Learn more about Search Results A - Page 213

- You may be interested
- 「これらの完全自動の深層学習モデルは、...
- このAI研究は、深層学習システムが継続的...
- 「GO TO Any Thing(GOAT)」とは、完全に...
- 実験追跡ツールの構築方法[Neptuneのエン...
- 予めトレーニングされた基礎モデルは、分...
- 「BoomiのCEOが統合と自動化プラットフォ...
- 「プライバシーと著作権法違反についてOpe...
- 「2024年に注目すべきトップ10のリモート...
- 次のLangChainプロジェクトのための基本を...
- 因果推論:準実験
- 「Huggingface 🤗を使用したLLMsのためのR...
- 「心理学を活用してサイバーセキュリティ...
- 「Python制御フローチートシート」
- マルチエージェント強化学習における新興...
- 「AIの潜在能力解放:クラウドGPUの台頭」

Salesforceは、データ駆動型のAIとCRMを通じて生産性と顧客の信頼性を高める、新しいEinstein 1プラットフォームを発表しました
顧客データは混乱しています。組織は通常、1,061の独自のアプリケーションを使用していますが、そのうちの29%しか本当に統合されていません。クラウド、ソーシャルメディア、モバイルコンピューティングの革命によって作成されたデータアイランドの増殖により、複雑な企業データスタックが生まれています。 Salesforceが開発した元のメタデータフレームワークは、Salesforceのすべてのアプリケーション間でデータの整理と理解を容易にします。これは、同じコアプラットフォーム上に構築されたアプリケーションに対して共有の言語を持つことに似ています。複数のシステムからのデータをSalesforceのメタデータフレームワークにマッピングすることで、会社のデータの統合ビューを作成することができます。 SalesforceのEinstein AIとData Cloudの最新のアップデートにより、ビジネスはデータと人工知能を活用して生産性を向上させ、顧客との相互作用をカスタマイズすることが容易になりました。Salesforceの新しいEinstein 1プラットフォームは、EinsteinプラットフォームのAI機能とData CloudをCRMプログラムにシームレスに統合しています。企業は今や簡単にインテリジェントなワークフローをオペレーションに統合し、別々のデータ保管場所に格納された顧客データを組み合わせ、AIパワードのアプリケーションを作成することができます。 顧客データ、企業コンテンツ、テレメトリデータ、Slackの議論、その他の構造化および非構造化データは、SalesforceのData Cloudを介して顧客の一元的なビューを形成するために結合されます。このリアルタイムハイパースケールデータエンジンは、毎日1000億のレコードをリンクおよび統合し、1か月に300兆のトランザクションを実行しています。 新しいData CloudがEinstein 1プラットフォームとの緊密な統合を実現したことで、企業は以前アクセスできなかったデータを解放し、包括的な顧客プロファイルを生成し、革新的なCRMサービスを導入することができます。 スケール時のデータ: Einstein 1プラットフォームは、顧客ごとに数兆行のデータと数千のメタデータ対応アイテムを処理できるようになりました。SalesforceがCustomer 360を提供するために買収したMarketing CloudとCommerce Cloudの消費者スケールのテクノロジースタックも、Einstein 1プラットフォーム上で再設計されました。 スケール時の自動化: 大規模なデータセットをEinstein 1プラットフォームに外部ソースからインポートし、即座にインタラクティブなSalesforceオブジェクトとして利用できるようになりました。インターネットオブシングスデバイスからのイベント、計算された洞察、またはAIの予測である場合でも、MuleSoftを使用して、組織内のレガシーシステムを含む任意のシステムと20,000イベント/秒のスピードで対話することができます。 スケール時の分析: Salesforceは、多様なユースケースに対応するReports…

