Learn more about Search Results Descript - Page 21

- You may be interested
- OpenAIはGPT-4をターボチャージしています...
- スタンフォード大学とMilaの研究者は、多...
- 「世界最小のデータパイプラインフレーム...
- 「最高のAIプレゼンテーション生成ツール1...
- 「夢を先に見て、後で学ぶ:DECKARDは強化...
- 「初心者におすすめの副業5選(無料のコー...
- 科学ソフトウェアの開発
- VoAGIニュース、7月12日:ChatGPTに関する...
- データモデリング入門、パート1:データモ...
- Huggingface TransformersとRayを使用した...
- 「Pandas 2.1の新機能」
- 製造品の品質におけるコンピュータビジョ...
- 「科学者がスーパーバグと戦うため、分子...
- 「GPT-4は数学の問題を解くことができます...
- 「Cheetorと会ってください:幅広い種類の...

シエラディビジョンは、NVIDIA Omniverseを使用して作成された3つの壮大なプロジェクトを発表します
編集者の注:この投稿は、私たちの週刊「NVIDIA Studio」シリーズの一部であり、注目のアーティストを称え、クリエイティブなヒントやトリックを提供し、NVIDIA Studioテクノロジーがクリエイティブなワークフローを改善する方法を実証しています。また、新しいGeForce RTX 40シリーズGPUの機能、技術、リソースについて詳しく説明し、それらがコンテンツの作成を劇的に加速する方法についても深く掘り下げます。 Jacob Norrisは、3Dアーティストであり、Sierra Division Studiosの社長、共同創設者、クリエイティブディレクターでもあります。Sierra Division Studiosは、デジタル3Dコンテンツの制作に特化した外注スタジオです。このスタジオは、最高レベルで画期的なアートワークを作り出すことを目標に設立されました。 彼のチームは完全にリモートで働いており、従業員にはどこからでも働く柔軟性があります。これにより、スタジオが利用できる経験やスキルセットの広範な範囲を持つ見込みのアーティストのプールが増えます。 ノリスは、場所や時間、さらには言語に関係なく、信じられないほどの3Dコンテンツが作成される未来を想像しています。これは、カスタムな3Dツールやメタバースアプリケーションを接続および構築するためのプラットフォームであるNVIDIA Omniverseが重要な役割を果たす未来です。 Omniverseは、SimReadyアセットの作成にも強力なツールです。SimReadyアセットとは、正確な物理的特性を持つ3Dオブジェクトのことです。これらのアセットは、合成データと組み合わせることで、AIを搭載した3Dアーティストのためのシミュレーションを含む現実世界の問題の解決に役立ちます。NVIDIA Studioのクリエイティブな一面の副業ページで、AIについての詳細を学び、情熱的なプロジェクトのレベルアップに役立つクリエイティブリソースにアクセスしてください。 さらに、新しいコミュニティチャレンジ「#StartToFinish」もチェックしてください。このハッシュタグを使用して、お気に入りのプロジェクトの始まりと終わりのステージを示すスクリーンショットを投稿し、@NVIDIAStudioと@NVIDIAOmniverseのソーシャルチャンネルで紹介されるチャンスを得ることができます。 新しい「#StartToFinish」チャレンジへようこそ。 アートプロジェクトの始まりと最終結果の写真/ビデオを表示して、#StartToFinishをタグ付けして参加してください。 次は、@rafianimatesが@NVIDIAOmniverseで#OpenUSDを使用して作成した素晴らしい例です。 pic.twitter.com/z9v656oQ2Q — NVIDIA Studio…

「The Reformer – 言語モデリングの限界を押し上げる」
Reformerが半ミリオントークンのシーケンスを訓練するために8GB未満のRAMを使用する方法 Reformerモデルは、Kitaev、Kaiserらによって2020年に紹介されたもので、現在のところ最もメモリ効率の良いトランスフォーマーモデルの1つです。 最近、長いシーケンスモデリングは大きな関心を集めており、今年だけでも多くの論文が提出されています(Beltagyら(2020年)、Royら(2020年)、Tayら、Wangらなど)。長いシーケンスモデリングの背後にある動機は、要約、質問応答などの多くのNLPタスクが、BERTなどのモデルよりも長い入力シーケンスを処理する必要があるということです。大きな入力シーケンスを処理する必要があるタスクでは、長いシーケンスモデルはメモリオーバーフローを避けるために入力シーケンスを切り詰める必要がなく、従って標準の「BERT」のようなモデルを上回る性能を示すことが示されています(Beltagyら(2020年)による)。 Reformerは、このデモに示されているように、一度に最大で半ミリオンのトークンを処理する能力により、長いシーケンスモデリングの限界を em em ます。比較のために、従来の bert-base-uncased モデルでは、入力の長さを512トークンに制限しています。Reformerでは、標準のトランスフォーマーアーキテクチャの各部分が最小限のメモリ要件を最適化するために再設計されており、性能の大幅な低下を伴わずにメモリの改善がなされています。 メモリの改善は、Reformerの作者がトランスフォーマーワールドに導入した4つの特徴に帰属できます: Reformer Self-Attention Layer – ローカルコンテキストに制限されることなく自己注意を効率的に実装する方法は? Chunked Feed Forward Layers – 大規模なフォワードレイヤーの時間とメモリのトレードオフを改善する方法は? Reversible Residual Layers…

