Learn more about Search Results - Page 20

- You may be interested
- 「9歳の子に機械学習を説明するとしたら、...
- ChatGPT コードインタプリター 数分でデー...
- 「セキュアな会話:ChatGPTの使用時にプラ...
- トランスフォーマーにおけるアテンション...
- アントロピックは、SKテレコムから1億ドル...
- 「マルチラベル分類:PythonのScikit-Lear...
- 環境データサイエンス:イントロダクション
- プライバシー保護のためのAIとブロックチ...
- 学習されたプラズマ制御を通じて融合科学...
- 「生成AIはその環境への足跡に値するのか?」
- データモデリング入門、パート1:データモ...
- 「みんなのためのLLM:ランニングLangChai...
- 予測の作成:Pythonにおける線形回帰の初...
- Principal Components Analysis(主成分分...
- Google AIは、アクティブノイズキャンセリ...

Nyström形式:ニュストローム法による線形時間とメモリでのセルフアテンションの近似
はじめに トランスフォーマーは、さまざまな自然言語処理やコンピュータビジョンのタスクで優れた性能を発揮しています。その成功は、自己注意メカニズムによるものであり、入力のすべてのトークン間のペアワイズな相互作用を捉えることができます。しかし、標準の自己注意メカニズムは、入力シーケンスの長さ n n n (ここで n n n は入力シーケンスの長さ)に対して O ( n 2 ) O(n^2) O ( n 2 ) の時間とメモリの複雑さを持ち、長い入力シーケンスでのトレーニングには高コストです。 Nyströmformer は、標準の自己注意を…

プライベートハブのご紹介:機械学習を活用した新しいビルド方法
機械学習は、企業が技術を構築する方法を変えつつあります。革新的な新製品のパワーを供給し、私たちが使い慣れて愛している既知のアプリケーションにスマートな機能を提供することから、MLは開発プロセスの中心にあります。 しかし、すべての技術の変化には新たな課題が伴います。 機械学習モデルの約90%が本番環境に到達しないとされています。馴染みのないツールや非標準的なワークフローがMLの開発を遅くしています。モデルやデータセットが内部で共有されないため、同じような成果物がチーム間で常にゼロから作成されます。データサイエンティストは、ビジネスステークホルダーに技術的な作業を示すのが難しく、正確でタイムリーなフィードバックを共有するのに苦労しています。そして、機械学習チームはDocker/Kubernetesや本番環境向けのモデル最適化に時間を浪費しています。 これらを考慮して、私たちはPrivate Hub(PH)を立ち上げました。機械学習の構築方法を革新する新しい方法です。研究から本番環境まで、セキュアかつコンプライアンスを確保しながら、機械学習ライフサイクルの各ステップを加速するための統合されたツールセットを提供します。PHはさまざまなMLツールを一つにまとめることで、機械学習の協力をよりシンプルで楽しく、生産的にします。 このブログ投稿では、Private Hubとは何か、なぜ役立つのか、そしてどのようにお客様がそれを使用してMLのロードマップを加速しているのかについて詳しく説明します。 一緒に読んでいただくか、興味を引くセクションにジャンプしてください 🌟: ハグフェースハブとは何ですか? プライベートハブとは何ですか? 企業はプライベートハブをどのように使用してMLのロードマップを加速しているのでしょうか? さあ、始めましょう! 🚀 1. ハグフェースハブとは何ですか? プライベートハブについて詳しく説明する前に、まずハグフェースハブについて見てみましょう。これはPHの中心的な要素です。 ハグフェースハブは、オープンソースで公開されているオンラインプラットフォームで、人々が簡単に協力してMLを構築できる場所です。ハブは、機械学習と一緒に技術を探求し、実験し、協力し、構築するための中心的な場所として機能します。 ハグフェースハブでは、次のようなMLアセットを作成または発見することができます: モデル:NLP、コンピュータビジョン、音声、時系列、生物学、強化学習、化学などの最新の最先端モデルをホスティング。 データセット:さまざまなドメイン、モダリティ、言語に対応したデータの幅広いバリエーション。 スペース:ブラウザ内で直接MLモデルをショーケースするインタラクティブなアプリ。 ハブにアップロードされた各モデル、データセット、またはスペースは、Gitベースのリポジトリです。これはすべてのファイルを含むバージョン管理された場所で、従来のgitコマンドを使用してファイルをプル、プッシュ、クローン、操作することができます。モデル、データセット、およびスペースのコミット履歴を表示し、誰がいつ何を行ったかを確認することができます。 モデルのコミット履歴…

