Learn more about Search Results ドキュメンテーション - Page 20

- You may be interested
- 「もしも、視覚のみのモデルを、わずかな...
- 遺伝予測モデルをより包括的にする
- AIテクノロジーを使ってあなたの牛を見守る
- 「推薦システムにおける二つのタワーモデ...
- 「データ視覚化の技術をマスターする: ヒ...
- DL Notes 高度な勾配降下法
- プラグ可能な回折ニューラルネットワーク...
- 「Huggingface 🤗を使用したLLMsのためのR...
- 「ベストを学ぶ – 必読のテック企業...
- 責任あるAI進歩のための政策アジェンダ:...
- 「Llama 2がコーディングを学ぶ」
- 「MLOpsの考え方:常に本番準備完了」
- Hugging Faceの推論エンドポイントを使用...
- 「データ分析のためのトップ10のSQLプロジ...
- 公正を実現する:生成モデルにおけるバイ...
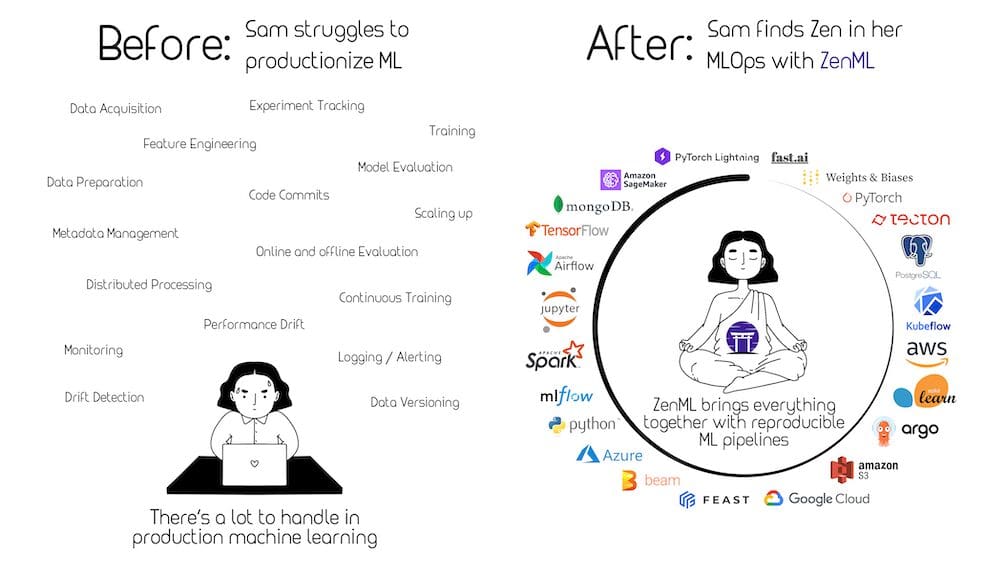
「MLOpsに関する包括的なガイド」
「Machine Learning Operations(MLOps)は、機械学習(ML)モデルが本番環境で繁栄するために必要な構造とサポートを提供する比較的新しい学問分野です」