Amazon SageMakerを使用して、Hugging Faceモデルを簡単にデプロイできます
今年早くも、Hugging FaceをAmazon SageMakerで利用しやすくするためにAmazonとの戦略的な協力を発表し、最先端の機械学習機能をより速く提供することを目指しています。新しいHugging Face Deep Learning Containers (DLCs)を導入し、Amazon SageMakerでHugging Face Transformerモデルをトレーニングすることができます。 今日は、Amazon SageMakerでHugging Face Transformersを展開するための新しい推論ソリューションを紹介します!新しいHugging Face Inference DLCsを使用すると、トレーニング済みモデルをわずか1行のコードで展開できます。また、Model Hubから10,000以上の公開モデルを選択し、Amazon SageMakerで展開することもできます。 SageMakerでモデルを展開することで、AWS環境内で簡単にスケーリング可能な本番用エンドポイントが提供されます。モニタリング機能やエンタープライズ向けの機能も組み込まれています。この素晴らしい協力を活用していただければ幸いです! 以下は、新しいSageMaker Hugging Face…

Gradioを使用して、Spacesで自分のプロジェクトをショーケースしましょう
Gradioを利用することで、機械学習プロジェクトを簡単にデモンストレーションすることができます。 このブログ記事では、以下の内容について説明します: 最近のGradioの統合により、Inference APIを活用してHubからモデルをシームレスにデモンストレーションする方法 Hugging Face Spacesを使用して、独自のモデルのデモをホストする方法 GradioでのHugging Face Hub統合 Hubでモデルを簡単にデモンストレーションすることができます。以下を含むインターフェースを定義するだけでOKです: 推論を行いたいモデルのリポジトリID 説明とタイトル オーディエンスをガイドするための入力例 インターフェースを定義したら、.launch()を呼び出すだけでデモが開始されます。これはColabで行うこともできますが、コミュニティと共有する場合はSpacesを使用するのがおすすめです! SpacesはPythonでMLデモアプリを簡単にホストするための無料の方法です。Spacesを使用するには、https://huggingface.co/new-space にリポジトリを作成し、SDKとしてGradioを選択します。作業が完了すると、app.pyというファイルを作成し、下のコードをコピーするだけで、数秒でアプリを起動できます! import gradio as gr description = "GPT-2によるストーリー生成"…
