Learn more about Search Results - Page 21

- You may be interested
- MicrosoftエンジニアのAIイノベーションと...
- Amazon Lexのチャットボット開発ライフサ...
- 男性がテック業界の女性向けジョブフェア...
- Active Directoryグループ固有のIAMロール...
- 「AI Time Journalが「AIにおけるSEOのト...
- 「パブリックスピーキングのための5つの最...
- LinkedInのフィード進化:より詳細かつパ...
- 「SaaS AIの機能が堀や障壁なしでアプリケ...
- ピカ1.0:ビデオ作成のための新しいAIモデル
- 「ONNXフレームワークによるモデルの相互...
- ディープシークLLM:中国の最新の言語モデル
- 米政府機関がグローバルサイバー攻撃を受ける
- 「30/10から5/11までの週のトップ重要なコ...
- ChatGPTのようなChatBot Zhinaoは、何を言...
- 最近の人類学的研究によれば、クロード2.1...

Swift 🧨ディフューザー – Mac用の高速安定拡散
Diffusers for Macを使用して、最新の拡散モデルによってテキストを美しい画像に簡単に変換できます。このネイティブアプリは、Hugging Face Hubへのコミュニティの貢献によって提供された最先端のテキストから画像へのモデルを活用し、高速なパフォーマンスのためにCore MLに変換されています。最新バージョンの1.1は、Mac App Storeで利用可能であり、パフォーマンスの大幅なアップグレードと使いやすいインターフェースの調整が行われています。これは将来の機能アップデートのための堅牢な基盤となっています。さらに、このアプリは完全にオープンソースであり、許容されるライセンスであるため、あなた自身でも構築することができます!詳細については、https://github.com/huggingface/swift-coreml-diffusers でGitHubリポジトリをご覧ください。 Diffusers for Macとは具体的には何ですか? Diffusersアプリ(App Store、ソースコード)は、Mac版の 🧨 diffusers ライブラリの対応アプリです。このライブラリはPythonとPyTorchで書かれており、モジュラーな設計を使用して拡散モデルのトレーニングと実行を行います。多くの異なるモデルとタスクをサポートし、高度に構成可能で最適化されています。Macでも実行できます。Apple Siliconでは、PyTorchの mps アクセラレータを使用します。 では、なぜネイティブのMacアプリを実行したいのでしょうか?その理由はいくつかあります: オリジナルのPyTorchモデルではなく、Core MLモデルを使用します。これは、Appleハードウェアの特定の最適化に対応する追加の最適化を可能にし、Core MLモデルはシステム内のすべての計算デバイス(CPU、GPU、ニューラルエンジン)で実行できます。PyTorchの…

制御ネット(ControlNet)は、🧨ディフューザー内での使用です
Stable Diffusionが世界中で大流行した以来、人々は生成プロセスの結果に対してより多くの制御を持つ方法を探してきました。ControlNetは、ユーザーが生成プロセスを非常に大きな範囲でカスタマイズできる最小限のインターフェースを提供します。ControlNetを使用すると、ユーザーは深度マップ、セグメンテーションマップ、スクリブル、キーポイントなど、さまざまな空間的なコンテキストを使用して簡単に生成を条件付けることができます! 私たちは、驚くほどの一貫性を持つ写実的な写真に漫画の絵を変えることができます。 写実的なLofiガール また、それをあなたのインテリアデザイナーとして使用することもできます。 Before After あなたはスケッチのスクリブルを芸術的な絵に変えることができます。 Before After さらに、有名なロゴを生き生きとさせることもできます。 