Learn more about Search Results Gin - Page 226

- You may be interested
- チューリッヒ大学の研究者たちは、スイフ...
- 「AIの使用を支持する俳優たちと、支持し...
- 学校でのAI教育の台頭:現実と未来の可能...
- 「AIの透明性を解き放つ:Anthropicのフィ...
- 事前学習済みのViTモデルを使用した画像キ...
- メタ AI 研究者たちは、非侵襲的な脳記録...
- GPTモデルを活用して、自然言語をSQLクエ...
- 「マイクロソフトのシニアデータサイエン...
- 「トップ40以上の創発的AIツール(2023年1...
- ソウル国立大学の研究者たちは、効率的か...
- 「米中のチップ紛争に新たな戦線が開かれる」
- 「2023年にPrompt Engineeringを使用する...
- 世界最大のオープンマルチリンガル言語モ...
- 「ChatGPTを使用して完全な製品を作成する...
- 「ハグフェース上のトップ10大きな言語モ...

GPTエンジニア:1つのプロンプトで強力なアプリを構築する
GPTエンジニアは、1つのプロンプトで完全なコーディングプロジェクトを構築できるAIエージェントです

ビジネスにおける機械学習オペレーションの構築
私のキャリアで気づいたことは、成功したAI戦略の鍵は機械学習モデルを本番環境に展開し、それによって商業的な可能性をスケールで解放する能力にあるということですしかし…
一度言えば十分です!単語の繰り返しはAIの向上に役立ちません
大規模言語モデル(LLM)はその能力を示し、世界中で話題になっています今や、すべての大手企業は洒落た名前を持つモデルを持っていますしかし、その裏にはすべてトランスフォーマーが動いています...
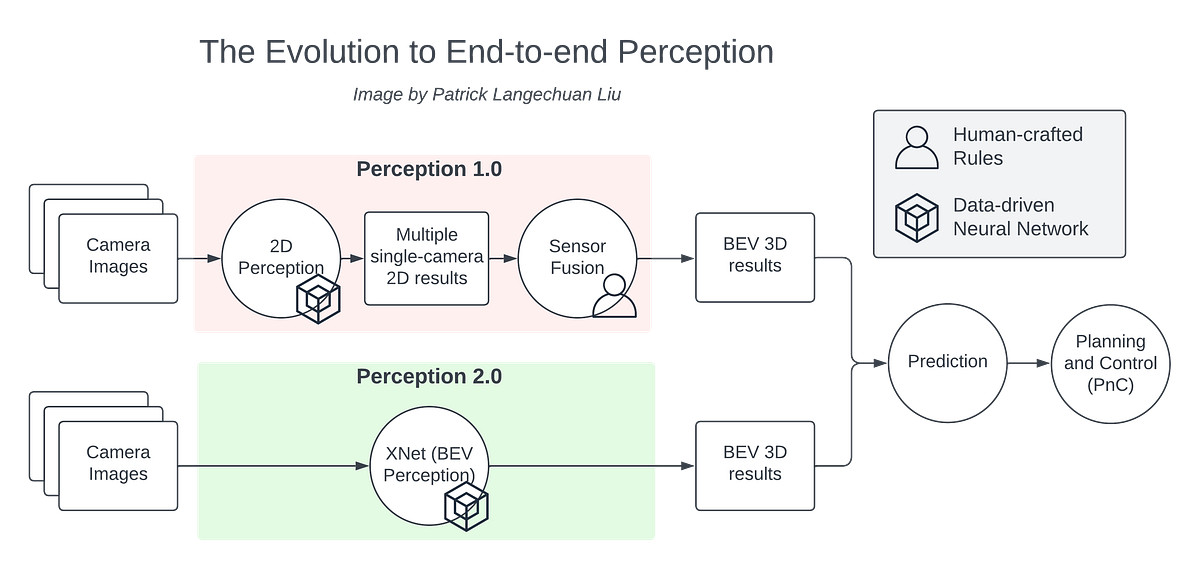
量産自動運転におけるBEVパーセプション
BEVの認識技術は、ここ数年で非常に進歩しました自動運転車の周りの環境を直接認識することができますBEVの認識技術はエンド・トゥ・エンドと考えることができます
Rのggvancedパッケージを使用したスパイダーチャートと並列チャート
ggplot2パッケージの上に、スパイダーチャートや平行チャートなどの高度な多変数データ可視化を生成するためのパッケージ
スターバックスの報酬プログラムの成功を予測する
このプロジェクトは、スターバックスの現在の顧客を効果的に引きつけ、新しい顧客を獲得するための報酬プログラムオファーを特定することに焦点を当てていますスターバックスはデータに基づく会社であり、入手するために投資を行っています...
AIフロンティアシリーズ:人材
私が初めて参加した「多業種のブレストセッション」から約3年が経ち、かつて野心的だと考えられていた機械学習の概念が、今では人事部門でも実現可能になっていることに驚かされています...