プロキシマルポリシーオプティマイゼーション(PPO)
Deep Reinforcement Learning ClassのUnit 8、Hugging Faceと共に 🤗 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 ⚠️ この記事の新しい更新版はこちらで利用可能です 👉 https://huggingface.co/deep-rl-course/unit1/introduction この記事はDeep Reinforcement Learning Classの一部です。初心者からエキスパートまでの無料コースです。シラバスはこちらをご確認ください。 前のユニットでは、Advantage…

MTEB 大規模テキスト埋め込みベンチマーク
MTEBは、さまざまな埋め込みタスクでテキスト埋め込みモデルのパフォーマンスを測定するための大規模ベンチマークです。 🥇リーダーボードは、さまざまなタスクで最高のテキスト埋め込みモデルの包括的なビューを提供します。 📝論文は、MTEBのタスクとデータセットについての背景を説明し、リーダーボードの結果を分析しています! 💻Githubリポジトリには、ベンチマークのためのコードとリーダーボードへの任意のモデルの提出が含まれています。 テキスト埋め込みの重要性 テキスト埋め込みは、意味情報をエンコードするテキストのベクトル表現です。コンピュータは計算を行うために数値の入力を必要とするため、テキスト埋め込みは多くのNLPアプリケーションの重要な要素です。たとえば、Googleはテキスト埋め込みを検索エンジンの動力源として使用しています。テキスト埋め込みは、クラスタリングによる大量のテキストのパターン検出や、最近のSetFitのようなテキスト分類モデルへの入力としても使用できます。ただし、テキスト埋め込みの品質は、使用される埋め込みモデルに大きく依存します。MTEBは、さまざまなタスクに対して最適な埋め込みモデルを見つけるのに役立つように設計されています! MTEB 🐋 Massive:MTEBには8つのタスクにわたる56のデータセットが含まれ、現在リーダーボード上の>2000の結果を要約しています。 🌎 Multilingual:MTEBには最大112の異なる言語が含まれています!Bitext Mining、Classification、STSにおいていくつかの多言語モデルをベンチマークにかけました。 🦚 Extensible:新しいタスク、データセット、メトリクス、またはリーダーボードの追加に関しては、どんな貢献も大歓迎です。リーダーボードへの提出やオープンな課題の解決については、GitHubリポジトリをご覧ください。最高のテキスト埋め込みモデルの発見の旅にご参加いただければ幸いです。 MTEBのタスクとデータセットの概要。多言語データセットは紫の色で表示されます。 モデル MTEBの初期ベンチマークでは、最新の結果を謳うモデルやHubで人気のあるモデルに焦点を当てました。これにより、トランスフォーマーの代表的なモデルが多く含まれています。🤖 平均英語MTEBスコア(y)対速度(x)対埋め込みサイズ(円のサイズ)でモデルをグループ化しました。 次の3つの属性にモデルを分類して、タスクに最適なモデルを簡単に見つけることをお勧めします: 🏎 最大速度 Gloveのようなモデルは高速ですが、文脈の理解が不足しており、平均MTEBスコアが低くなります。 ⚖️ 速度とパフォーマンス…

