Learn more about Search Results A - Page 201

- You may be interested
- Hugging FaceとGraphcoreがIPU最適化され...
- AlphaCodeとの競技プログラミング
- 「セキュアな会話:ChatGPTの使用時にプラ...
- 「メタがFacebookの衰退を収益化している...
- PyTorch LSTM — 入力、隠れ状態、セル状態...
- 「Google AIがAltUpを紹介」
- DeepMindのロボキャットに会ってください...
- 中国が世界最速のインターネットを謳う
- ポッドキャストのアクセシビリティを向上...
- 「Azureの「Prompt Flow」を使用して、GPT...
- 「ベクターデータベースのベンチマークに...
- クラウドコンピューティングとウェアラブ...
- 「ODSC Europe 2023に参加するためのすべ...
- Excel vs Tableau – どちらが優れたツール...
- ビジネス学生からテック業界のデータサイ...

「初心者におすすめの副業5選(無料のコースとAIツールで始める)」
「ここには、$0から始められる5つの実証済みの副業アイデアがありますこれらの無料コースとAIツールを活用して、成功を加速させましょう」

「OpenAI、DALL·E 3を発表:テキストから画像生成における革命的な進展」
OpenAIは、革新的なテキストから画像を生成する技術の最新バージョンであるDALL·E 3の発表を行い、重要な技術的進歩を遂げました。細かい説明を理解する能力が前例のないDALL·E 3は、ユーザーがテキストのアイデアを驚くほど正確な画像に翻訳することで創造的な世界を根本的に変革することを約束しています。 DALL·E 3は現在、研究プレビューとして提供されており、その能力を垣間見ることができます。しかし、この先進的な技術の広範な提供は、10月初旬に予定されており、ChatGPT PlusおよびEnterpriseの顧客はAPIおよびLabsを通じてアクセスすることができます。 現代のテキストから画像へのシステムの主な欠点の1つは、プロンプト内の重要な単語や詳細を見落とす傾向があることであり、これによりユーザーが複雑なプロンプトエンジニアリングを行う必要があります。DALL·E 3は、提供されたテキストに正確に適合する画像を生成するための画期的な解決策を提供し、前バージョンのDALL·E 2と比較しても一貫して優れたパフォーマンスを発揮しています。 DALL·E 3の特徴的な点は、ChatGPTとのネイティブな統合です。これにより、ユーザーはChatGPTをブレインストーミングパートナーとプロンプトリファイナーとして活用することができます。ユーザーは簡潔な文から複雑な段落まで、自分のビジョンをChatGPTに伝えることができます。ChatGPTは、ユーザーのコンセプトに生命を吹き込むためにDALL·E 3用のカスタマイズされた詳細なプロンプトを自動的に生成します。さらに、生成された画像が完璧でない場合、ユーザーはわずか数語でChatGPTに正確な調整を指示することができます。 OpenAIは、ChatGPT PlusおよびEnterpriseの顧客が数週間後にDALL·E 3を利用できるようにすることに対してアクセシビリティへの取り組みを継続しています。DALL·E 3を使用して作成した画像については、DALL·E 2と同様に、OpenAIの許可なしで再印刷、販売、商品化することができます。 OpenAIは、望ましくないコンテンツの生成を抑制する責任も強調しています。DALL·E 3は、暴力的な、成人向けの、または憎悪的なコンテンツの生成能力を制限する厳格な制御機能を備えており、この技術が創造的かつ建設的な目的のためのツールとして残ることを保証しています。 DALL·E 3の発表により、OpenAIはAIによる創造性の限界を押し広げ、詳細で現実的な画像をテキストの説明から生成するための強力で使いやすいプラットフォームを提供しています。10月が近づくにつれて、ChatGPT PlusおよびEnterpriseの顧客はこの驚くべき技術の可能性を解き放つことを待ち望んでいます。