「リソース制約のあるアプリケーションにおいて、スパースなモバイルビジョンMoEsが密な対応物よりも効率的なビジョンTransformerの活用を解き放つ方法」
ミクスチャー・オブ・エキスパート(MoE)と呼ばれるニューラルネットワークのアーキテクチャは、さまざまなエキスパートニューラルネットワークの予測を組み合わせます。MoEモデルは、いくつかのサブタスクや問題の要素が専門的な知識を必要とする複雑な作業に対応します。これらは、ニューラルネットワークの表現を強化し、さまざまな難しいタスクを処理できるようにするために導入されました。 さらに、スパースゲーテッド・ミクスチャー・オブ・エキスパート(MoE)として知られるニューラルネットワークのアーキテクチャは、ゲーティングメカニズムに疎結合性を追加することで従来のMoEモデルのアイデアを拡張します。これらのモデルは、MoEデザインの効率性とスケーラビリティを向上させ、コンピューティングコストを低減するために作成されています。 それぞれの入力トークンに対してモデルパラメータの一部のみを独占的に活性化できる能力により、モデルのサイズと推論の効率を切り離すことができます。 ニューラルネットワーク(NN)を使用する場合、特にわずかな計算リソースしか利用できない場合には、パフォーマンスと効率の両方をバランスさせることは依然として困難です。スパースゲーテッド・ミクスチャー・オブ・エキスパートモデル(sparse MoEs)は、モデルのサイズと推論の効率を切り離すことができるため、最近は潜在的な解決策として見なされています。 スパースMoEsは、モデルの能力を増強し、計算コストを最小限に抑える可能性を提供します。これにより、大規模なビジュアルモデリングの主要なアーキテクチャ選択肢であるTransformersと統合するオプションとなります。 このため、Appleの研究チームは、「Mobile V-MoEs: Scaling Down Vision Transformers via Sparse Mixture-of-Experts」という論文で、スパースモバイルビジョンMoEsの概念を紹介しました。これらのV-MoEsは、優れたモデルパフォーマンスを維持しながらVision Transformers(ViTs)を縮小する効率的でモバイルフレンドリーなミクスチャーオブエキスパートデザインです。 研究者は、セマンティックスーパークラスを活用してエキスパートのアンバランスを回避するシンプルで堅牢なトレーニング手順を開発したと強調しています。これにより、パッチごとのルーティングでは通常、各画像に対してより多くのエキスパートがアクティブになりますが、パーイメージルーターでは画像ごとのアクティブなエキスパートの数が減少します。 研究チームは、トレーニングフェーズをベースラインモデルのトレーニングから始めました。その後、モデルの予測をトレーニングデータセットから保持された検証セットに記録し、混同行列を作成しました。この混同グラフは、混同行列を基にグラフクラスタリングアルゴリズムによって処理されました。このプロセスにより、スーパークラスの分割が作成されました。 彼らは、モデルが標準のImageNet-1k分類ベンチマークで経験的な結果を示していると述べています。彼らは、1.28Mの画像からなるImageNet-1kトレーニングセットですべてのモデルをゼロからトレーニングし、その後、50Kの画像からなる検証セットでのトップ1の精度を評価しました。 研究者は将来的にもViTs以外のモバイルフレンドリーモデルでMoEデザインを使用したいと考えています。また、物体検出などの他のビジュアルタスクも考慮に入れる予定です。さらに、すべてのモデルにおける実際のオンデバイスのレイテンシを定量化することを目指しています。
「Apache Sparkにおけるメモリ管理:ディスクスピル」
ディスクスピルとは何ですか?なぜそれが起こるのですか?ディスクスピルの影響を軽減して、Sparkジョブを最適化しましょう
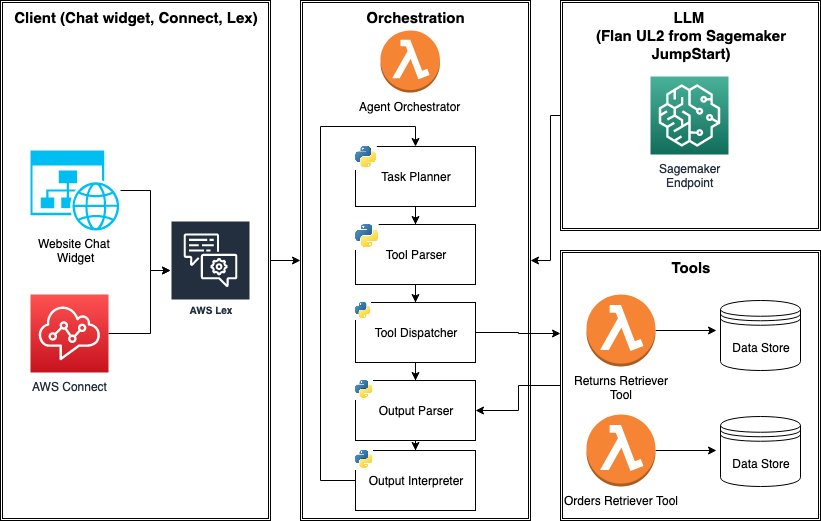
AWS SageMaker JumpStart Foundation Modelsを使用して、ツールを使用するLLMエージェントを構築し、展開する方法を学びましょう
大規模な言語モデル(LLM)エージェントは、1)外部ツール(API、関数、Webフック、プラグインなど)へのアクセスと、2)自己指導型のタスクの計画と実行の能力を持つ、スタンドアロンのLLMの機能を拡張するプログラムですしばしば、LLMは複雑なタスクを達成するために他のソフトウェア、データベース、またはAPIと対話する必要があります[...]