🤗 Optimum IntelとOpenVINOでモデルを高速化しましょう
昨年7月、インテルとHugging Faceは、Transformerモデルのための最新かつシンプルなハードウェアアクセラレーションツールの開発で協力することを発表しました。本日、私たちはOptimum IntelにIntel OpenVINOを追加したことをお知らせできて非常に嬉しく思います。これにより、Hugging FaceハブまたはローカルにホストされるTransformerモデルを使用して、様々なIntelプロセッサ上でOpenVINOランタイムによる推論を簡単に実行できます(サポートされているデバイスの完全なリストを参照)。OpenVINOニューラルネットワーク圧縮フレームワーク(NNCF)を使用してモデルを量子化し、サイズと予測レイテンシをわずか数分で削減することもできます。 この最初のリリースはOpenVINO 2022.2をベースにしており、私たちのOVModelsを使用して、多くのPyTorchモデルに対する推論を実現しています。事後トレーニング静的量子化と量子化感知トレーニングは、多くのエンコーダモデル(BERT、DistilBERTなど)に適用することができます。今後のOpenVINOリリースでさらに多くのエンコーダモデルがサポートされる予定です。現在、エンコーダデコーダモデルの量子化は有効化されていませんが、次のOpenVINOリリースの統合により、この制限は解除されるはずです。 では、数分で始める方法をご紹介します! Optimum IntelとOpenVINOを使用してVision Transformerを量子化する この例では、食品101データセットでイメージ分類のためにファインチューニングされたVision Transformer(ViT)モデルに対して事後トレーニング静的量子化を実行します。 量子化は、モデルパラメータのビット幅を減らすことによってメモリと計算要件を低下させるプロセスです。ビット数を減らすことで、推論時に必要なメモリが少なくなり、行列乗算などの演算が整数演算によって高速に実行できるようになります。 まず、仮想環境を作成し、すべての依存関係をインストールしましょう。 virtualenv openvino source openvino/bin/activate pip install pip --upgrade pip…
トランスフォーマーにおける対比的探索を用いた人間レベルのテキスト生成 🤗
1. 紹介: 自然言語生成(テキスト生成)は自然言語処理(NLP)の中核的なタスクの一つです。このブログでは、現在の最先端のデコーディング手法であるコントラスティブサーチを神経テキスト生成のために紹介します。コントラスティブサーチは、元々「A Contrastive Framework for Neural Text Generation」[1]([論文] [公式実装])でNeurIPS 2022で提案されました。さらに、この続編の「Contrastive Search Is What You Need For Neural Text Generation」[2]([論文] [公式実装])では、コントラスティブサーチがオフザシェルフの言語モデルを使用して16の言語で人間レベルのテキストを生成できることが示されています。 [備考] テキスト生成に馴染みのないユーザーは、このブログ記事を詳しくご覧ください。 2.…