「IBMの研究者たちは、モダリティやタスクに関係なくAIシステム向けの敵対的な入力を生成することが可能な新しい敵対的攻撃フレームワークを提案しています」
人工知能の常に進化する風景の中で、新たな懸念が浮かび上がってきました。AIモデルの脆弱性に対する逃避攻撃への対処です。これらの巧妙な攻撃は、入力データの微妙な変更により、モデルの出力結果を誤解させることができ、これはコンピュータビジョンモデルを超える脅威です。このような攻撃に対する堅牢な防御の必要性は明らかであり、AIが私たちの日常生活に深く統合される中でますます重要となっています。 数値的な性質を持つため、既存の逆襲攻撃に対する取り組みは主に画像に焦点を当ててきました。これは操作の便宜な標的となります。この分野でかなりの進展がありましたが、テキストや表形式のデータなど、他のデータタイプは固有の課題を提供します。これらのデータタイプは、モデルの消費のために数値的な特徴ベクトルに変換され、逆襲的な変更中にそれらの意味論的な規則を保持する必要があります。ほとんどの利用可能なツールキットはこれらの複雑さを処理するための支援が必要であり、これによりこれらの領域のAIモデルが脆弱になります。 URETは逆襲攻撃に対する戦いにおける画期的な存在です。URETは、悪意のある攻撃をグラフの探索問題として扱い、各ノードが入力状態を表し、各エッジが入力変換を表す形で効率的にモデルの誤分類につながる変化のシーケンスを特定します。このツールキットはGitHub上の簡単な設定ファイルを提供し、ユーザーが探索方法、変換タイプ、意味規則、および目的を自分のニーズに合わせて定義できるようにします。 最近のIBMリサーチの論文では、URETチームはURETの変換定義によってサポートされた表形式、テキスト、ファイル入力タイプの逆襲的な例を生成することでその能力を示しました。ただし、URETの真の強みはその柔軟性にあります。機械学習の実装の多様性を認識し、このツールキットは高度なユーザーがカスタマイズされた変換、意味規則、および探索目標を定義するための開かれた扉を提供しています。 URETは、その能力を測定するためにさまざまなデータタイプで逆襲的な例を生成する効果を強調するメトリクスに依存しています。これらのメトリクスは、URETがAIモデルの脆弱性を特定し、利用する能力を示すだけでなく、回避攻撃に対するモデルの堅牢性を評価するための標準化された手段も提供します。 まとめると、AIの登場は革新の新たな時代をもたらしましたが、逆襲的な逃避攻撃などの新たな課題も浮かび上がってきました。Universal Robustness Evaluation Toolkit(URET)は、この進化する風景における希望の光として現れます。グラフ探索アプローチ、さまざまなデータタイプへの適応性、オープンソースのコントリビューターの成長するコミュニティを備えることで、URETは悪意のある脅威からAIシステムを守るための重要な一歩を表しています。機械学習が私たちの生活のさまざまな側面に浸透する中で、URETによる厳格な評価と分析は逆襲的な脆弱性への最良の防御手段として、ますます結びつく世界におけるAIの信頼性を保証します。
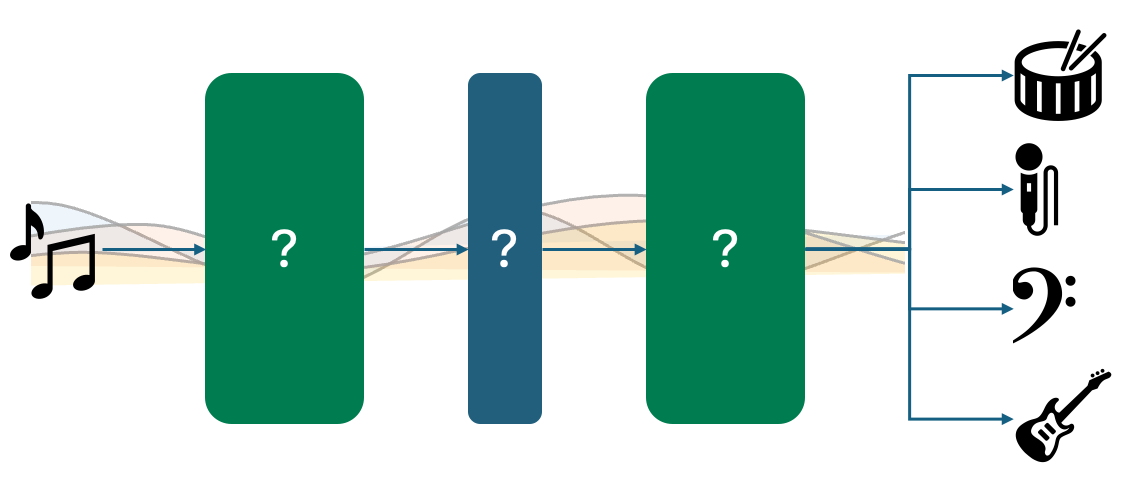
AI音楽のソース分離:その仕組みとなぜ難しいのか
信号処理の分野では、ソース分離とは、オーディオ信号を複数のソースオーディオ信号に分解する作業を指しますこの概念は音楽だけでなく、...