「SIEM-SOAR インテグレーションによる次世代の脅威ハンティング技術」
NLP、AI、およびMLは、データ処理の効率化、自動化されたインシデント処理、コンプライアンス、および積極的な脅威検知を通じて、サイバーセキュリティを向上させます

「AIはオーディオブック制作をどのように革新しているのか? ニューラルテキストtoスピーチ技術により、電子書籍から数千冊の高品質なオーディオブックを作成する」
現在では、多くの人々が書籍や他のメディアの代わりにオーディオブックを読んでいます。オーディオブックは、現在の読者が道路上で情報を楽しむだけでなく、子供や視覚障害者、新しい言語を学んでいる人などのグループにもコンテンツを利用しやすくすることができます。従来のオーディオブック制作技術は時間と費用がかかり、プロの人間のナレーションやLibriVoxのようなボランティア主導の取り組みなど、録音品質のばらつきが生じることがあります。これらの問題により、出版される書籍の増加に追いつくには時間と労力がかかります。 ただし、テキスト読み上げシステムのロボット的な性質や、目次、ページ番号、図表、脚注などのテキストを読み上げないようにする難しさにより、自動オーディオブック作成はこれまで苦労してきました。彼らは、さまざまなオンライン電子書籍コレクションから高品質のオーディオブックを作成するために、最近のニューラルテキスト読み上げ、表現豊かな読み上げ、スケーラブルな計算、関連コンテンツの自動認識などの最新の進展を取り入れた手法を提供しています。 彼らは、オープンソースに5,000冊以上のオーディオブック、合計35,000時間以上の音声を提供しています。また、デモンストレーションソフトウェアも提供しており、会議参加者がライブラリの本を声に出して読むだけで、自分自身の声でオーディオブックを作成できるようになっています。この研究では、HTMLベースの電子書籍を優れたオーディオブックに変換するためのスケーラブルな方法を紹介しています。パイプラインの基盤としては、分散オーケストレーションが可能なスケーラブルな機械学習プラットフォームであるSynapseMLが使用されています。彼らの配信チェーンは、数千冊のProject Gutenbergが提供する無料の電子書籍から始まります。これらの書籍は主にHTML形式で取り扱われており、自動解析に適しています。 その結果、Project GutenbergのHTMLページの完全なコレクションを整理し、同様の構造を持つファイルの多数のグループを特定することができました。主要な電子書籍のクラスは、これらのHTMLファイルのコレクションを使用して作成されたルールベースのHTML正規化器を使用して、標準形式に変換されました。このアプローチにより、大量の本を迅速かつ確実に解析することができました。最も重要なことは、読み上げると高品質の録音になるファイルに焦点を当てることができたということです。 図1: t-SNEクラスタリングされた電子書籍の表現。同じ形式の本のクラスターは、色付きの領域で示されています。 このクラスタリングの結果は、図1に示されており、Project Gutenbergのコレクションにおいて同様に構成された電子書籍のさまざまなグループが自発的に現れる様子が示されています。処理後、プレーンテキストのストリームを抽出し、テキスト読み上げアルゴリズムに供給することができます。さまざまなオーディオブックには多くの読み方のテクニックが必要です。ノンフィクションには明確で客観的な声が最適であり、対話があるフィクションには表現豊かな読み上げと少しの「演技」が適しています。ただし、ライブデモンストレーションでは、テキストの声、ペース、ピッチ、抑揚を変更するオプションを提供します。ほとんどの本では、明確で中立的なニューラルテキスト読み上げの声を使用しています。 彼らは、ゼロショットテキスト読み上げ技術を使用して、登録された少数の録音から効果的に声の特徴を転送し、ユーザーの声を再現しています。これにより、少量のキャプチャされた音声だけで、ユーザーは迅速に自分の声でオーディオブックを作成することができます。また、音声と感情の推論システムを使用して、文脈に基づいて読み上げの声やトーンを動的に変更し、感情的なテキスト読み上げを行います。これにより、複数の人物や動的な対話を持つシーケンスのリアルさと興味が向上します。 これを実現するために、まずテキストをナレーションと会話に分割し、各対話ごとに異なる話者を割り当てます。次に、セルフスーパーバイズド学習を使用して、各対話の感情的なトーンを予測します。最後に、異なる声と感情をナレーターとキャラクターの会話に割り当てるために、マルチスタイルとコンテキストベースのニューラルテキスト読み上げモデルを使用します。彼らは、このアプローチがオーディオブックの利用可能性とアクセシビリティを大幅に向上させる可能性があると考えています。 を日本語に翻訳すると、 となります。

