Learn more about Search Results Ford - Page 21

- You may be interested
- 需要予測のNixtlaへの紹介
- UCバークレーの研究者たちは、FastRLAPを...
- AWS CDKを介してAmazon SageMakerロールマ...
- この中国のAI研究は「Consistent4D」を紹...
- 「spaCyを使用したNLPパイプラインの強化」
- 「TikTokショップドロップシッピングでお...
- 「アメリカのトップ10のデータサイエンス...
- 「ビジネスインテリジェンスとは何ですか?」
- 「コントロールされたフェード」
- 「ジョンズホプキンスのこの論文は、時間...
- MuZeroの研究から現実世界への第一歩
- 「改善された推論のためのアナロジー提示...
- 世界のデータを処理できるアーキテクチャ...
- Rによるディープラーニング
- 「Web Speech API:何がうまく機能してい...

中国からの新しいAI研究が提案するSHIP:既存のファインチューニング手法を改善するためのプラグアンドプレイの生成AIアプローチ
この論文では、既存の微調整手法を改善するための SyntHesIzed Prompts (SHIP)という新しいアプローチについて取り上げています。 微調整:プレトレーニングの後、モデルはより小さなタスク固有のデータセットで微調整されます。これには新しいデータに対してトレーニングプロセスを継続することが含まれます。一般的な知識を特定のタスクに適用できるようにするために、プレトレーニングで獲得したモデルの知識を調整することが目的です。 研究者が取り組んでいる問題は、いくつかのクラスにデータがないシナリオです。彼らはクラス名を提供することで特徴を合成できる生成モデルをトレーニングすることを目指しました。これにより、データのないカテゴリの特徴を生成することが可能になります。 データのないカテゴリの特徴を生成するとは、トレーニングデータセットに存在しないクラスやカテゴリの表現を合成するプロセスを指します。これは、特定のクラスの実データを収集することが難しいまたは不可能なシナリオで特に有用です。 その後、研究者はオリジナルのラベル付きデータと新たに合成された特徴を使用してCLIPを微調整しました。しかし、生成モデルは通常、トレーニングに大量のデータを必要とするため、データの効率性とは相反する大きな障害です。彼らは、敵対的なトレーニングを必要とするモデルよりもトレーニングが容易で低データのシナリオで効果的な変分オートエンコーダ(VAE)をフレームワークとして利用することを提案しました。 GANとVAEは両方とも新しいデータサンプルを生成することができる生成モデルですが、アーキテクチャ、目標、トレーニング方法などが大きく異なります。GANは高品質でリアルなサンプルを生成する能力で知られていますが、トレーニングが難しい場合もあります。一方、VAEは確率的なフレームワークを提供し、特にデータが限られているシナリオでは取り扱いが容易ですが、GANほど鮮明またはリアルなサンプルを生成しないかもしれません。 CLIP(Contrastive Language–Image Pretraining)は、テキストの説明から画像を理解し生成するためのOpenAIによって開発されたモデルです。大規模なデータセットで事前トレーニングされ、視覚と言語の表現が整列しています。