「MetaGPTと出会ってください:GPTをエンジニア、建築家、マネージャに変えるオープンソースAIフレームワーク」
大規模言語モデル(LLM)ベースのマルチエージェントシステムは、人間の操作を模倣し、改善するための非常に優れた機会を持っています。しかし、最近の研究によって示されるように、現行のシステムは現実世界の応用に存在する複雑さにおいてより正確である必要がある場合があります。これらのシステムは、口頭やツールベースのやり取りを通じて建設的な協力を促進するための支援が主に必要であり、これにより、連続した非生産的なフィードバックループを減らし、実りのある協力的な相互作用を促進することが困難になります。多様なプロセスが効果的になるためには、よく構造化された標準化された作業手順(SOP)が必要です。実世界の実践に対する徹底的な認識と統合が重要です。 これらの一般的な制約を解決し、これらの知見を取り入れることで、LLMベースのマルチエージェントシステムの設計と構造を改善し、その効果と応用を向上させることが重要です。また、広範な共同プラクティスを通じて、人々はさまざまな分野で一般的に認識されているSOPを作成してきました。これらのSOPは、効果的な作業の分解と調整を容易にするために不可欠です。たとえば、ソフトウェアエンジニアリングにおけるウォーターフォールプロセスは、要件分析、システム設計、コーディング、テスト、成果物のための論理的なステップを確立します。 この合意形成ワークフローの助けを借りて、いくつかのエンジニアが生産的に協力することができます。また、人間の仕事には、それぞれの職務に適した専門的な知識があります。ソフトウェアエンジニアはプログラミングスキルを使ってコードを作成し、プロダクトマネージャーは市場調査を行って顧客の要求を特定します。協力は通常の出力から逸脱し、組織化されなくなります。たとえば、プロダクトマネージャーは、ユーザーの要望、市場のトレンド、競合する製品に関する徹底的な競争調査を実施し、開発を推進するために製品要件文書(PRD)を作成する必要があります。これらの分析には、明確で標準化された形式と優先順位付けられた目標が必要です。 これらの規範的なアーティファクトは、異なる役割からの関連する貢献を要する複雑な多様なプロジェクトの進展には欠かせません。これらは共同理解を具体化します。したがって、関連する役割に基づいた行動の仕様を使用してSOPをコーディングします。第三に、情報の交換を容易にするために、エージェントは標準化されたアクションの出力を作成します。MetaGPTは、人間の専門家が交換するアーティファクトを形式化することで、相互依存するジョブ間の調整を合理化します。エージェントは、活動とツールやリソースの共有に対する洞察を提供する共有環境によって接続されます。エージェント間のすべての通信は、この環境に含まれています。また、すべての協力記録が保存されるグローバルメモリプールも提供され、エージェントは必要なデータに対して購読または検索することができます。エージェントは、このメモリプールから以前のメッセージを取得してより多くの文脈を把握することができます。 対話を通じて情報を受動的に吸収するのではなく、このアーキテクチャはエージェントが積極的に関連する情報を観察し、引き出すことができるようにします。この設定は、チームワークを奨励する実際の職場に見られるシステムを模倣しています。彼らは、小規模なゲームの制作からより複雑な大規模なシステムまでを包括する、共同ソフトウェア開発のワークフローや関連するコード実装実験を表示して、そのアーキテクチャの効果を示しています。MetaGPTは、GPT-3.5やAutoGPT、AgentVerseなどのオープンソースフレームワークよりもはるかに多くのソフトウェアの複雑さを管理します。 さらに、MetaGPTは、自動的なエンドツーエンドのプロセス全体で要件書類、設計アーティファクト、フローチャート、およびインターフェース仕様を生成します。これらの中間の標準化された出力は、最終的なコードの実行の成功率を大幅に向上させます。自動生成されたドキュメンテーションのおかげで、人間の開発者は迅速に学習し、自分の専門知識を向上させて要件、設計、およびコードをさらに改善することができます。また、より洗練された人間-AIの相互作用が可能になります。結論として、彼らはさまざまなソフトウェアプロジェクトについての包括的な研究によってMetaGPTの妥当性を検証しています。 MetaGPTの役割ベースの専門家エージェント協働パラダイムによって可能になる可能性は、量的なコード生成のベンチマークとプロセス全体の出力の質的評価を通じて示されています。要するに、彼らは主に以下のような貢献をしました: • 役割定義、タスクの分解、プロセスの標準化などを含む、新しいメタプログラミングメカニズムを設計しました。 • 彼らは、人間のSOPをLLMエージェントにエンコードし、複雑な問題解決の能力を根本的に拡張するためのLLMベースのマルチエージェント協調フレームワークであるMetaGPTを提案しています。 • AutoGPT、AgentVerse、LangChain、およびMetaGPTを使用して、CRUD2コード、基本的なデータ分析ジョブ、およびPythonゲームの開発について広範なテストを行っています。 このようにして、MetaGPTはSOPを利用して複雑なソフトウェアを作成することができます。全体の結果は、MetaGPTがコードの品質と予測されるプロセスとの適合性の点で、競合他社を大幅に上回っていることを示しています。