「Google DeepMind Researchがニューラルネットワークにおける理解現象の謎を探求:記憶と一般化の相互作用を明らかにする」
ニューラルネットワークが学習し一般化するという従来の理論は、ニューラルネットワークの中でのグロッキングの発生によって検証されています。ニューラルネットワークがトレーニングされている間、トレーニング損失が低くなり収束するにつれて、テストデータ上のネットワークのパフォーマンスも向上することが期待されますが、最終的にはネットワークの振る舞いは安定します。ネットワークは最初はトレーニングデータを記憶しているように見えますが、グロッキングによって、トレーニング損失は低く安定したままでありながら、一般化が不十分な結果となります。驚くべきことに、より多くのトレーニングを行うことで、ネットワークは完璧な一般化へと進化します。 ここで疑問が生じます。なぜ、ほとんど完璧なトレーニングパフォーマンスを達成した後でも、ネットワークのテストパフォーマンスはさらなるトレーニングによって劇的に改善するのでしょうか?ネットワークは最初に完璧なトレーニング精度を達成しますが、一般化が不十分であり、その後のトレーニングで完璧な一般化に変換されます。この振る舞いこそがニューラルネットワークにおけるグロッキングです。最近の研究論文で、研究チームは、ネットワークが学習しようとしているタスク内に2つの種類の解が共存していることに基づいてグロッキングの説明を提案しました。解は次のようになります。 一般化解:このアプローチでは、ニューラルネットワークは新しいデータに対して一般化するのに適しています。パラメータのノルム、すなわちネットワークのパラメータの大きさが同じである場合、より大きなロジットまたは出力値を生成することができます。この解は学習が遅く効率が高い特徴を持っています。 記憶解:このアプローチでは、ネットワークはトレーニングデータを記憶し、完璧なトレーニング精度を達成しますが、一般化は効果的ではありません。記憶回路は新しい情報を迅速に取り込むことができますが、同じロジット値を生成するにはより多くの入力が必要です。 研究チームは、記憶回路はトレーニングデータセットのサイズが増えるにつれて効果が低下する一方、一般化回路にはほとんど影響がないことを共有しています。これは、一般化と記憶回路の両方が同じくらい効果的なデータセットサイズ、つまりクリティカルデータセットサイズが存在することを意味します。研究チームは、次の4つの革新的な仮説を検証し、その説明を強力な証拠で支持しています。 著者らは、ネットワークが最初に入力を記憶し、次第に一般化を強調することでグロッキングが起こると予測し、実証しました。この変化により、テスト精度が向上します。 彼らは、記憶と一般化の回路の効果が同等であるクリティカルデータセットサイズの概念を提案しました。このクリティカルサイズは学習プロセスで重要なステージを表しています。 アングロッキング:最も予想外の発見の1つは、「アングロッキング」という現象の発生です。ネットワークが重要なデータセットサイズよりもはるかに小さいデータセットでトレーニングを続けると、完璧なテスト精度から低いテスト精度に逆戻りします。 セミグロッキング:この研究では、セミグロッキングという概念が導入されています。これは、記憶と一般化の回路の効果がバランスの取れたデータセットサイズでトレーニングされたネットワークが、完璧なテスト精度ではなく部分的なテスト精度を達成した後に位相転移を経ることを示しています。これにより、ニューラルネットワーク内のさまざまな学習メカニズムの微妙な相互作用が示されます。 結論として、この研究はグロッキング現象の徹底的かつ独自の説明を提供しています。それは、ネットワークの振る舞いに影響を与える重要な要素が、メモリと一般化の解の共存、およびこれらの解の効果であることを示しています。したがって、予測と経験データを提供することにより、ニューラルネットワークの一般化とそのダイナミクスをより理解することができます。