事前トレーニングされた言語エンコーダはよりリアルな特徴の生成を支援します。この論文は、合成データを利用してCLIPの微調整手法の性能を向上させることを目指して、ベースから新しい一般化、クロスデータセットの転移学習、および一般化されたゼロショット学習について包括的な実験を行い、最先端のパフォーマンスを達成しました。 提案されたモデルのアーキテクチャは、VAEフレームワークを利用して特徴をエンコードおよび生成し、CLIPを統合して画像特徴を抽出し再構築します。トレーニング中、モデルは特徴を潜在空間にエンコードし、それを再構築する方法を学習します。生成段階では、この学習されたエンコーディングを使用して新しいクラスの特徴を合成し、データのないクラスでもCLIPを微調整できるようにします。軽量なMLPと凍結されたCLIPテキストエンコーダからなる新しいCLIPベースのジェネレータは、潜在コードを変換し、特徴再構築用の最終的なプロンプトを構築する上で重要な役割を果たします。 研究者が観察した実験結果: ベースから新しい一般化:ImageNet、Caltech101、OxfordPets、StanfordCars、Flowers102、Food101、FGVCAircraft、SUN397、DTD、EuroSAT、UCF101を含む11の多様な画像分類データセットで実験が行われました。データセットはベースクラスと新しいクラスに分割され、ベースクラスでクラスごとに16のサンプルでトレーニングが行われました。評価はベースクラスと新しいクラスの両方で行われました。 一般化されたゼロショット設定:論文では、ベースから新しい一般化をより現実的な一般化されたゼロショット設定で評価しました。この設定では、ベースデータと新しいデータがテストデータセットで混在しています。結果は以前の手法では性能が著しく低下することを示しましたが、提案された方法であるSHIPは新しいクラスでの性能を改善し続けました。 他の手法との比較:CLIP、CoOp、CLIP-Adapter、Tip-Adapterなどの他の手法と比較されました。提案されたSHIP手法は、さまざまなデータセットで新たなクラスでの性能を向上させました。 結論: この論文では、既存のファインチューニング手法を改善するために、新しいSyntHesIzed Prompts (SHIP)アプローチを提案しました。特に一部のクラスにデータがないシナリオで、この手法はさまざまなタスクで最先端のパフォーマンスを達成しました。データのないカテゴリに対して特徴を合成し、元のラベル付き特徴と新たに合成された特徴の両方を使用してCLIPをファインチューニングすることで、この手法は優れた結果を得ることができました。論文は、追加のトレーニングコストを制約として認識し、将来の研究でSHIPの密な予測タスクへの適用可能性を探求する意図を表明しています。 全体として、この論文は、特定のクラスのデータの不足の課題に対処し、合成データを使用してCLIPのファインチューニング手法のパフォーマンスを向上させるという点で、この分野への重要な貢献を示しています。
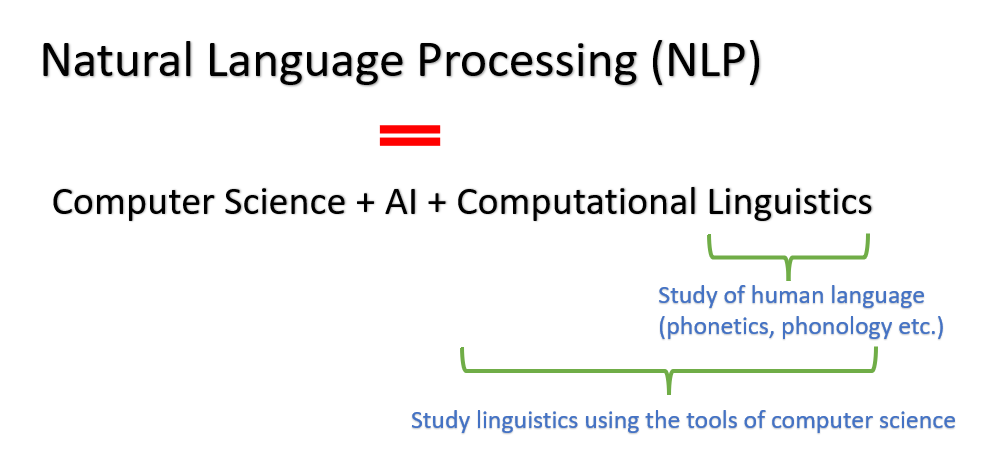
NLPの探索 – NLPのキックスタート(ステップ#1)
今学期、私はカリキュラムの一部としてNLPを受講していますやったー!さて、この科目の今後の評価の一環として、与えられた教材を復習し、いくつかのノートを作成しましたそれが私がすることです...