Before After ControlNetを使用すると、可能性は無限大です🌠 このブログ記事では、まずStableDiffusionControlNetPipelineを紹介し、さまざまな制御条件にどのように適用できるかを示します。さあ、制御しましょう! ControlNet: TL;DR ControlNetは、Lvmin ZhangとManeesh AgrawalaによってText-to-Image Diffusion Modelsに条件付き制御を追加することで導入されました。これにより、Stable DiffusionなどのDiffusionモデルに追加の条件として使用できるさまざまな空間的コンテキストをサポートするフレームワークが導入されます。ディフュージョンモデルの実装は、元のソースコードから適応されています。 ControlNetのトレーニングは次の手順で行われます:…

StackLLaMA:RLHFを使用してLLaMAをトレーニングするための実践ガイド
ChatGPT、GPT-4、Claudeなどのモデルは、Reinforcement Learning from Human Feedback(RLHF)と呼ばれる手法を使用して、予想される振る舞いにより適合するように微調整された強力な言語モデルです。 このブログ記事では、LlaMaモデルをStack Exchangeの質問に回答するためにRLHFを使用してトレーニングするために関与するすべてのステップを以下の組み合わせで示します: 教師あり微調整(SFT) 報酬/選好モデリング(RM) 人間のフィードバックからの強化学習(RLHF) From InstructGPT paper: Ouyang, Long, et al. “Training language models to follow instructions with human…
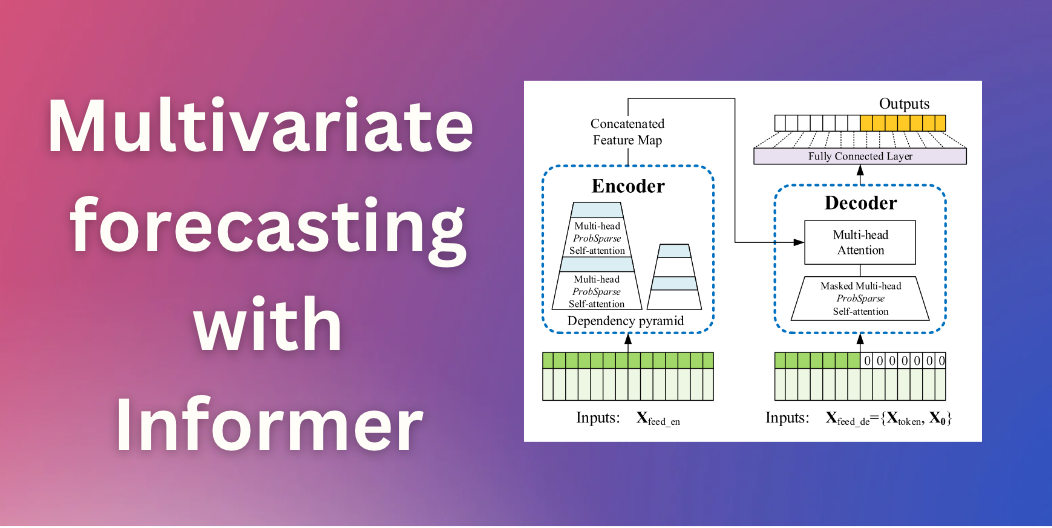
Informerを使用した多変量確率時系列予測
イントロダクション 数ヶ月前、私たちはTime Series Transformerを紹介しました。これは、予測に適用されたバニラTransformer(Vaswani et al.、2017)であり、単一変量の確率的予測課題(つまり、各時系列の1次元分布を個別に予測すること)の例を示しました。この記事では、現在🤗 Transformersで利用可能な、AAAI21のベストペーパーであるInformerモデル(Zhou, Haoyi, et al., 2021)を紹介します。これを使用して、多変量の確率的な予測課題、つまり、将来の時系列ターゲット値のベクトルの分布を予測する方法を示します。なお、バニラのTime Series Transformerモデルにも同様に適用できます。 多変量確率時系列予測 確率予測のモデリングの観点からは、Transformer/Informerは多変量時系列に対して取り扱う際に変更を必要としません。単変量と多変量の設定の両方で、モデルはベクトルのシーケンスを受け取り、唯一の変更は出力またはエミッション側にあります。 高次元データの完全な結合条件付き分布をモデリングすると、計算コストが高くなる場合があります。そのため、データを同じファミリーからの独立した分布、または完全な共分散の低ランク近似など、いくつかの近似手法に頼ることがあります。ここでは、実装した分布のファミリーに対してサポートされている独立(または対角)エミッションに頼ることにします。 Informer – 内部構造 バニラTransformer(Vaswani et al.、2017)に基づいて、Informerは2つの主要な改善を採用しています。これらの改善を理解するために、バニラTransformerの欠点を思い出してみましょう。 正準自己注意の二次計算:バニラTransformerは、計算量がO (…

RWKVとは、トランスフォーマーの利点を持つRNNの紹介です