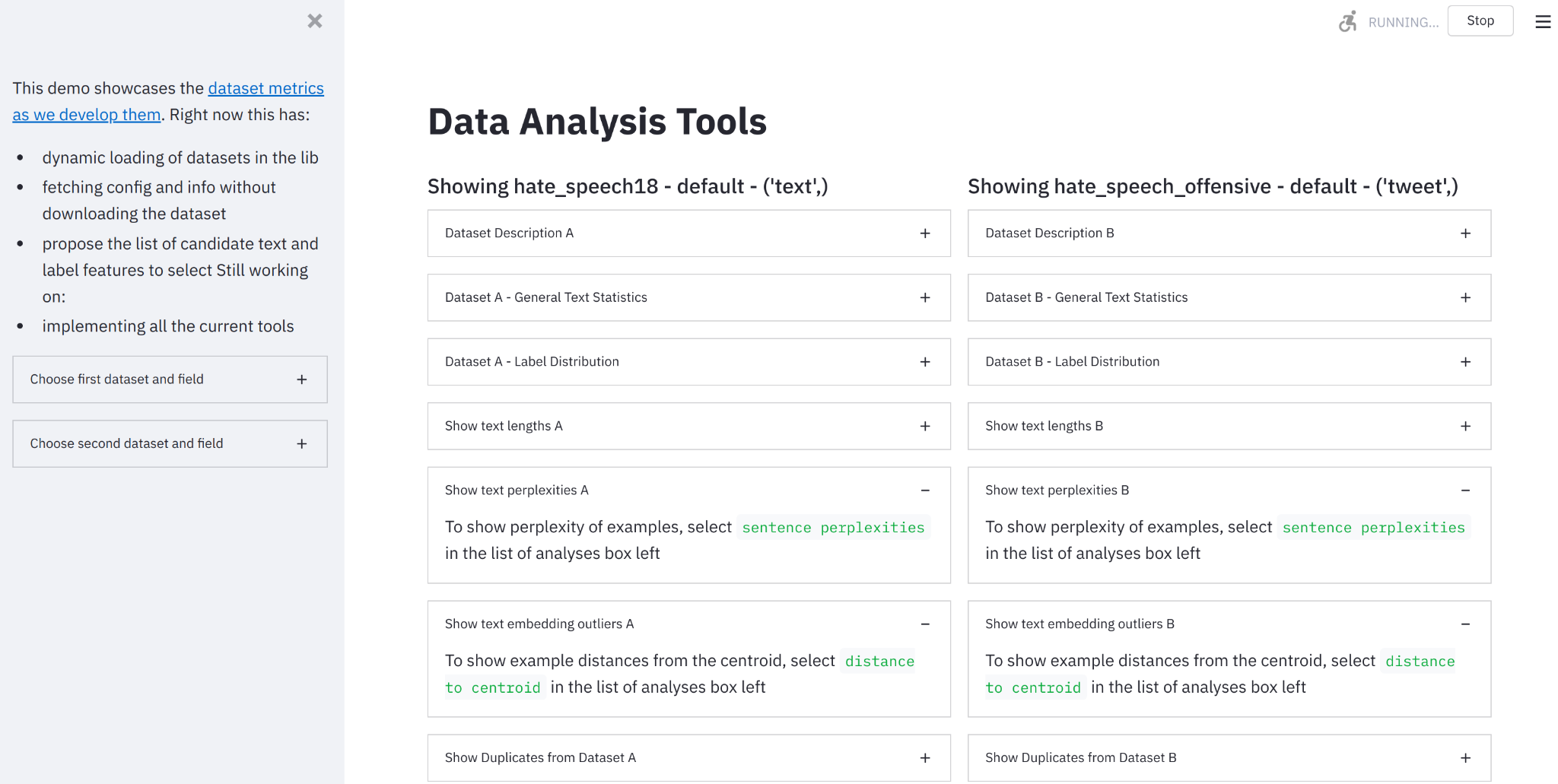
データ測定ツールのご紹介:データセットを見るためのインタラクティブツール
要約:データセットを構築し、測定し、比較するためのオンラインツールを作成しました。 🤗データ計測ツールにアクセスするには、ここをクリックしてください。 機械学習データセットの急成長する統一リポジトリの開発者として(Lhoest et al. 2021)、🤗Hugging Faceチームはデータセットのドキュメント化のための良い実践をサポートするために取り組んできました(McMillan-Major et al. 2021)。静的(進化する可能性のある)ドキュメントはこの方向性への必要な第一歩を表しますが、データセットの実際の内容を理解するには、動機付けのある計測とそれに対する対話的な可視化能力が必要です。 そのため、私たちはオープンソースのPythonライブラリとノーコードインターフェースである🤗データ計測ツールを紹介します。これは、私たちのデータセットとSpaces Hubsを使用して、優れたStreamlitツールと組み合わせて、データセットの理解、構築、キュレーション、比較を支援するために使用することができます。 🤗データ計測ツールとは何ですか? データ計測ツール(DMT)は、データセットの作成者やユーザーが責任あるデータ開発のために有意義で役立つメトリクスを自動的に計算できるインタラクティブなインターフェースおよびオープンソースライブラリです。 なぜこのツールを作成したのですか? 機械学習データセットの綿密なキュレーションと分析は、AIの開発においてしばしば見落とされています。AIにおける「ビッグデータ」の現在の標準(Luccioni et al. 2021, Dodge et al. 2021)は、さまざまなウェブサイトから収集されたデータを使用しており、異なるデータソースが具体的に何を表しているか、それらがモデルの学習にどのように影響するかについてはほとんど注意が払われていません。データセットの注釈手法は、開発者の目標に合ったデータセットのキュレーションに役立つことがありますが、これらのデータセットのさまざまな側面を「測定する」ための手法はかなり限られています(Sambasivan et…