AIは人間過ぎるようになったのでしょうか?Google AIの研究者は、LLMsがツールのドキュメントだけでMLモデルやAPIを利用できるようになったことを発見しました!
人工知能が地球を支配しようとする現代において、大規模な言語モデルは人間の脳により近づいています。Googleの研究者たちは、大規模な言語モデルが各ツールのドキュメンテーションを提供するだけで事前のトレーニングなしに未知のツールをゼロショットで使用できることを証明しました。 この解決策全体を、4歳のオードリーに自転車の乗り方を教えることに例えることができます。最初に、彼女に自転車の乗り方を教え、学ぶのを手伝いました(デモンストレーション)。トレーニングホイールを使って乗る方法と、トレーニングホイールを使わずに乗る方法を彼女に示しました。つまり、さまざまなシナリオを彼女に見せました。この解決策は、彼女が本(ドキュメント)で自転車の乗り方を読み、自転車のさまざまな機能について学び、私たちの助けなしで乗ることができるようになった部分に対応しており、それを非常に印象的に行っています。彼女はスキッドすることができ、トレーニングホイールを使ったり使わずに乗ることができます。ここにオードリーが成長した様子が見えますね? デモンストレーション(デモ)は、少数の例を使用して言語モデルにツールの使用方法を教えます。存在するすべてのツールプランをカバーするためには、多くの例が必要かもしれません。ドキュメンテーション(ドキュメント)は、ツールの機能を説明することで言語モデルにツールの使用方法を教えます。 ドキュメントとデモをプロンプトに含める/除外する組み合わせ、およびデモの数を変えて、モデルの結果とパフォーマンスを分析しました。さまざまなツールセットを使用して、複数のモダリティにまたがる6つのタスクで実験が行われました。使用されたLLMプランナーはChatGPT(gpt-3.5-turbo)で、6つのタスクは以下の通りです:ScienceQAにおけるマルチモーダルな質問応答、TabMWTabMWP(数学推論データセット)における表形式の数学推論、NLVRv2におけるマルチモーダルな推論、新たに収集されたデータセットにおける未知のAPIの使用、自然言語による画像編集、およびビデオトラッキング。 彼らは、各データセットでツールのドキュメンテーションを使用した場合と使用しなかった場合のモデルのパフォーマンスを、異なる数のデモンストレーション(デモ)で評価しました。調査結果は、ツールのドキュメント化によってデモンストレーションの必要性が低下することを示しています。ツールのドキュメントがある場合、モデルはデモンストレーションの数が削減されても安定したパフォーマンスを維持するようですが、ツールのドキュメントがない場合、モデルのパフォーマンスは使用されるデモンストレーションの数に非常に敏感であることが示されました。 品質の比較を通じて、ドキュメントに頼ることは、大規模な言語モデルが多数の利用可能なツールを備えるためのスケーラブルな解決策を提供することがわかりました。さらに、ツールのドキュメントだけでLLMは最新のビジョンモデルを理解し、新しいデモを必要とせずに画像編集やビデオトラッキングのタスクで印象的な結果を達成することができます。研究者は、結果が非常に印象的で別のブレークスルーを示唆しているものの、ドキュメントの長さが600ワードを超えると性能が低下することを発見しました。 結果として、この論文はLLMがドキュメンテーションを通じてツールを学ぶだけでなく、追加のデモンストレーションなしで「Grounded SAM」と「Track Anything」などの人気プロジェクトの結果を再現することを示し、ツールのドキュメントを通じた自動的な知識の発見の可能性を示唆しています。これにより、LLMにおけるツールの使用の視点において新たな方向性がもたらされ、モデルの推論能力を明らかにすることを目指しています。

「生成AIの規制」
生成型の人工知能(AI)が注目を集める中、この技術を規制する必要性が高まっていますなぜなら、この技術は大規模な人口に対して迅速に負の影響を与える可能性があるからです影響は以下のようなものが考えられます...

「クロスファンクションの機械学習プロジェクトの20の学び」
「クロスチームのプロジェクトでリーダーシップを取るか、または助けるかに関わらず、それは圧倒的なものとなるかもしれませんそして、締め切りを追い、時には複雑な状況を管理するストレスは、常に「何をすればいいのか」という感覚を持つことがあります...」

ML MonorepoのPantsでの組織化
「プロジェクト間でユーティリティコードの一部をコピー&ペーストしたことがありますか?その結果、同じコードの複数のバージョンが異なるリポジトリに存在することになりましたか?または、データを保存するGCPバケットの名前が更新された後、数十のプロジェクトにプルリクエストを行わなければなりませんでしたか?上記のような状況はあまりにも頻繁に発生します...」

「Stitch FixにおけるMLプラットフォーム構築からの学び」
この記事は元々、MLプラットフォームポッドキャストのエピソードであり、Piotr NiedźwiedźとAurimas GriciūnasがMLプラットフォームの専門家と一緒に、デザインの選択肢、ベストプラクティス、具体的なツールスタックの例、そして最高のMLプラットフォームの専門家からの実世界の学びについて話し合っていますこのエピソードでは、Stefan KrawczykがMLを構築する際に得た学びを共有しています...
「プログラミング言語の構築方法:成功への(困難な)道のり」
私の以前の記事では、自分のプログラミング言語についての構文を概説し、それを構築する方法の一般的なアイデアを提供しましたしかし、最終的な目標に向けた私の道のりに専念したもう一つの記事を書くことにしました...

あなたの製品の開発者学習のためのLLM(大規模言語モデル)
「LLM(Large Language Models)とLLMアプリを活用して、効果的かつ効率的な開発者教育を進め、製品の活用を促進する方法を探求してください」
「多数から少数へ:機械学習における次元削減による高次元データの取り扱い」
この記事では、機械学習の問題における次元の呪いと、その問題の解決策としての次元削減について議論します時には、機械学習の問題は次元削減を必要とする場合があります...
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.