなサービスは、最近GPT-4のような強力なモデルや、LLaMAのようなオープンソースの代替品が一般化するきっかけとなりました。私たちはこれらの技術が長い間存在し、ますます日常の製品に統合されていくと考えています。 この投稿は以下のセクションに分かれています: テキスト生成の概要 ライセンス Hugging FaceエコシステムのLLMサービス用ツール パラメータ効率の良いファインチューニング(PEFT) テキスト生成の概要 テキスト生成モデルは、不完全なテキストを完成させるための目的で訓練されるか、与えられた指示や質問に応じてテキストを生成するために訓練されます。不完全なテキストを完成させるモデルは因果関係言語モデルと呼ばれ、有名な例としてOpenAIのGPT-3やMeta AIのLLaMAがあります。 次に進む前に知っておく必要がある概念はファインチューニングです。これは非常に大きなモデルを取り、このベースモデルに含まれる知識を別のユースケース(下流タスクと呼ばれます)に転送するプロセスです。これらのタスクは指示の形で提供されることがあります。モデルのサイズが大きくなると、事前トレーニングデータに存在しない指示にも一般化できるようになりますが、ファインチューニング中に学習されたものです。 因果関係言語モデルは、人間のフィードバックに基づいた強化学習(RLHF)と呼ばれるプロセスを使って適応されます。この最適化は、テキストの自然さと一貫性に関して行われますが、回答の妥当性に関しては行われません。RLHFの仕組みの詳細については、このブログ投稿の範囲外ですが、こちらでより詳しい情報を見つけることができます。 例えば、GPT-3は因果関係言語のベースモデルですが、ChatGPTのバックエンドのモデル(GPTシリーズのモデルのUI)は、会話や指示から成るプロンプトでRLHFを用いてファインチューニングされます。これらのモデル間には重要な違いがあります。 Hugging Face Hubでは、因果関係言語モデルと指示にファインチューニングされた因果関係言語モデルの両方を見つけることができます(このブログ投稿で後でリンクを提供します)。LLaMAは最初のオープンソースLLMの1つであり、クローズドソースのモデルと同等以上の性能を発揮しました。Togetherに率いられた研究グループがLLaMAのデータセットの再現であるRed Pajamaを作成し、LLMおよび指示にファインチューニングされたモデルを訓練しました。詳細についてはこちらをご覧ください。また、Hugging Face Hubでモデルのチェックポイントを見つけることができます。このブログ投稿が書かれた時点では、オープンソースのライセンスを持つ最大の因果関係言語モデルは、MosaicMLのMPT-30B、SalesforceのXGen、TII UAEのFalconの3つです。 テキスト生成モデルの2番目のタイプは、一般的にテキスト対テキスト生成モデルと呼ばれます。これらのモデルは、質問と回答または指示と応答などのテキストのペアで訓練されます。最も人気のあるものはT5とBARTです(ただし、現時点では最先端ではありません)。Googleは最近、FLAN-T5シリーズのモデルをリリースしました。FLANは指示にファインチューニングするために開発された最新の技術であり、FLAN-T5はFLANを使用してファインチューニングされたT5です。現時点では、FLAN-T5シリーズのモデルが最先端であり、オープンソースでHugging Face Hubで利用可能です。入力と出力の形式は似ているかもしれませんが、これらは指示にファインチューニングされた因果関係言語モデルとは異なります。以下は、これらのモデルがどのように機能するかのイラストです。 より多様なオープンソースのテキスト生成モデルを持つことで、企業はデータをプライベートに保ち、ドメインに応じてモデルを適応させ、有料のクローズドAPIに頼る代わりに推論のコストを削減することができます。Hugging…
「ベクトルデータベースの力を活用する:個別の情報で言語モデルに影響を与える」
この記事では、ベクトルデータベースと大規模言語モデルという2つの新しい技術がどのように連携して動作するかについて学びますこの組み合わせは現在、大きな変革を引き起こしています...

言語ドメインにおける画期的かつオープンソースの対話型AIモデルのリスト
会話型AIは、仮想エージェントやチャットボットのような技術を指し、大量のデータと自然言語処理を使用して人間の対話を模倣し、音声とテキストを認識するものです。最近、会話型AIの領域は大きく進化し、特にChatGPTの登場によります。以下は、会話型AIを革新している他のオープンソースの大規模言語モデル(LLM)のいくつかです。 LLaMA リリース日:2023年2月24日 LLaMaは、Meta AIによって開発された基礎的なLLMです。他のモデルよりも柔軟で責任ある設計となっています。LLaMaのリリースは、研究コミュニティへのアクセスを民主化し、責任あるAIの実践を促進することを目的としています。 LLaMaは、7Bから65Bまでのパラメータ数の異なるサイズで提供されています。モデルへのアクセス許可は、業界の研究所、学術研究者などに対してケースバイケースで付与されます。 OpenAssistiant リリース日:2023年3月8日 Open Assistantは、LAION-AIによって開発されたプロジェクトで、優れたチャットベースの大規模言語モデルを提供することを目的としています。大量のテキストとコードのトレーニングを通じて、クエリへの応答、テキスト生成、言語の翻訳、創造的なコンテンツの生成など、さまざまなタスクを実行する能力を獲得しています。 OpenAssistantはまだ開発段階ですが、Google検索などの外部システムとのやり取りを通じて情報を収集するなど、既にいくつかのスキルを獲得しています。また、オープンソースのイニシアチブでもあり、誰でも進展に貢献することができます。 Dolly リリース日:2023年3月8日 Dollyは、Databricksによって開発された命令に従うLLMです。商用利用のためにライセンスされたDatabricksの機械学習プラットフォームでトレーニングされています。DollyはPythia 12Bモデルで動作し、約15,000件の命令/応答のレコードをトレーニングデータとして使用しています。最先端ではありませんが、Dollyは命令に従うパフォーマンスが非常に高品質です。 Alpaca リリース日:2023年3月13日 Alpacaは、スタンフォード大学によって開発された小規模な命令に従うモデルです。MetaのLLaMa(7Bパラメータ)モデルをベースにしています。多くの命令に従うタスクで優れたパフォーマンスを発揮する一方で、再現性も容易で安価になるように設計されています。 OpenAIのtext-davinci-003モデルに似ていますが、製作コストがかなり安価(<$600)です。モデルはオープンソースであり、52,000の命令に従うデモンストレーションのデータセットでトレーニングされています。 Vicuna リリース日:2023年4月 Vicunaは、UC Berkeley、CMU、Stanford、UC San…
ローカルで質問応答(QA)タスク用にLLMを微調整する方法
抽出型QA:これは、システムが与えられたテキスト(供給されるテキスト)から質問の答えを抽出するタスクですこれは、最も一般的なQAシステムの形式であり、ほとんどの汎用…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.