ChatGPTとチャットボットを活用したアプリケーションは、自然言語処理(NLP)の領域で注目を集めています。コミュニティは、アプリケーションやユースケースに強力で信頼性の高いオープンソースモデルを常に求めています。これらの強力なモデルの台頭は、Vaswaniらによって2017年に最初に紹介されたトランスフォーマーベースのモデルの民主化と広範な採用によるものです。これらのモデルは、それ以降のSoTA NLPモデルである再帰型ニューラルネットワーク(RNN)ベースのモデルを大幅に上回りました。このブログ投稿では、RNNとトランスフォーマーの両方の利点を組み合わせた新しいアーキテクチャであるRWKVの統合を紹介します。このアーキテクチャは最近、Hugging Face transformersライブラリに統合されました。 RWKVプロジェクトの概要 RWKVプロジェクトは、Bo Peng氏が立ち上げ、リードしています。Bo Peng氏は積極的にプロジェクトに貢献し、メンテナンスを行っています。コミュニティは、公式のdiscordチャンネルで組織されており、パフォーマンス(RWKV.cpp、量子化など)、スケーラビリティ(データセットの処理とスクレイピング)、および研究(チャットの微調整、マルチモーダルの微調整など)など、さまざまなトピックでプロジェクトの成果物を常に拡張しています。RWKVモデルのトレーニングに使用されるGPUは、Stability AIによって寄付されています。 公式のdiscordチャンネルに参加し、RWKVの基本的なアイデアについて詳しく学ぶことで、参加することができます。以下の2つのブログ投稿で詳細を確認できます:https://johanwind.github.io/2023/03/23/rwkv_overview.html / https://johanwind.github.io/2023/03/23/rwkv_details.html トランスフォーマーアーキテクチャとRNN RNNアーキテクチャは、データのシーケンスを処理するための最初の広く使用されているニューラルネットワークアーキテクチャの1つであり、固定サイズの入力を取る従来のアーキテクチャとは異なります。RNNは、現在の「トークン」(つまり、データストリームの現在のデータポイント)、前の「状態」を入力として受け取り、次のトークンと次の状態を予測します。新しい状態は、次のトークンの予測を計算するために使用され、以降も同様に続きます。RNNは異なる「モード」でも使用できるため、Andrej Karpathy氏のブログ投稿で示されているように、1対1(画像分類)、1対多(画像キャプション)、多対1(シーケンス分類)、多対多(シーケンス生成)など、さまざまなシナリオでRNNを適用することが可能です。 RNNは、各ステップで予測を計算するために同じ重みを使用するため、勾配消失の問題により長距離のシーケンスに対する情報の記憶に苦労します。この制限に対処するために、LSTMやGRUなどの新しいアーキテクチャが導入されましたが、トランスフォーマーアーキテクチャはこの問題を解決するためにこれまでで最も効果的なものとなりました。 トランスフォーマーアーキテクチャでは、入力トークンは自己注意モジュールで同時に処理されます。トークンは、クエリ、キー、値の重みを使用して異なる空間に線形にプロジェクションされます。結果の行列は、アテンションスコアを計算するために直接使用され、その後値の隠れ状態と乗算されて最終的な隠れ状態が得られます。この設計により、アーキテクチャは長距離のシーケンスの問題を効果的に緩和し、RNNモデルと比較して推論とトレーニングの速度も高速化します。 トランスフォーマーアーキテクチャは、トレーニング中に従来のRNNおよびCNNに比べていくつかの利点があります。最も重要な利点の1つは、文脈的な表現を学習できる能力です。RNNやCNNとは異なり、トランスフォーマーアーキテクチャは単語ごとではなく、入力シーケンス全体を処理します。これにより、シーケンス内の単語間の長距離の依存関係を捉えることができます。これは、言語翻訳や質問応答などのタスクに特に有用です。 推論中、RNNは速度とメモリ効率の面でいくつかの利点があります。これらの利点には、単純さ(行列-ベクトル演算のみが必要)とメモリ効率(推論中にメモリ要件が増えない)が含まれます。さらに、現在のトークンと状態にのみ作用するため、コンテキストウィンドウの長さに関係なく計算速度が同じままです。 