クロードAIに無料でアクセスする3つの方法
定期購読料なしで、主要な対話型AIモデルの1つを体験してください

中国の強力なNvidia AIチップの隠れた市場
深圳華強北電子區的繁華街道之中,一個高端 Nvidia AI 芯片的地下市場悄然興起。這個隱蔽的世界在出口限制和對這些尖端處理器的強烈需求中悄悄運作。在本文中,我們深入探究中國秘密貿易 Nvidia 芯片的有趣細節,揭示買家和賣家在政治緊張的背景下面臨的挑戰。 另外閱讀:NVIDIA 成為第一家市值萬億美元的 AI 芯片公司的企圖 SEG 大廈的秘密:揭示中國地下芯片市場 位於標誌性的 SEG 大廈中,前十層樓是一個電子商店的寶庫。供應商安靜地提供 Nvidia A100 人工智能芯片,這是一種極其受歡迎的產品。雖然不公開宣傳,但感興趣的買家可以通過悄悄的詢問找到這個難以捉摸的市場。 高昂的價格:獲得 Nvidia AI 芯片的高風險 獲得這些高端 Nvidia…

オッターに会いましょう:大規模データセット「MIMIC-IT」を活用した最先端のAIモデルであり、知覚と推論のベンチマークにおいて最新の性能を実現しています
マルチファセットモデルは、書かれた言語、写真、動画などの様々なソースからのデータを統合し、さまざまな機能を実行することを目指しています。これらのモデルは、視覚とテキストデータを融合させたコンテンツを理解し、生成することにおいて、かなりの可能性を示しています。 マルチファセットモデルの重要な構成要素は、ナチュラルランゲージの指示に基づいてモデルを微調整する指示チューニングです。これにより、モデルはユーザーの意図をより良く理解し、正確で適切な応答を生成することができます。指示チューニングは、GPT-2やGPT-3のような大規模言語モデル(LLMs)で効果的に使用され、実世界のタスクを達成するための指示に従うことができるようになりました。 マルチモーダルモデルの既存のアプローチは、システムデザインとエンドツーエンドのトレーニング可能なモデルの観点から分類することができます。システムデザインの観点では、ChatGPTのようなディスパッチスケジューラを使用して異なるモデルを接続しますが、トレーニングの柔軟性が欠けているため、コストがかかる可能性があります。エンドツーエンドのトレーニング可能なモデルの観点では、他のモダリティからモデルを統合しますが、トレーニングコストが高く、柔軟性が制限される可能性があります。以前のマルチモーダルモデルにおける指示チューニングのデータセットには、文脈に沿った例が欠けています。最近、シンガポールの研究チームが提案した新しいアプローチは、文脈に沿った指示チューニングを導入し、このギャップを埋めるための文脈を持つデータセットを構築しています。 この研究の主な貢献は以下の通りです。 マルチモーダルモデルにおける指示チューニングのためのMIMIC-ITデータセットの導入。 改良された指示に従う能力と文脈的学習能力を持ったオッターモデルの開発。 より使いやすいOpenFlamingoの最適化実装。 これらの貢献により、研究者には貴重なデータセット、改良されたモデル、そしてより使いやすいフレームワークが提供され、マルチモーダル研究を進めるための貴重な資源となっています。 具体的には、著者らはMIMIC-ITデータセットを導入し、OpenFlamingoの文脈的学習能力を維持しながら、指示理解能力を強化することを目的としています。データセットには、文脈的関係を持つ画像とテキストのペアが含まれており、OpenFlamingoは文脈的例に基づいてクエリされた画像-テキストペアのテキストを生成することを目指しています。MIMIC-ITデータセットは、OpenFlamingoの指示理解力を向上させながら、文脈的学習を維持するために導入されました。これには、画像-指示-回答の三つ組と対応する文脈が含まれます。OpenFlamingoは、画像と文脈的例に基づいてテキストを生成するためのフレームワークです。 トレーニング中、オッターモデルはOpenFlamingoのパラダイムに従い、事前学習済みのエンコーダーを凍結し、特定のモジュールを微調整しています。トレーニングデータは、画像、ユーザー指示、GPTによって生成された回答、および[endofchunk]トークンを含む特定の形式に従います。モデルは、クロスエントロピー損失を使用してトレーニングされます。著者らは、Please view this post in your web browser to complete the quiz.トークンで予測目標を区切ることにより、トレーニングデータを分離しています。 著者らは、OtterをHugging Face Transformersに統合し、研究者がモデルを最小限の努力で利用できるようにしました。彼らは、4×RTX-3090…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.