NLPの探求 – NLPのキックスタート(ステップ#3)
「以下は、特に単語の埋め込みについて、私が週間で学んだいくつかの概念です実際に手を動かして試してみましたので、その一部を近々シリーズとして共有します!ここで、サチン氏に感謝を述べたいと思います...」

「5つのオンラインAI認定プログラム – 研究と登録」
「世界的に認められたAIの認定コースを受講し、AIのスキルを身につけ、複数の人工知能の仕事に応募できる資格を取得しましょうChatGPTから自律型まで、AIを活用することによって…」

スタンフォード大学の研究者たちは、「ギスティング:言語モデルにおける効率的なプロンプト圧縮のための新しい技術」というものを紹介しました
モデルの特殊化は、事前に学習された機械学習モデルを特定のタスクやドメインに適応させることを意味します。言語モデル(LM)では、モデルの特殊化は、要約、質問応答、翻訳、言語生成など、さまざまなタスクでのパフォーマンス向上に重要です。言語モデルを特定のタスクに特殊化するための2つの主なプロセスは、命令の微調整(事前に学習されたモデルを新しいタスクまたは一連のタスクに適応させること)とモデルの蒸留(事前に学習された「教師」モデルから小型の特殊化された「学生」モデルに知識を転送すること)です。プロンプティングは、LMの特殊化の分野で重要な概念であり、特定の動作にモデルを誘導する方法を提供し、限られたトレーニングデータのより効率的な使用を可能にし、最先端のパフォーマンスを実現するために重要です。プロンプトの圧縮は、計算、メモリ、ストレージの大幅な節約と、出力の全体的なパフォーマンスや品質の実質的な低下をもたらすことを目指して研究されている手法です。 この論文は、スタンフォード大学の研究者によって発表されたもので、プロンプトの圧縮のための新しい手法である「gisting」を提案しています。これは、LMを訓練してプロンプトをより小さな「gist」トークンのセットに圧縮する方法です。プロンプトのコストを削減するためには、微調整や蒸留のような技術を使用して、プロンプトなしで元のモデルと同じように振る舞うモデルを訓練することができますが、その場合、モデルは新しいプロンプトごとに再訓練する必要があり、理想的な状況からはほど遠いです。一方、gistingのアイデアは、メタ学習のアプローチを使用してプロンプトからgistトークンを予測することで、タスクごとにモデルを再訓練することなく、未知の命令に対しても汎化させることができます。これにより、計算コストが削減され、プロンプトを圧縮してキャッシュ化し、計算効率を向上させることができます。また、限られたコンテキストウィンドウにより多くのコンテンツを収めることも可能になります。 著者たちは、このようなモデルを実現するための簡単な方法を試みました。彼らはLM自体(その事前の知識を活用)を使用して、命令の微調整中にgistトークンを予測し、Transformerのアテンションマスクを修正しました。タスクと入力のペアが与えられた場合、彼らはタスクと入力の間にgistトークンを追加し、アテンションマスクを次のように設定しました:gistトークンの後の入力トークンは、gistトークンの前のプロンプトトークンのいずれにもアテンションを向けることができません(ただし、gistトークンにはアテンションを向けることができます)。入力と出力がプロンプトにアテンションを向けることができないため、モデルはプロンプトの情報をgistトークンに圧縮する必要があります。gistモデルを訓練するためには、さまざまなタスクの多様なデータセットが必要でしたので、彼らはAlpaca+と呼ばれるデータセットを作成しました。これは、2つの既存の命令微調整データセット(Standford AlpacaとSelf-Instruct)のデータを組み合わせたもので、合計で13万以上の例が含まれています。その後、トレーニング後にモデルを検証するために3つのバリデーションスプリット(Seen、Unseen、手作りのHuman prompts)を保持しました。これにより、未知の命令に対する汎化性能をテストすることができました。Human splitは、さらに強力な汎化の課題を提供します。また、複数のLMアーキテクチャ(具体的にはLLaMA-7Bm、デコーダのみのGPTスタイルのモデル、およびFLAN-T5-XXL)を使用し、gistトークンの数(1、2、5、または10)を変えながらgistモデルを訓練しました。しかし、結果は、モデルが一般にgistトークンの数に対して敏感でなく、場合によっては、トークンの数が多いほうがパフォーマンスに悪影響を及ぼすことさえ示していました。したがって、残りの実験には単一のgistモデルを使用しました。 プロンプトの圧縮の品質を評価するために、彼らは陽性コントロールとしてのパフォーマンスを調整し、効果的に標準的な命令微調整を提供し、パフォーマンスの上限を示しました。また、モデルが命令にアクセスできず、ランダムなgistトークンが生成されるネガティブコントロールも使用し、パフォーマンスの下限を示しました。彼らは、モデルの出力を陽性コントロールと比較し、その勝率を測定するためにChatGPTによってどちらの応答がより良いかを選択させ、その理由を説明しました。また、単純な語彙の重複統計であるROUGE-L(オープンエンドの命令微調整で生成されたテキストと人間が書いた命令の類似性を測定する指標)も使用しました。50%の勝率は、プロンプトの圧縮を行わないモデルと同等の品質のモデルであることを示します。 結果は、Seenの指示では、要約モデルが陽性対照モデルに非常に近い勝率を持っていることを示しました。LLaMAは48.6%、FLAN-T5は50.8%の勝率です。さらに重要なことに、要約モデルは未知のプロンプトに対しても競争力のある一般化を示すことができました。LLaMAは49.7%、FLAN-T5は46.2%の勝率です。最も難しいHuman splitでは、わずかな勝率の低下が見られましたが(それでも競争力があります)、LLaMAは45.8%、FLAN-T5は42.5%の勝率です。FLAN-T5のわずかに悪い性能と特定の失敗事例は、将来の論文でさらに検証すべき仮説をもたらしました。 研究者たちはまた、研究の主な動機である要約によって実現できる潜在的な効率の向上も調査しました。その結果は非常に励みになりました。要約キャッシングによってFLOPsが40%削減され、最適化されていないモデルと比較して壁時計時間が4-7%低下しました。これらの改善は、デコーダのみの言語モデルでは小さいとわかりましたが、研究者たちはまた、要約モデルによって未知のプロンプトを26倍圧縮できることを示しました。これにより、入力コンテキストウィンドウにかなりの追加スペースが提供されます。 全体的に、これらの結果は、要約が専門的な言語モデルの有効性と効率を向上させるための大きな潜在能力を示しています。著者たちはまた、要約に関する追加の研究のためのいくつかの有望な方向性を提案しています。例えば、要約から最も大きな計算および効率の利益は、より長いプロンプトの圧縮から得られると述べており、「要約の事前学習」は、まず自然言語の任意の範囲を圧縮することを学習してからプロンプトの圧縮を改善することができると示唆しています。