RWKVアーキテクチャ RWKVは、AppleのAttention Free Transformerに触発されています。アーキテクチャは注意深く簡素化され、最適化されており、RNNに変換することができます。さらに、TokenShiftやSmallInitEmbなどのトリックが追加されています(公式のGitHubリポジトリのREADMEにトリックのリストが記載されています)。これにより、モデルのパフォーマンスがGPTに匹敵するように向上しています。現在、トレーニングを14Bパラメータまでスケーリングするためのインフラストラクチャがあり、RWKV-4(本日の最新バージョン)では数値の不安定性など、いくつかの問題が反復的に修正されました。 RNNとトランスフォーマーの組み合わせとしてのRWKV…

基礎モデルは人間のようにデータにラベルを付けることができますか?
ChatGPTの登場以来、Large Language Models(LLM)の開発に前例のない成長が見られ、特にプロンプト形式の指示に従うように微調整されたチャットモデルの開発が増えてきました。しかし、これらのモデルの比較は、その性能を厳密にテストするために設計されたベンチマークの不足により明確ではありません。指示とチャットモデルの評価は本質的に困難であり、ユーザーの好みの大部分は質的なスタイルに集約されていますが、過去のNLP評価ははるかに定義されていました。 このような状況で、新しい大規模言語モデル(LLM)が「モデルはChatGPTに対してN%の時間で優先される」という調子でリリースされるのはよくあることですが、その文から省かれているのは、そのモデルがGPT-4ベースの評価スキームで優先されるという事実です。これらのポイントが示そうとしているのは、異なる測定の代理となるものです:人間のラベラーが提供するスコア。人間のフィードバックから強化学習でモデルを訓練するプロセス(RLHF)は、2つのモデル補完を比較するためのインターフェースとデータを増やしました。このデータはRLHFプロセスで使用され、優先されるテキストを予測する報酬モデルを訓練するために使用されますが、モデルの出力を評価するための評価とランキングのアイデアは、より一般的なツールとなっています。 ここでは、ブラインドテストセットのinstructとcode-instructの分割それぞれからの例を示します。 反復速度の観点では、言語モデルを使用してモデルの出力を評価することは非常に効率的ですが、重要な要素が欠けています:下流のツールショートカットが元の測定形式と整合しているかどうかを調査することです。このブログ投稿では、オープンLLMリーダーボード評価スイートを拡張することで、選択したLLMから得られるデータラベルを信頼できるかどうかを詳しく調べます。 LLMSYS、nomic / GPT4Allなどのリーダーボードが登場し始めましたが、モデルの能力を比較するための完全なソースが必要です。一部のモデルは、既存のNLPベンチマークを使用して質問応答の能力を示すことができ、一部はオープンエンドのチャットからのランキングをクラウドソーシングしています。より一般的な評価の全体像を提示するために、Hugging Face Open LLMリーダーボードは、自動化された学術ベンチマーク、プロの人間のラベル、およびGPT-4の評価を含むように拡張されました。 目次 オープンソースモデルの評価 関連研究 GPT-4評価の例 さらなる実験 まとめとディスカッション リソースと引用 オープンソースモデルの評価 ヒトがデータをキュレートする必要があるトレーニングプロセスのどのポイントでもコストがかかります。これまでに、AnthropicのHHHデータ、OpenAssistantの対話ランキング、またはOpenAIのLearning to Summarize /…

はい、トランスフォーマーは時系列予測に効果的です(+オートフォーマー)