ホモモーフィック暗号化による暗号化データの感情分析
感情分析モデルは、テキストがポジティブ、ネガティブ、または中立であるかを判断することが広く知られています。しかし、このプロセスには通常、暗号化されていないテキストへのアクセスが必要であり、プライバシー上の懸念が生じる可能性があります。 ホモモーフィック暗号化は、復号化することなく暗号化されたデータ上で計算を行うことができる暗号化の一種です。これにより、ユーザーの個人情報や潜在的に機密性の高いデータがリスクにさらされるアプリケーションに適しています(例:プライベートメッセージの感情分析)。 このブログ投稿では、Concrete-MLライブラリを使用して、データサイエンティストが暗号化されたデータ上で機械学習モデルを使用することができるようにしています。事前の暗号学の知識は必要ありません。暗号化されたデータ上で感情分析モデルを構築するための実践的なチュートリアルを提供しています。 この投稿では以下の内容をカバーしています: トランスフォーマー トランスフォーマーをXGBoostと組み合わせて感情分析を実行する方法 トレーニング方法 Concrete-MLを使用して予測を暗号化されたデータ上の予測に変換する方法 クライアント/サーバープロトコルを使用してクラウドにデプロイする方法 最後に、この機能を実際に使用するためのHugging Face Spaces上の完全なデモで締めくくります。 環境のセットアップ まず、次のコマンドを実行してpipとsetuptoolsが最新であることを確認します: pip install -U pip setuptools 次に、次のコマンドでこのブログに必要なすべてのライブラリをインストールします。 pip install concrete-ml transformers…
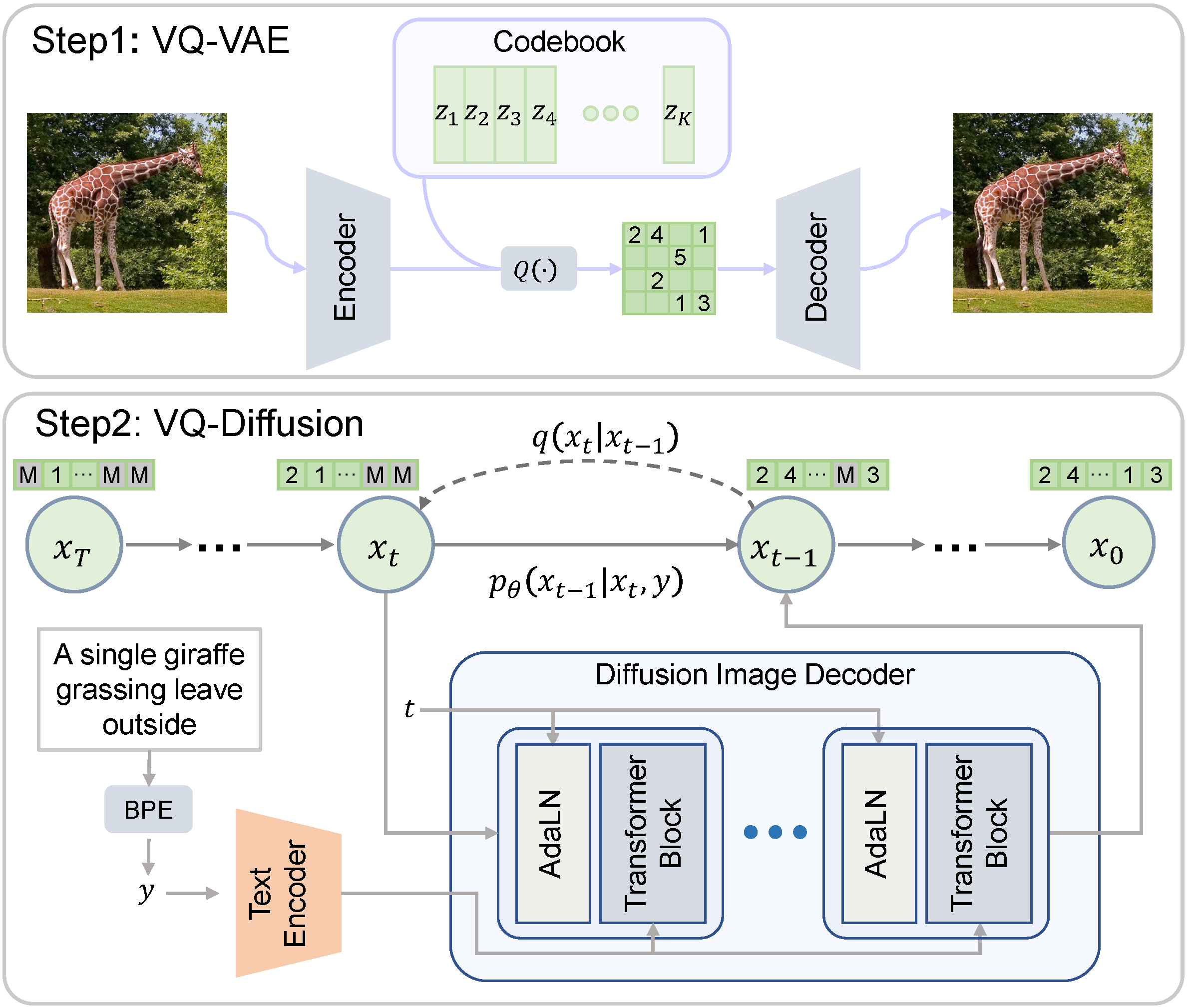
VQ-Diffusion
ベクトル量子化拡散(VQ-Diffusion)は、中国科学技術大学とMicrosoftによって開発された条件付き潜在拡散モデルです。一般的に研究されている拡散モデルとは異なり、VQ-Diffusionのノイジングとデノイジングのプロセスは量子化された潜在空間で動作します。つまり、潜在空間は離散的なベクトルの集合で構成されています。離散的な拡散モデルは、連続的な対応物と比較する興味深い比較対象を提供します。 Hugging Faceモデルカード Hugging Face Spaces オリジナルの実装 論文 デモ 🧨 Diffusersを使用すると、わずか数行のコードでVQ-Diffusionを実行できます。 依存関係をインストールする pip install 'diffusers[torch]' transformers ftfy パイプラインをロードする from diffusers import VQDiffusionPipeline pipe =…