アナリストによると、ジェネレーティブAIにおいて、AppleはMicrosoftやGoogleに比べて大幅に遅れているとのことです
「Appleの最新のiPhone 15の発表イベントは、画期的な製品革新で魅了することはなかったかもしれませんが、それはより深刻な懸念を明らかにしましたつまり、Appleの位置は急速に進化する生成AIの世界で、GoogleやMicrosoftなどの競合他社に比べて遅れを取っているということですNeedhamのシニアメディア&インターネットアナリスト、ローラによると...」

報告書:OpenAIがGPT-VisionというマルチモーダルLLMをリリースするための取り組みを加速中
「The Information」の報告によると、ライバルのGoogleに先駆けて高度なマルチモーダルLLMを発表するため、OpenAIは報道によるとGPT-Vision(コードネーム:Gobi)のリリースを加速させているようですこれは、GoogleのマルチモーダルLLMであるGeminiが先週、一部の企業にリリースされた1週間後のことです...

「画像の補完の進展:この新しいAI補完による2Dと3Dの操作のギャップを埋めるニューラル放射場」
コンテンツ作成において、画像の操作には持続的な関心があります。最も広く研究されている操作の1つは、オブジェクトの削除と挿入であり、画像補完のタスクとしてよく言及されています。現在の補完モデルは、周囲の画像とシームレスになじむ視覚的に説得力のあるコンテンツを生成することに長けていますが、これまでは単一の2D画像入力に限られていました。しかし、一部の研究者は、このようなモデルの応用を完全な3Dシーンの操作に進めようとしています。 ニューラル・ラディアンス・フィールド(NeRFs)の登場により、実際の2D写真を生き生きとした3D表現に変換することがより容易になりました。アルゴリズムの改良が進み、計算要件が減少するにつれ、これらの3D表現は一般的になるかもしれません。したがって、この研究は、2D画像に対して利用可能なような3D NeRFsの操作を可能にすることを目指しています。 3Dオブジェクトの補完には、3Dデータの希少性や3Dジオメトリと外観の両方を考慮する必要性など、独自の課題があります。シーン表現としてのNeRFsの使用は、さらなる複雑さを導入します。ニューラル表現の暗黙性のため、ジオメトリの理解に基づいて基礎データ構造を直接変更することは実用的ではありません。また、NeRFsは画像からトレーニングされるため、複数のビュー間での一貫性の維持は難しいです。個々の構成画像の独立した補完は、視点の不整合や視覚的に現実的でない出力を引き起こす可能性があります。 これらの課題に対処するために、さまざまなアプローチが試みられています。たとえば、NeRF-Inは、ピクセル単位の損失を介してビューを組み合わせる方法や、知覚的な損失を使用するSPIn-NeRFなど、不整合を事後に解決しようとするいくつかの手法があります。しかし、これらのアプローチは、補完されたビューが著しい知覚的な違いを示す場合や、複雑な外観が関与する場合には苦労するかもしれません。 また、単一参照補完方法も検討されており、参照ビューのみを使用することでビューの不整合を回避しています。ただし、このアプローチには、非参照ビューの視覚的品質の低下、ビュー依存の効果の欠如、および非表示領域の問題など、いくつかの課題があります。 上記の制限を考慮すると、3Dオブジェクトの補完を可能にするための新しいアプローチが開発されました。 システムへの入力は、異なる視点からのN枚の画像と、それらに対応するカメラ変換行列とマスク(不要な領域を示す)です。さらに、入力画像に関連する補完参照ビューが必要であり、これはユーザーがシーンの3D補完から期待する情報を提供します。この参照は、マスクを置き換えるオブジェクトのテキストの説明など、単純なものでもかまいません。 https://ashmrz.github.io/reference-guided-3d/paper_lq.pdf 上記の例では、「ラバーダック」や「花瓶」といった参照は、単一画像によるテキスト条件付け補完を使用することで取得できます。これにより、ユーザーは望ましい編集を持つ3Dシーンの生成を制御および駆動することができます。 ビュー依存の効果(VDE)に重点を置いたモジュールにより、著者はシーンの視点依存の変化(たとえば、スペキュラリティや非ランバート効果)を考慮しようとします。そのため、他のビューの周囲コンテキストに一致するように参照色を修正することで、参照ビューポイント以外のマスク領域にVDEを追加します。 さらに、参照画像の深度に応じて、補完領域のジオメトリをガイドするために単眼の深度推定器を導入しています。参照ではすべてのマスク対象ピクセルが見えないため、追加の補完を介してこれらの非遮蔽ピクセルを監視するアプローチが考案されています。 提案手法の最新のSPIn-NeRF-Lamaとの新しいビューの描画の視覚的比較を以下に示します。 https://ashmrz.github.io/reference-guided-3d/paper_lq.pdf これは、ニューラル輝度場の参照に基づいた制御可能なインペインティングのための新しいAIフレームワークの概要です。興味がある場合は、以下に引用されているリンクを参照して詳細を学ぶことができます。

「生成AIの時代における品質保証の再考」
「GenAI が生成したコードに追いつくために、テストエンジニアはGenAIツールを活用し、QA計画の基礎を形成する必要があります」