「ICML 2023でのGoogle」
Cat Armatoさんによる投稿、Googleのプログラムマネージャー Googleは、言語、音楽、視覚処理、アルゴリズム開発などの領域で、機械学習(ML)の研究に積極的に取り組んでいます。私たちはMLシステムを構築し、言語、音楽、視覚処理、アルゴリズム開発など、さまざまな分野の深い科学的および技術的な課題を解決しています。私たちは、ツールやデータセットのオープンソース化、研究成果の公開、学会への積極的な参加を通じて、より協力的なエコシステムを広範なML研究コミュニティと構築することを目指しています。 Googleは、40回目の国際機械学習会議(ICML 2023)のダイヤモンドスポンサーとして誇りに思っています。この年次の一流学会は、この週にハワイのホノルルで開催されています。ML研究のリーダーであるGoogleは、今年の学会で120以上の採択論文を持ち、ワークショップやチュートリアルに積極的に参加しています。Googleは、LatinX in AIとWomen in Machine Learningの両ワークショップのプラチナスポンサーでもあることを誇りに思っています。私たちは、広範なML研究コミュニティとのパートナーシップを拡大し、私たちの幅広いML研究の一部を共有することを楽しみにしています。 ICML 2023に登録しましたか? 私たちは、Googleブースを訪れて、この分野で最も興味深い課題の一部を解決するために行われるエキサイティングな取り組み、創造性、楽しさについてさらに詳しく知ることを願っています。 GoogleAIのTwitterアカウントを訪れて、Googleブースの活動(デモやQ&Aセッションなど)について詳しく知ることができます。Google DeepMindのブログでは、ICML 2023での技術的な活動について学ぶことができます。 以下をご覧いただき、ICML 2023で発表されるGoogleの研究についてさらに詳しくお知りください(Googleの関連性は太字で表示されます)。 理事会および組織委員会 理事会メンバーには、Corinna Cortes、Hugo Larochelleが含まれます。チュートリアルの議長には、Hanie Sedghiが含まれます。 Google…

