Learn more about Search Results A - Page 211

- You may be interested
- 「近似予測」によって特徴選択を劇的に高速化
- 「PythonのPandasライブラリを使用した非...
- 自分の脳の季節性を活用した、1年間のデー...
- マシンラーニングエンジニアは、実際に何...
- 7つの最高の履歴書ビルダーAIツール
- 機械学習インサイトのディレクター[Part 2...
- 「データ分析に関する5つの無料大学のコー...
- 「Plotly プロットでインド数字システムの...
- 「12年生終了後、データサイエンティスト...
- AI/MLを活用してインテリジェントなサプラ...
- 「ジャムのマッピング:グラフ理論を用い...
- 認知コンピューティング:定義、動作、例など
- 13分でハミルトンを使用したメンテナブル...
- 「スタンフォード大学と一緒に無料でコン...
- 「10 Best AIウェブサイトビルダー」

MITとマイクロソフトの研究者が、DoLaという新しいAIデコーディング戦略を紹介しましたこれは、LLMsにおける幻覚を減らすことを目的としています
大規模言語モデル(LLM)の利用により、多くの自然言語処理(NLP)アプリケーションが大きな恩恵を受けてきました。LLMは性能が向上し、スケールアップにより追加の機能を獲得しましたが、事前トレーニング中に検出された実世界の事実と一致しない情報を「幻覚」する問題を抱えています。これは高リスクなアプリケーション(臨床や法的な設定など)において、信頼性のあるテキストの生成が不可欠な場合には、採用の障害となります。 データとモデルの分布の間の前方KLダイバージェンスを最小化しようとする最尤言語モデリングのターゲットが、LLMの幻覚の原因かもしれません。しかし、これは確証されているわけではありません。この目標を追求する場合、LMは、トレーニングデータにエンコードされた知識と完全に一致しないフレーズに非ゼロの確率を割り当てる場合があります。 モデルの解釈可能性の観点からは、トランスフォーマーの初期レイヤーは「低レベル」の情報(品詞タグなど)をエンコードすることが示されています。対照的に、後のレイヤーはより「意味的な」情報をエンコードします。 MITとMicrosoftの研究者グループは、このモジュラーな知識のエンコードを利用して、より深いレベルからの情報を優先し、中間または浅いレベルの情報を軽視することで、LMの事実の知識を増やすための対照的なデコーディング戦略を提案しています。 彼らの最近の研究は、Decoding by Contrasting Layers(DoLa)という新しいデコーディング手法を紹介しています。提案された手法は、外部の知識を取得したり、さらなる微調整を行ったりせずに、LLMにエンコードされた事実知識の露出を改善することに基づいています。 DoLaは、TruthfulQAおよびFACTORの両方でLLaMAファミリーモデルの整合性を改善する実験的な証拠が示されています。StrategyQAとGSM8K ccの両方で、連鎖思考の推論に関する追加の実験は、事実の推論を改善する可能性を示しています。最後に、GPT-4で評価されたオープンエンドのテキスト生成の実験結果は、DoLaが情報を提供し、元のデコーディング手法と比較して優れた評価を導くより事実に基づく応答を生成することができることを示しています。DoLaは、LLMの信頼性を高めるためのデコーディング手法であり、研究結果はデコーディングプロセスにわずかな時間しか追加しないことを示しています。 研究者たちは、他のドメイン(指示の従順性や人間のフィードバックへの反応など)でのモデルのパフォーマンスを調査していません。また、人間のラベルや事実情報源を利用して微調整するのではなく、チームは既存のアーキテクチャとパラメータに依存しており、可能な改善の範囲を制限しています。特定の回収強化LMとは異なり、この手法は完全にモデルの既存の知識に依存しており、外部の回収モジュールを介して新しい情報を追加することはありません。チームは、将来の研究が上記のコンポーネントをデコーディング技術に組み込んで制限を克服するのに役立つことを望んでいます。