「Amazon SageMakerを使用して、マルチクラウド環境でMLモデルをトレーニングおよびデプロイする」
この投稿では、多クラウド環境でAWSの最も広範で深いAI / ML機能の1つを活用するための多くのオプションの1つを示しますAWSでMLモデルを構築しトレーニングし、別のプラットフォームでモデルを展開する方法を示しますAmazon SageMakerを使用してモデルをトレーニングし、モデルアーティファクトをAmazon Simple Storage Service(Amazon S3)に保存し、モデルをAzureで展開して実行します

「驚くべき進化:メルセデス・ベンツがNVIDIA Omniverse、MB.OS、および生成AIと共にネクストジェンプラットフォームのためのデジタルプロダクションシステムを準備中」
メルセデス・ベンツは、NVIDIA Omniverseを活用してデジタルツインを生産に使用しています。これは、ユニバーサルシーンディスクリプション(OpenUSD)アプリケーションを開発するためのプラットフォームであり、製造および組立施設の設計、共同作業、計画、運営に役立ちます。 メルセデス・ベンツの新しい生産技術により、次世代の車両ポートフォリオがドイツのラスタット、ハンガリーのケチケメート、中国の北京で運営される製造施設に導入され、30以上の工場における設計図となります。この「デジタルファースト」のアプローチは、メルセデス・ベンツのMO360生産システムの柔軟性、耐久性、知能を飛躍的に向上させ、効率を高め、欠陥を回避し、時間を節約することができます。 生産におけるデジタルツインは、メルセデス・ベンツの組立ラインが物理的に正確なシミュレーションで再設計、構成、最適化できるようにします。ケチケメート工場の新しい組立ラインでは、デジタルツインを使用して仮想的に開発されたメルセデス・モジュラーアーキテクチャに基づく車両の生産が可能になります。 Omniverseを活用することで、メルセデス・ベンツはサプライヤーと直接やり取りすることができ、調整プロセスを50%削減することができます。生産におけるデジタルツインの使用は、組立ホールの変換や構築のスピードを2倍にし、プロセスの品質を向上させると、自動車メーカーは述べています。 「NVIDIA OmniverseとAIを使用することで、メルセデス・ベンツはつながったデジタルファーストのアプローチを構築し、製造プロセスを最適化し、建設時間と生産コストを削減することができます」と、NVIDIAのOmniverseおよびシミュレーション技術担当バイスプレジデントのRev Lebaredianは、本日開催されたデジタルイベントで述べています。 さらに、AIの導入により、エネルギーとコストの節約の新たな領域が開かれます。ラスタット工場では、ペイントショップでデジタル生産を先駆けています。メルセデス・ベンツは、パイロットテストで関連するサブプロセスを監視するためにAIを使用し、エネルギーの20%の節約を実現しました。 最先端のソフトウェアシステムをサポート 次世代のメルセデス・ベンツ車は、新しいオペレーティングシステム「MB.OS」を搭載し、車両ポートフォリオ全体で標準化され、すべての車両領域でプレミアムなソフトウェア機能とエクスペリエンスを提供します。 メルセデス・ベンツは、NVIDIAと提携してソフトウェア定義型の車両を開発しています。そのフリートは、NVIDIA DRIVE OrinとDRIVEソフトウェア上に構築され、NVIDIA DRIVE Simプラットフォームでテストおよび検証されたインテリジェントな運転機能を備えています。 自動車メーカーのMO360生産システムにより、電気、ハイブリッド、ガソリンモデルを同じ生産ラインで製造し、電気自動車の製造を拡大することができます。生産におけるMB.OSの実装により、車両ソフトウェアの最新バージョンを組み立てラインからロールアウトすることが可能になります。 「メルセデス・ベンツは、人工知能、MB.OS、およびNVIDIA Omniverseに基づくデジタルツインをMO360エコシステムに統合することで、自動車製造の新たな時代を開始しています」と、メルセデス・ベンツグループAGの取締役であるJörg Burzerは述べています。「新しい『デジタルファースト』のアプローチにより、MMAモデルのグローバル生産ネットワークでの導入前に効率のポテンシャルを開放し、ランプアップを大幅に加速することができます。」 柔軟な未来の工場 製造生産の中断を回避することは重要です。NVIDIA Omniverseでのシミュレーションを実行することで、工場プランナーは供給ルートのための工場床や生産ラインのレイアウトを最適化することができ、生産を中断することなく検証することができます。 この仮想的なアプローチは、新しいラインの効率的な設計や既存のラインの変更管理を可能にし、ダウンタイムを減らし、製品の品質向上を助けます。世界の自動車メーカーにとって、チップからクラウドまでソフトウェア開発スタック全体で多くの利益があります。…
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.