KiliとHuggingFace AutoTrainを使用した意見分類
イントロダクション ユーザーのニーズを理解することは、ユーザーに関連するビジネスにおいて重要です。しかし、それには多くの労力と分析が必要であり、非常に高価です。ならば、Machine Learningを活用しませんか?Auto MLを使用することでコーディングを大幅に削減できます。 この記事では、HuggingFace AutoTrainとKiliを活用して、テキスト分類のためのアクティブラーニングパイプラインを構築します。Kiliは、品質の高いトレーニングデータ作成を通じて、データ中心のアプローチを強力にサポートするプラットフォームです。協力的なデータ注釈ツールとAPIを提供し、信頼性のあるデータセット構築とモデルトレーニングの素早い反復を可能にします。アクティブラーニングとは、データセットにラベル付けされたデータを追加し、モデルを反復的に再トレーニングするプロセスです。そのため、終わりのない作業であり、人間がデータにラベルを付ける必要があります。 この記事の具体的なユースケースとして、Google PlayストアのVoAGIのユーザーレビューを使用してパイプラインを構築します。その後、構築したパイプラインでレビューをカテゴリ分類します。最後に、分類されたレビューに感情分析を適用します。その結果を分析することで、ユーザーのニーズと満足度を理解することが容易になります。 HuggingFaceを使用したAutoTrain 自動化されたMachine Learningは、Machine Learningパイプラインの自動化を指す用語です。データクリーニング、モデル選択、ハイパーパラメータの最適化も含まれます。🤗 transformersを使用して自動的にハイパーパラメータの検索を行うことができます。ハイパーパラメータの最適化は困難で時間のかかるプロセスです。 transformersや他の強力なAPIを使用してパイプラインを自分自身で構築することもできますが、AutoTrainを完全に自動化することも可能です。AutoTrainは、transformers、datasets、inference-apiなどの多くの強力なAPIを基に構築されています。 データのクリーニング、モデルの選択、ハイパーパラメータの最適化のステップは、すべてAutoTrainで完全に自動化されています。このフレームワークをフルに活用することで、特定のタスクに対してプロダクションレディのSOTAトランスフォーマーモデルを構築することができます。現在、AutoTrainはバイナリとマルチラベルのテキスト分類、トークン分類、抽出型質問応答、テキスト要約、テキストスコアリングをサポートしています。また、英語、ドイツ語、フランス語、スペイン語、フィンランド語、スウェーデン語、ヒンディー語、オランダ語など、多くの言語もサポートしています。AutoTrainでサポートされていない言語の場合、カスタムモデルとカスタムトークナイザを使用することも可能です。 Kili Kiliは、データ中心のビジネス向けのエンドツーエンドのAIトレーニングプラットフォームです。Kiliは、最適化されたラベリング機能と品質管理ツールを提供し、データを管理するための便利な手段を提供します。画像、ビデオ、テキスト、PDF、音声データを素早く注釈付けできます。GraphQLとPythonの強力なAPIも備えており、データ管理を容易にします。 オンラインまたはオンプレミスで利用可能であり、コンピュータビジョンやNLP、OCRにおいてモダンなMachine Learning技術を実現することができます。テキスト分類、固有表現認識(NER)、関係抽出などのNLP / OCRタスクをサポートしています。また、オブジェクト検出、画像転写、ビデオ分類、セマンティックセグメンテーションなどのコンピュータビジョンタスクもサポートしています。 Kiliは商用ツールですが、Kiliのツールを試すために無料のデベロッパーアカウントを作成することもできます。料金については、価格ページから詳細を確認できます。 プロジェクト モバイルアプリケーションについての洞察を得るために、レビューの分類と感情分析の例を取り上げます。…

Skopsの紹介
Skopsの紹介 Hugging Faceでは、オープンソースの機械学習に関するさまざまな問題に取り組んでおり、モデルの安全なホスティングや公開、再現性、説明可能性、コラボレーションなどを可能にしています。私たちは、新しいライブラリ「Skops」をご紹介できることを大変嬉しく思っています!Skopsを使用すると、scikit-learnモデルをHugging Face Hubにホストしたり、モデルのドキュメント用のモデルカードを作成したり、他の人と共同作業したりすることができます。 まず、モデルをトレーニングしてから、Skopsを使用してステップバイステップでsklearnを本番環境で活用する方法を見ていきましょう。 # ライブラリをインポートしましょう import sklearn from sklearn.datasets import load_breast_cancer from sklearn.tree import DecisionTreeClassifier from sklearn.model_selection import train_test_split # データをロードして分割します…