イントロダクション 数ヶ月前、AAAI 2021のベストペーパーアワードを受賞したTime Series TransformerであるInformerモデル(Zhou, Haoyiら、2021)を紹介しました。また、Informerを使用した多変量確率予測の例も提供しました。この記事では、「Transformerは時系列予測に効果的か?」(AAAI 2023)という疑問について議論します。見ていくとわかりますが、それらは効果的です。 まず、Transformerは確かに時系列予測に効果的であることを経験的に証明します。私たちの比較では、線形モデルであるDLinearが主張されるほど優れていないことが示されています。線形モデルと同じ設定の同等の大きさのモデルと比較した場合、Transformerベースのモデルは私たちが考慮するテストセットのメトリックでより優れた性能を発揮します。その後、Informerモデルの後にNeurIPS 2021で発表されたAutoformerモデル(Wu, Haixuら、2021)を紹介します。Autoformerモデルは現在🤗 Transformersで利用できます。最後に、Autoformerの分解層を使用するシンプルなフィードフォワードネットワークであるDLinearモデルについて説明します。DLinearモデルは、「Transformerは時系列予測に効果的か?」という論文で初めて紹介され、Transformerベースのモデルを時系列予測で上回ると主張されています。 さあ、始めましょう! ベンチマーキング – Transformers vs. DLinear 最近AAAI 2023で発表された「Transformerは時系列予測に効果的か?」という論文では、著者らはTransformerが時系列予測に効果的ではないと主張しています。彼らは、DLinearと呼ばれるシンプルな線形モデルとTransformerベースのモデルを比較しています。DLinearモデルはAutoformerモデルの分解層を使用しており、後ほどこの記事で紹介します。著者らは、DLinearモデルがTransformerベースのモデルを時系列予測で上回ると主張しています。本当にそうなのでしょうか?さあ、確かめましょう。 上記の表は、論文で使用された3つのデータセットにおけるAutoformerモデルとDLinearモデルの比較結果を示しています。結果からわかるように、Autoformerモデルは3つのデータセットすべてでDLinearモデルを上回っています。 次に、上記の表のTrafficデータセットを使用してAutoformerモデルとDLinearモデルを比較し、得られた結果の説明を提供します。 要約: 簡単な線形モデルは一部の場合において有利ですが、ユニバリエートの設定では変数を組み込む能力がTransformerのようなより複雑なモデルに比べてありません。 Autoformer…

低リソースASRのためのMMSアダプターモデルの微調整
新しい(06/2023):このブログ記事は、「多言語ASRでのXLS-Rの微調整」に強く触発され、それの改良版として見なされるものです。 Wav2Vec2は、自動音声認識(ASR)のための事前学習モデルであり、Alexei Baevski、Michael Auli、およびAlex Conneauによって2020年9月にリリースされました。Wav2Vec2の強力なパフォーマンスが、ASRの最も人気のある英語データセットであるLibriSpeechで示された直後、Facebook AIはWav2Vec2の2つのマルチリンガルバージョンであるXLSRとXLM-Rを発表しました。これらのモデルは128の言語で音声を認識することができます。XLSRはクロスリンガル音声表現を意味し、モデルが複数の言語で有用な音声表現を学習する能力を指します。 Meta AIの最新リリースであるMassive Multilingual Speech(MMS)(Vineel Pratap、Andros Tjandra、Bowen Shiなどによる)は、マルチリンガル音声表現を新たなレベルに引き上げています。1,100以上の話されている言語が識別、転写、生成され、さまざまな言語識別、音声認識、テキスト読み上げのチェックポイントがリリースされます。 このブログ記事では、MMSのアダプタートレーニングが、わずか10〜20分の微調整後でも驚くほど低い単語エラーレートを達成する方法を示します。 