Learn more about Search Results - Page 22

- You may be interested
- 「盲目的なキャリブレーションによる無線...
- 世界のデータを処理できるアーキテクチャ...
- 「Amazon Titanを使用して簡単に意味論的...
- 「OpenAIがオープンソースのGPTモデルのリ...
- 「人間によるガイド付きAIフレームワーク...
- ETH Zurichの研究者が、推論中に0.3%のニ...
- 「松ぼっくりベクトルデータベースとAmazo...
- 「13の簡単なステップでローカルコンピュ...
- 『Retrieval-Augmented GenerationとSelf-...
- AIコーディングツールが登場しました:製...
- 微調整、再教育、そして更なる進化:カス...
- Amazon SageMaker JumpStartを使用した対...
- 「Databricks、MosaicMLおよびその他の最...
- 「パリを拠点とするスタートアップであり...
- LLMOps:ハミルトンとのプロダクションプ...

DeepMindの最新のICLR 2022での研究
スポンサーとしてのイベント支援や定期的なワークショップ主催に加えて、今年は10件の共同研究を含む29件の論文を発表します以下に、私たちの今後の口頭発表、スポットライト発表、ポスター発表の一部をご紹介します
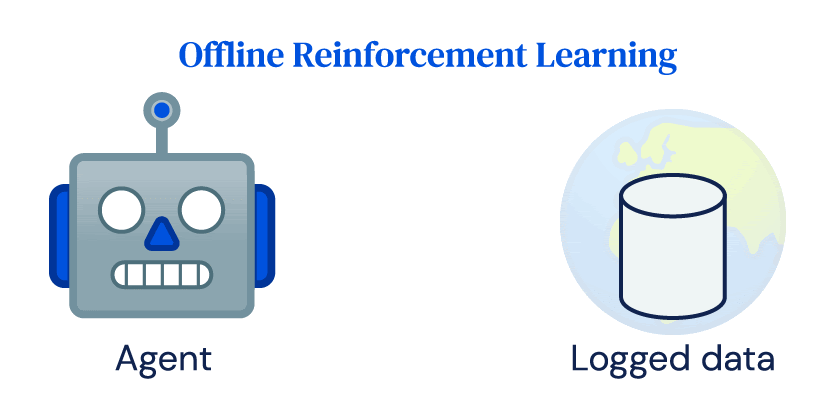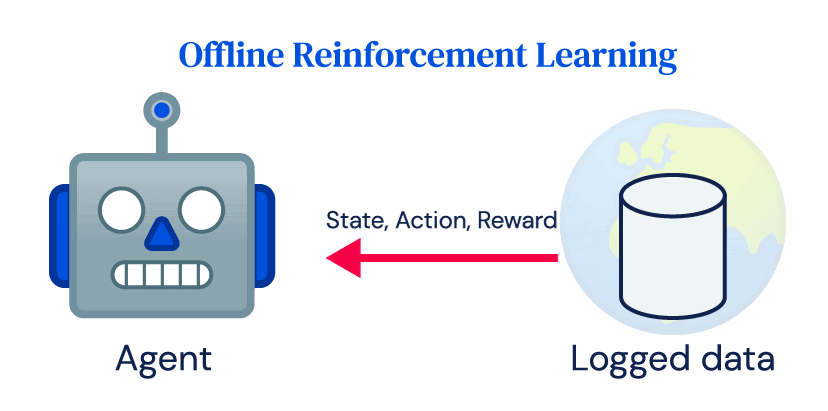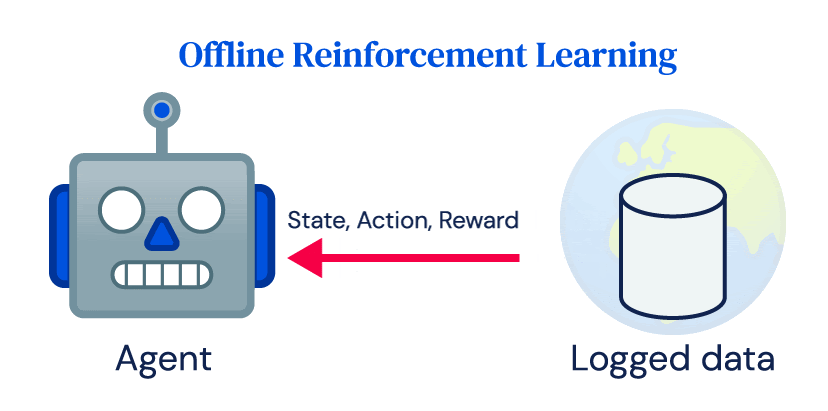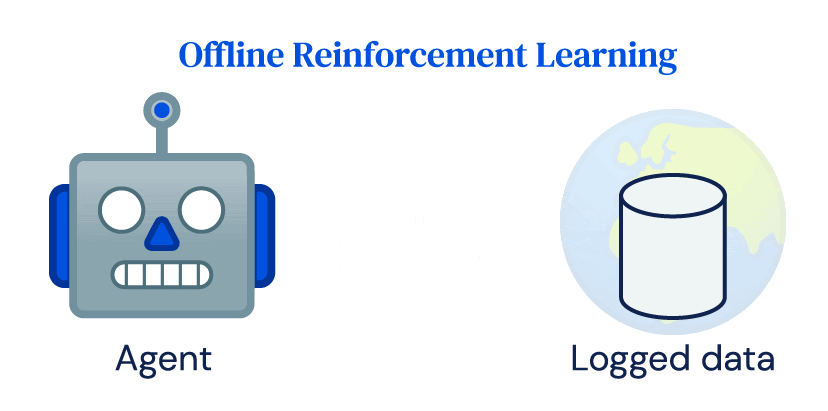
RLアンプラグド:オフライン強化学習のベンチマーク
私たちは、オフラインRL(強化学習)手法の評価と比較を行うためのベンチマークとして「RL Unplugged」というものを提案していますRL Unpluggedには、Atariベンチマークなどのゲームや、DM Control Suiteなどのシミュレートされたモーターコントロール問題など、さまざまなドメインのデータが含まれていますこれらのデータセットには、部分的または完全に観測可能なドメイン、連続または離散のアクションの使用、確率的または確定的なダイナミクスがあるドメインなどが含まれています