マルチリンガルASRのためのWhisperの調整を行います with 🤗 Transformers
このブログでは、ハギングフェイス🤗トランスフォーマーを使用して、Whisperを任意の多言語ASRデータセットに対して細かく調整する手順を段階的に説明します。このブログでは、Whisperモデル、Common Voiceデータセット、および細かな調整の背後にある理論について詳しく説明し、データの準備と細かい調整の手順を実行するためのコードセルと共に提供しています。説明は少ないですが、すべてのコードがあるより簡略化されたバージョンのノートブックは、関連するGoogle Colabを参照してください。 目次 はじめに Google ColabでのWhisperの細かい調整 環境の準備 データセットの読み込み 特徴抽出器、トークナイザー、およびデータの準備 トレーニングと評価 デモの作成 締めくくり はじめに Whisperは、OpenAIのAlec Radfordらによって2022年9月に発表された自動音声認識(ASR)のための事前学習モデルです。Whisperは、Wav2Vec 2.0などの先行研究とは異なり、ラベル付きの音声トランスクリプションデータで事前学習されています。具体的には、680,000時間のデータが使用されています。これは、Wav2Vec 2.0の訓練に使用されるラベルなしの音声データ(60,000時間)よりも桁違いに多いデータです。さらに、この事前学習データのうち117,000時間が多言語ASRデータです。これにより、96以上の言語に適用できるチェックポイントが生成され、その多くは低リソース言語とされています。 このような大量のラベル付きデータにより、Whisperは事前学習データから音声認識の教師ありタスクを直接学習し、音声トランスクリプションデータからテキストへのマッピングを学習します。そのため、Whisperはパフォーマンスの高いASRモデルを得るためにほとんど追加の細かい調整を必要としません。これに対して、Wav2Vec 2.0は非教師付きタスクのマスク予測で事前学習されており、音声から隠れた状態への中間的なマッピングを学習します。非教師付きの事前学習は音声の高品質な表現を生み出しますが、音声からテキストへのマッピングは学習されません。このマッピングは細かい調整中にのみ学習されるため、競争力のあるパフォーマンスを得るにはより多くの細かい調整が必要です。 680,000時間のラベル付き事前学習データにスケールされると、Whisperモデルは多くのデータセットとドメインに対して高い汎化能力を示します。事前学習されたチェックポイントは、LibriSpeech ASRのtest-cleanサブセットで約3%の単語エラーレート(WER)を達成し、TED-LIUMでは4.7%のWERで新たな最先端の結果を実現します(Whisper論文の表8を参照)。Whisperが事前学習中に獲得した多言語ASRの知識は、他の低リソース言語に活用することができます。細かい調整により、事前学習済みのチェックポイントを特定のデータセットと言語に適応させることで、これらの結果をさらに改善することができます。 Whisperは、Transformerベースのエンコーダーデコーダーモデルであり、シーケンスからシーケンスへのモデルとも呼ばれています。Whisperは、オーディオのスペクトログラム特徴のシーケンスをテキストトークンのシーケンスにマッピングします。まず、生のオーディオ入力は特徴抽出器によってログメルスペクトログラムに変換されます。次に、Transformerエンコーダーはスペクトログラムをエンコードしてエンコーダーの隠れ状態のシーケンスを形成します。最後に、デコーダーはエンコーダーの隠れ状態と以前に予測されたトークンの両方に依存して、テキストトークンを自己回帰的に予測します。図1はWhisperモデルを要約しています。 <img…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

ビジョン言語モデルの高速化:Habana Gaudi2上のBridgeTower
Optimum Habana v1.6 on Habana Gaudi2 では、最新のビジョン言語モデルである BridgeTower のファインチューニングにおいて、A100 と比較してほぼ3倍の高速化を実現しています。ハードウェアアクセラレーションによるデータの読み込みと高速な DDP 実装の2つの新機能がパフォーマンス向上に寄与しています。 これらの技術は、データの読み込みに制約がある他のワークロードにも適用できます。これは、さまざまなタイプのビジョンモデルに頻繁に起こるケースです。この投稿では、BridgeTower のファインチューニングを Habana Gaudi2 と Nvidia A100 80GB で比較するために使用したプロセスとベンチマークを紹介します。また、トランスフォーマーベースのモデルでこれらの機能を簡単に活用する方法も示します。 BridgeTower 最近のビジョン言語(VL)モデルは、さまざまなVLタスクで非常に重要であり、優位性を示しています。最も一般的なアプローチは、それぞれのモダリティから表現を抽出するためにユニモーダルエンコーダを利用することです。その後、これらの表現は融合されるか、クロスモーダルエンコーダに供給されます。VL表現学習のパフォーマンス制約と制限を効果的に扱うために、BridgeTower は複数のブリッジ層を導入し、ユニモーダルエンコーダのトップ層とクロスモーダルエンコーダの各層との間に接続を構築します。これにより、クロスモーダルエンコーダ内の異なる意味レベルで視覚とテキストの表現の効果的なボトムアップのクロスモーダルの整合性と融合が可能になります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.