「AIが異星生命を探す訓練を受けています」
「氷の海の月から、一方が永遠の夜である惑星まで、ゴールディロックスゾーンには数え切れないほどの奇妙な世界が存在します - 理論上、宇宙人が進化する可能性がある領域です宇宙での生命の探求は、長い間人間の想像力を魅了してきました今や、コンピュータの助けを借りれば、科学者たちはこれまで以上に成功する可能性があります...」
このAIニュースレターは、あなたが必要とするすべてです #57
「AIの世界では、LLMモデルのパフォーマンス評価が注目の話題となりました特に、スタンフォードとバークレーの学生による最近の研究についての活発な議論がありました...」

スタンフォード大学の研究者が「局所的に条件付けられた拡散(Locally Conditioned Diffusion):拡散モデルを使用した構成的なテキストから画像への生成手法」を紹介しました
3Dシーンモデリングは従来、特定の知識を持つ人々に限られた時間のかかる手続きでした。パブリックドメインには多くの3D素材がありますが、ユーザーの要件に合う3Dシーンを見つけることは珍しいです。そのため、3Dデザイナーは個々の3Dオブジェクトをモデリングし、シーンに組み立てるために数時間または数日を費やすことがあります。3Dの作成を簡単にし、同時にその構成要素を制御できるようにすることは、経験豊富な3Dデザイナーと一般の人々(例:個々のオブジェクトのサイズと位置)とのギャップを埋めるのに役立ちます。 最近、3Dシーンモデリングのアクセシビリティが改善されました。3D生成モデルに取り組むことで、3Dオブジェクトの合成において有望な結果が得られています。3Daware生成対抗ネットワーク(GAN)を使用して3Dオブジェクトの合成に関する有望な結果が得られており、作成されたアイテムをシーンに組み合わせるための第一歩となっています。しかし、GANは特定のアイテムカテゴリに特化しており、結果のバラエティが制限され、シーンレベルのテキストから3Dへの変換が困難です。これに対し、拡散モデルを使用したテキストから3Dへの生成は、さまざまなカテゴリの3Dオブジェクトの作成を促すことができます。 現在の研究では、異なる可能なシーン表現の描画ビューにグローバルな条件付けを課すために、インターネットスケールのデータで学習された堅牢な2Dイメージ拡散事前分布を使用して、単語のプロンプトを使用しています。これらの手法は、優れたオブジェクト中心の生成物を生み出すことができますが、複数のユニークな特徴を持つシーンを生成するためには支援が必要です。グローバルな条件付けは、ユーザー入力が単一のテキストプロンプトに制限され、作成されたシーンのデザインに影響を与える方法がないため、制御性を制限します。Stanfordの研究者は、局所的な条件付き拡散と呼ばれる拡散モデルを使用した構成的なテキストからイメージへの生成手法を提供しています。 彼らの提案手法は、テキストプロンプトと3Dバウンディングボックスを入力として使用し、個々のオブジェクトのサイズと位置を制御しながら、一貫性のある3Dセットを構築します。彼らのアプローチでは、入力セグメンテーションマスクと一致するテキストプロンプトを使用して特定の部分の画像に条件付き拡散ステージを選択的に適用し、ユーザー指定の構成に従って出力を生成します。スコア蒸留サンプリングに基づくテキストから3D生成パイプラインに彼らの手法を組み込むことで、彼らは構成的なテキストから3Dシーンを作成することもできます。 彼らは具体的に以下の貢献を提供しています: • 2D拡散モデルにより構成的な柔軟性を持たせる局所的な条件付け拡散を提案します。 • 構成的な3D生成に不可欠な重要なカメラの姿勢サンプリング手法を提案します。 • スコア蒸留サンプリングベースの3D生成パイプラインに局所的な条件付け拡散を追加することで、構成的な3D合成の手法を紹介します。

「巨大なコンピュータチップによって駆動されるA.I.スーパーコンピュータが稼働し始める」
新しいスーパーコンピュータは、シリコンバレーのスタートアップ企業Cerebrasによって作られ、A.I.ブームに伴うチップと計算能力の需要を受けて公開されました
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.