「AIおよびARはデータ需要を推進しており、オープンソースハードウェアはその課題に応えています」
「データはデジタル経済の命脈であり、新しい技術が現れ進化するにつれて、データセンターにおける高速データ転送速度、低い遅延時間、高い計算能力への需要が指数関数的に増加しています新しい技術はデータの伝送と処理の限界を押し広げており、オープンソース技術の採用はデータセンターの運用者にとって有益です[…]
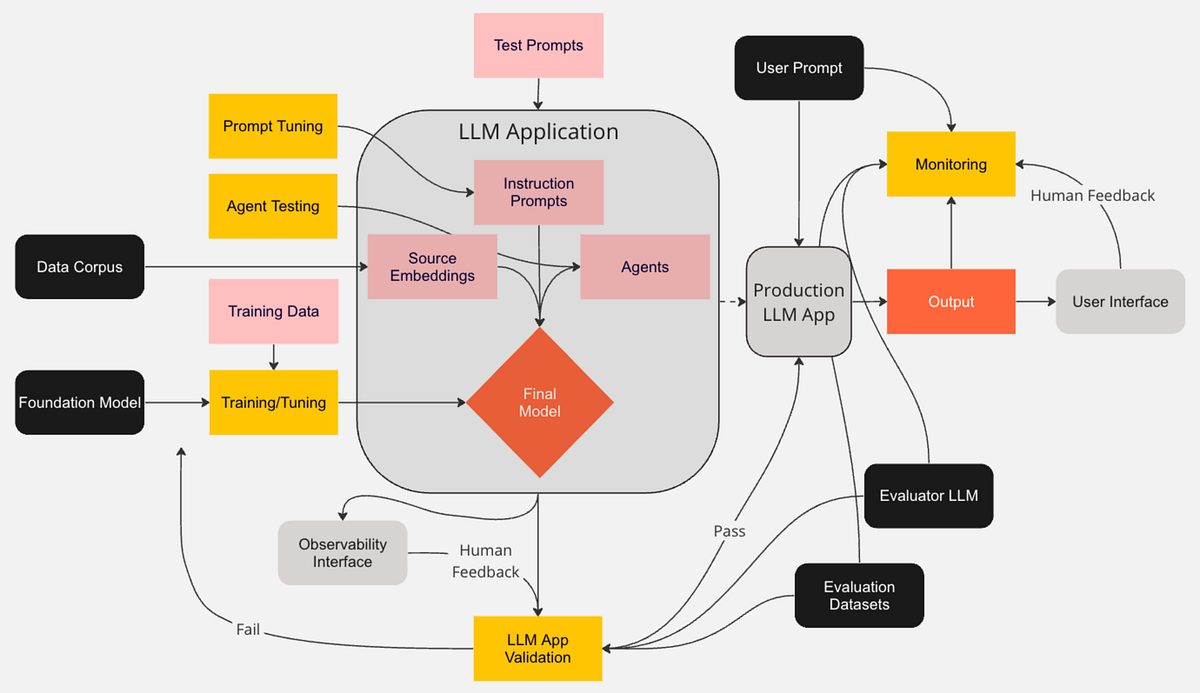
「LLMモニタリングと観測性 – 責任あるAIのための手法とアプローチの概要」
対象読者:実践者が利用可能なアプローチと実装の始め方を学びたい方、そして構築する際に可能性を理解したいリーダーたち…

ChatGPTのペルソナとは何ですか?
テクノロジーの急速な進化の世界では、チャットボットはプロフェッショナルな場でも個人的な場でも欠かせない存在となっていますチャットボットが急速に普及した理由は、複雑なタスクを簡素化し、即座のカスタマーサービスを提供し、ユーザーを楽しませる能力にあると言えますしかし、技術が成熟するにつれ、多様なニーズに対応するためにはより洗練されたアプローチが求められました

「AIを活用したツールにより、3Dプリント可能なモデルの個別化が容易になります」
Style2Fabを使用することで、メーカーは補助具などの3Dプリンタで作成可能なオブジェクトのモデルを迅速にカスタマイズできますが、機能に支障をきたしません

「視覚化された実装と共に、Graph Attention Network(GAT)の解説」
グラフニューラルネットワーク(GNN)の理解は、トランスフォーマーがオープングラフベンチマークからのようなグラフ問題に取り組むことが増えるにつれてますます重要になっています自然言語が必要なのであれば...