Apple SiliconでのCore MLを使用した安定した拡散を利用する
Appleのエンジニアのおかげで、Core MLを使用してApple SiliconでStable Diffusionを実行できるようになりました! このAppleのレポジトリは、🧨 Diffusersを基にした変換スクリプトと推論コードを提供しており、私たちはそれが大好きです!できるだけ簡単にするために、私たちは重みを変換し、モデルのCore MLバージョンをHugging Face Hubに保存しました。 更新:この投稿が書かれてから数週間後、私たちはネイティブのSwiftアプリを作成しました。これを使用して、自分自身のハードウェアでStable Diffusionを簡単に実行できます。私たちはMac App Storeにアプリをリリースし、他のプロジェクトがそれを使用できるようにソースコードも公開しました。 この投稿の残りの部分では、変換された重みを自分自身のコードで使用する方法や、追加の重みを変換する方法について説明します。 利用可能なチェックポイント 公式のStable Diffusionのチェックポイントはすでに変換されて使用できる状態です: Stable Diffusion v1.4:変換されたオリジナル Stable Diffusion v1.5:変換されたオリジナル Stable…

ストーリーの生成:ゲーム開発のためのAI #5
AIゲーム開発へようこそ!このシリーズでは、AIツールを使用してわずか5日で完全な機能を備えた農業ゲームを作成します。このシリーズの終わりまでに、さまざまなAIツールをゲーム開発のワークフローに取り入れる方法を学ぶことができます。以下のような目的でAIツールを使用する方法をお見せします: アートスタイル ゲームデザイン 3Dアセット 2Dアセット ストーリー クイックビデオバージョンが欲しいですか? こちらでご覧いただけます。それ以外の場合は、技術的な詳細を読み続けてください! 注:この投稿では、ゲームデザインにChatGPTを使用したPart 2への参照がいくつかあります。ChatGPTの動作方法、言語モデルの概要、およびその制限についての追加のコンテキストについては、Part 2をお読みください。 Day 5: ストーリー このチュートリアルシリーズのPart 4では、Stable DiffusionとImage2Imageを2Dアセットのワークフローに使用する方法について説明しました。 この最終パートでは、ストーリーにAIを使用します。まず、農業ゲームのプロセスを説明し、注意すべき⚠️ 制限事項について説明します。次に、ゲーム開発の文脈での関連技術と今後の方向性について話します。最後に、最終的なゲームについてまとめます。 プロセス 要件:このプロセス全体でChatGPTを使用しています。ChatGPTと言語モデリングについての詳細については、シリーズのPart 2をお読みいただくことをおすすめします。ChatGPTは唯一の解決策ではありません。オープンソースの対話エージェントなど、数多くの新興競合他社が存在します。対話エージェントの新興市場についてさらに詳しく学ぶために、先を読んでください。 ChatGPTにストーリーの執筆を依頼します。ゲームに関する多くのコンテキストを提供した後、ChatGPTにストーリーの要約を書いてもらいます。 ChatGPTは、ゲームStardew…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.