AlphaFold 生物学における50年間の偉大な課題への解決策
タンパク質は、実質的にすべての生命機能をサポートするために必要不可欠ですタンパク質は、アミノ酸の鎖から成る大きく複雑な分子であり、タンパク質が行う役割は、その固有の3D構造に大きく依存しますタンパク質がどのような形状に折りたたまれるかを解明することは、「タンパク質の折りたたみ問題」として知られ、過去50年間、生物学の重要な課題として存在してきました最新バージョンのAIシステムAlphaFoldは、二年ごとに行われるタンパク質構造予測の重要な評価(CASP)の主催者によって、この大きな課題の解決策として認識されましたこのブレイクスルーは、AIが科学的な発見に与える影響と、私たちの世界を説明し形作る最も基本的な分野の進歩を劇的に加速する可能性を示しています

JAXを使用して研究を加速化する
DeepMindのエンジニアは、ツールの構築、アルゴリズムのスケーリングアップ、そして人工知能(AI)システムのトレーニングとテストのための挑戦的な仮想および物理世界の作成により、私たちの研究を加速させていますこの取り組みの一環として、私たちは常に新しい機械学習ライブラリやフレームワークの評価を行っています

MuZero ルールなしでGo、チェス、将棋、アタリをマスターする
2016年、我々はAlphaGoという初めて人間を囲碁で打ち負かすことのできる人工知能(AI)プログラムを紹介しました2年後、その後継者であるAlphaZeroは、ゼロから囲碁、チェス、将棋をマスターするために学習しましたそして今、学術誌Natureに掲載された論文で、我々はMuZeroを紹介していますこれは汎用アルゴリズムの追求において重要な進展ですMuZeroは、未知の環境で勝利戦略を計画する能力により、ルールを教えられることなく囲碁、チェス、将棋、アタリをマスターします
.jpg)
プロテオームスケールでの高精度なタンパク質構造予測を可能にする
多くの新しい機械学習のイノベーションがAlphaFoldの現在の精度に貢献しています以下にシステムの概要を高レベルで示しますネットワークアーキテクチャの技術的な説明については、私たちのAlphaFoldのメソッド論文と特に詳細な補足情報をご覧ください

アルファフォールドの力を世界の手に
昨年12月にAlphaFold 2を発表した際、それは50年間のタンパク質折りたたみ問題の解決策として称賛されました先週、私たちはこの非常に革新的なシステムを作成する方法についての科学論文とソースコードを公開しましたそして、本日は人体のすべてのタンパク質の形状に関する高品質な予測を共有していますさらに、科学者が研究に頼る20の追加の生物のタンパク質の形状についても予測を行っています

一般的に、オープンエンドの遊びから優れたエージェントが生まれる
近年、人工知能エージェントは複雑なゲーム環境で成功を収めています例えば、AlphaZeroは、プレイ方法の基本ルールを知らないままスタートし、チェス、将棋、囲碁の世界チャンピオンプログラムに勝利しました強化学習(RL)を通じて、この単一のシステムは、試行錯誤の反復的なプロセスを通じて、ゲームのラウンドごとにプレイすることで学習しましたしかし、AlphaZeroはまだ各ゲームごとに別々にトレーニングを行いましたRLのプロセスをゼロから繰り返さなければ、別のゲームやタスクを単純に学習することはできませんでしたAtari、Capture the Flag、StarCraft II、Dota 2、Hide-and-Seekなど、RLの他の成功も同様ですDeepMindの使命である科学と人類の進歩のための知能の解決策を見つけるために、私たちはこの制限を克服する方法を探求しました一度に1つのゲームを学習する代わりに、これらのエージェントは完全に新しい条件に反応し、見たこともないゲームやタスクを含む、さまざまなゲームやタスクをプレイできるようになるはずです

次の1時間の雨を予測する
私たちの生活は天候に依存していますイギリスではいつでも、ある研究によると、国の1/3が過去1時間以内に天気について話し合ったとされ、天候の重要性が日常生活に反映されています天候現象の中でも、雨は特に重要ですなぜなら、雨は私たちの日常の決定に影響を与えるからです傘を持っていくべきか?大雨に見舞われた車両のルートはどうすべきか?屋外イベントにおける安全対策は何か?洪水が発生するかもしれないのか?私たちの最新の研究と最先端のモデルは、次の1〜2時間以内に雨(および他の降水現象)を予測する降水現在予測の科学を進化させていますメットオフィスとの共同執筆による論文が自然に掲載され、天気予測におけるこの重要な大課題に直接取り組んでいます環境科学とAIの連携は、意思決定者のための価値に焦点を当て、降水現在予測の新たな可能性を開拓し、環境が絶えず変化する中での意思決定の課題に対するAIの支援の機会を指摘しています
.jpg)
マルコフ報酬の表現力について
私たちの主な結果は、報酬が多くのタスクを表現できる一方で、各タスクタイプのインスタンスにはマルコフ報酬関数では捉えられないものが存在することを証明していますその後、私たちは、各タイプのタスクを最適化するための報酬関数を構築するための多項式時間アルゴリズムのセットを提供し、そのような報酬関数が存在しない場合を正しく判断することができます
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.