「BLIVAと出会ってください:テキスト豊かなビジュアル質問をより良く扱うためのマルチモーダルな大規模言語モデル」
最近、大規模言語モデル(LLMs)は、自然言語理解の分野で重要な役割を果たしており、ゼロショットやフューショットのシナリオを含む幅広いタスクの一般化能力において、素晴らしい能力を示しています。OpenAIのGPT-4などのVision Language Models(VLMs)は、画像または一連の画像に関する質問に答えるためにモデルが答える必要があるオープンエンドのビジュアルクエスチョンアンサリング(VQA)タスクの解決において、大きな進展を遂げています。これらの進展は、LLMsと視覚理解能力の統合によって実現されています。 視覚関連のタスクにおいてLLMsを活用するために、視覚エンコーダのパッチ特徴との直接的なアライメントや、一定数のクエリ埋め込みを介した画像情報の抽出など、様々な手法が提案されています。 しかし、これらのモデルは、画像内のテキストを解釈する際に課題に直面します。テキストを含む画像は日常生活でよく見られ、このようなコンテンツを理解する能力は人間の視覚知覚にとって重要です。以前の研究では、クエリ埋め込みを使用した抽象モジュールが使用されていましたが、このアプローチでは画像内のテキストの詳細を捉える能力が制限されていました。 本記事で概説されている研究では、研究者らはBLIVA(InstructBLIP with Visual Assistant)というマルチモーダルLLMを紹介しています。このモデルは、LLM自体と密接に関連する学習済みのクエリ埋め込みと、より広範な画像関連データを含む画像エンコードされたパッチ埋め込みという2つの主要なコンポーネントを統合するように戦略的に設計されています。提案手法の概要は以下の図に示されています。 https://arxiv.org/abs/2308.09936 この技術は、通常言語モデルに画像情報を提供する際に関連する制約を克服し、最終的にはテキスト-イメージの視覚知覚と理解を向上させるものです。モデルは、事前学習済みのInstructBLIPと、ゼロからトレーニングされたエンコードされたパッチ射影層を使用して初期化されます。2段階のトレーニングパラダイムが採用されています。初期段階では、パッチ埋め込み射影層の事前トレーニングと、インストラクションチューニングデータを使用してQ-formerとパッチ埋め込み射影層の両方を微調整します。このフェーズでは、実験から得られた2つの主な結果に基づいて、画像エンコーダとLLMの両方が凍結された状態に保たれます。第一に、ビジョンエンコーダを凍結解除すると、以前の知識の大規模な忘却が起こります。第二に、LLMの同時トレーニングは改善をもたらさず、トレーニングの複雑さを導入します。 著者によって示された2つのサンプルシナリオは、”詳細なキャプション”および”小さなキャプション+VQA”に関連するVQAタスクにおけるBLIVAの影響を示しています。 https://arxiv.org/abs/2308.09936 これが、VQAタスクに取り組むためにテキストとビジュアルエンコードされたパッチ埋め込みを組み合わせる革新的なAI LLMマルチモーダルフレームワークであるBLIVAの概要でした。興味があり、さらに詳しく知りたい場合は、以下に引用されたリンクを参照してください。

PyCharm vs. Spyder 正しいPython IDEの選択
PyCharmとSpyderはPython開発のための2つの最も人気のあるIDEですでは、PyCharmとSpyderの直接比較を見てみましょう

ウェブサイトのためにChatGPTに適切なテクニカルテキストを書かせる方法
「長いテキストを書くように依頼しないでくださいできるだけ多くの詳細と仕様を提供し、適切な言語を使用し、AIディテクターでチェックしてください」

「Retrieval Augmented GenerationとLangChain Agentsを使用して、内部情報へのアクセスを簡素化する」
この投稿では、顧客が内部文書を検索する際に直面する最も一般的な課題について説明し、AWSサービスを使用して内部情報をより有用にするための生成型AI対話ボットを作成するための具体的なガイダンスを提供します組織内に存在するデータのうち、非構造化データが全体の80%を占めています[...]
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.