低リソース言語の場合、私たちは「多言語ASRでのXLS-Rの微調整」と同様にモデル全体を微調整するのではなく、MMSのアダプタートレーニングの使用を強くお勧めします。 私たちの実験では、MMSのアダプタートレーニングはメモリ効率がよく、より堅牢であり、低リソース言語に対してはより優れたパフォーマンスを発揮することがわかりました。ただし、VoAGIから高リソース言語への場合は、Adapterレイヤーの代わりにモデル全体のチェックポイントを微調整する方が依然として有利です。 世界の言語多様性の保存 https://www.ethnologue.com/によると、約3000の「生きている」言語のうち、40%、つまり約1200の言語が、話者が減少しているために危機に瀕しています。このトレンドはますますグローバル化する世界で続くでしょう。 MMSは、アリ語やカイビ語など、絶滅危惧種である多くの言語を転写することができます。将来的には、MMSは、残された話者が母国語での記録作成やコミュニケーションをサポートすることで、言語を生き続けるために重要な役割を果たすことができます。 1000以上の異なる語彙に適応するために、MMSはアダプターを使用します。アダプターレイヤーは言語間の知識を活用し、モデルが別の言語を解読する際に役立つ役割を果たします。 MMSの微調整 MMSの非監視チェックポイントは、1400以上の言語で300万〜10億のパラメータを持つ、50万時間以上のオーディオで事前学習されました。 事前学習のためのモデルサイズ(300Mおよび1B)の事前学習のみのチェックポイントは、🤗 Hubで見つけることができます:…

Open LLMのリーダーボードはどうなっていますか?
最近、Falcon 🦅のリリースおよびOpen LLM Leaderboardへの追加に関して、Twitter上で興味深い議論が起こりました。Open LLM Leaderboardは、オープンアクセスの大規模言語モデルを比較する公開のリーダーボードです。 この議論は、リーダーボードに表示されている4つの評価のうちの1つであるMassive Multitask Language Understanding(略称:MMLU)のベンチマークを中心に展開されました。 コミュニティは、リーダーボードの現在のトップモデルであるLLaMAモデル 🦙のMMLU評価値が、公開されたLLaMa論文の値よりも著しく低いことに驚きました。 そのため、私たちは何が起こっているのか、そしてそれを修正する方法を理解するために深堀りしました 🕳🐇 私たちとのこの冒険の旅において、私たちはLLaMAの評価に協力した素晴らしい@javier-m氏、そしてFalconチームの素晴らしい@slippylolo氏と話し合いました。もちろん、以下のエラーは彼らではなく、私たちに帰すべきです! この冒険の旅の中で、オンラインや論文で見る数値を信じるべきかどうか、モデルを単一の評価で評価する方法について多くのことを学ぶことができます。 準備はいいですか?それでは、シートベルトを締めましょう、出発します 🚀。 Open LLM Leaderboardとは何ですか? まず、Open LLM Leaderboardは、実際にはEleutherAI非営利AI研究所によって作成されたオープンソースのベンチマークライブラリEleuther…

より一般的なロボットへのスタッキング
棒を拾って丸太の上にバランスをとったり、石の上に小石を積んだりすることは、人にとっては簡単で似たような行動に見えるかもしれませんしかし、ほとんどのロボットは、複数のこのようなタスクを同時に処理するのに苦労します棒を操作するには、石を積み上げるよりも異なる行動のセットが必要ですましてや様々な皿を積み重ねたり家具を組み立てたりすることはさらに難しいですこれらのタスクをロボットに教える前に、ロボットはまずより広範なオブジェクトとの相互作用を学ぶ必要がありますDeepMindのミッションの一環として、より一般的で有用なロボットを作るための一歩として、私たちはロボットが異なる幾何学的な形状を持つオブジェクトとの相互作用をより良く理解する方法を探求しています
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.