ラックスペースは、繰り返しタスクをスピードアップし、プライベートデータを迅速に分析するための生成型AIシステム「ICE」を発表しました
ラックスペース・テクノロジー株式会社は、新しい生成型人工知能システム「ICE」と呼ばれるシステムを開発しましたサンアントニオ・エクスプレスニュースの報告によると、ICEはビジネスが繰り返しのタスクを迅速に進め、プライベートデータを迅速に分析するために設計されていますICEは大規模な言語モデルを使用する専用システムです...

ヘリオットワット大学とAlana AIの研究者は、大規模言語モデルに基づく新しい具現化対話エージェント「FurChat」を提案しています
大規模言語モデル(LLMs)は、技術が飛躍的に進歩する世界で中心的な役割を果たしています。これらのLLMsは、非常に洗練されたコンピュータプログラムであり、驚くほど自然な方法で人間の言語を理解し、生成し、相互作用することができます。最近の研究では、FurChatとして知られる革新的な具現化対話エージェントが公開されました。GPT-3.5のようなLLMsは、自然言語処理において可能なことの境界を em>押し広げています。それらは文脈を理解し、質問に答え、通常の人間が書いたかのように感じるテキストを生成することさえできます。この強力な機能により、ロボティクスなどのさまざまな領域で無数の機会が開かれています。 Heriot-Watt大学とAlana AIの研究者たちは、受付係として機能し、ダイナミックな会話を行い、表情を介して感情を伝える革命的なシステムであるFurChatを提案しています。National RobotariumでのFurChatの展開は、その変革の可能性を象徴しており、訪問者との自然な会話を促し、施設、ニュース、研究、および今後のイベントに関するさまざまな情報を提供しています。 人間の顔に非常に似た3Dマスクを持ち、そのマスクにアニメーションされた表情を投影するためにマイクロプロジェクタを使用しているヒューマノイドロボットバストのFurhatロボット。ロボットは、頭部を動かしてうなずくことができるように監視されたプラットフォームに取り付けられており、リアルな相互作用を向上させています。コミュニケーションを容易にするために、Furhatはマイクロフォンアレイとスピーカーを備えており、人間の話し言葉を認識して応答することができます。 システムは、シームレスなアプリケーションのために設計されています。対話管理には、NLU、DM、およびカスタムデータベースの3つの主要なコンポーネントが関与しています。NLUは、着信テキストを分析し、意図を分類し、信頼性を評価します。DMは、会話の流れを維持し、LLMsにプロンプトを送信し、応答を処理します。カスタムデータベースは、Nation Robotariumのウェブサイトをウェブスクレイピングして作成され、ユーザーの意図に関連するデータを提供します。プロンプトエンジニアリングは、LLMから自然な応答を生成するために、フューショットラーニングとプロンプトラーニングのテクニックを組み合わせています。ジェスチャーパーシングは、Furhat SDKの顔の動作とLLMのテキストからの感情認識を活用し、話し言葉と顔の表情を同期させることで、没入型のインタラクションを作り出しています。テキストから音声への変換にはAmazon Pollyが使用されており、FurhatOSで利用できます。 将来、研究者たちはその能力を拡張する準備を進めています。彼らは、受付ロボットの分野での活発な研究領域である多人数の相互作用を可能にすることを目指しています。さらに、言語モデルの幻覚による問題に取り組むために、言語モデルの微調整や直接的な会話生成といった戦略を探求する予定です。研究者にとっての重要なマイルストーンは、SigdialカンファレンスでのFurChatのデモンストレーションです。これは、システムの能力をより広範な同僚や専門家の視聴者に示すプラットフォームとなります。

「PythonでChatGPTを使用する方法」
ChatGPTをPythonで強化する方法が知りたいですか?Pythonを使用してKommunicateプラットフォームのアカウントをステップバイステップで設定する方法を学びましょう
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.