Learn more about Search Results H3 - Page 200

- You may be interested
- ウェアラブル汗センサーが炎症の分子的特...
- 会話型データ分析:ノイズを切り抜いて真...
- 「Power BIで実績と予測を一つの連続した...
- 「OpenAIやLM Studioに頼らずにAutoGenを...
- 「生成AIの時代における品質保証の再考」
- 自律生成AIとオートコンプリートの違いを...
- 「ChatGPTのような生成AIを使用してペルソ...
- 「F1スコア:視覚的ガイド – そして...
- 5分であなたのStreamlitウェブアプリをデ...
- 「ビームサーチ:シーケンスモデルでよく...
- この人工知能(AI)の研究では、SAMを医療...
- 「Retrieval Augmented GenerationとLangC...
- 「AIベースのサイバーセキュリティがビジ...
- 「Pythonで時系列ネットワークグラフの可...
- 「合成キャプションはマルチモーダルトレ...

SRGANs:低解像度と高解像度画像のギャップを埋める
イントロダクション あなたが古い家族の写真アルバムをほこりっぽい屋根裏部屋で見つけるシナリオを想像してください。あなたはすぐにほこりを取り、最も興奮してページをめくるでしょう。そして、多くの年月前の写真を見つけました。しかし、それでも、あなたは幸せではないです。なぜなら、写真が薄く、ぼやけているからです。写真の顔や細部を見つけるために目をこらします。これは昔のシナリオです。現代の新しいテクノロジーのおかげで、私たちはスーパーレゾリューション・ジェネレーティブ・アドバーサリ・ネットワーク(SRGAN)を使用して、低解像度の画像を高解像度の画像に変換することができます。この記事では、私たちはSRGANについて最も学び、QRコードの強化のために実装します。 出典: Vecteezy 学習目標 この記事では、以下のことを学びます: スーパーレゾリューションと通常のズームとの違いについて スーパーレゾリューションのアプローチとそのタイプについて SRGAN、その損失関数、アーキテクチャ、およびそのアプリケーションについて深く掘り下げる SRGANを使用したQRエンハンスメントの実装とその詳細な説明 この記事は、データサイエンスブログマラソンの一環として公開されました。 スーパーレゾリューションとは何ですか? 多くの犯罪捜査映画では、証拠を求めて探偵がCCTV映像をチェックする典型的なシナリオがよくあります。そして、ぼやけた小さな画像を見つけて、ズームして強化してはっきりした画像を得るシーンがあります。それは可能ですか?はい、スーパーレゾリューションの助けを借りて、それはできます。スーパーレゾリューション技術は、CCTVカメラによってキャプチャされたぼやけた画像を強化し、より詳細な視覚効果を提供することができます。 ………………………………………………………………………………………………………………………………………………………….. ………………………………………………………………………………………………………………………………………………………….. 画像の拡大と強化のプロセスをスーパーレゾリューションと呼びます。それは、対応する低解像度の入力から画像またはビデオの高解像度バージョンを生成することを目的としています。それによって、欠落している詳細を回復し、鮮明さを向上させ、視覚的品質を向上させることができます。強化せずに画像をズームインするだけでは、以下の画像のようにぼやけた画像が得られます。強化はスーパーレゾリューションによって実現されます。写真、監視システム、医療画像、衛星画像など、さまざまな領域で多くの応用があります。 ……….. スーパーレゾリューションの従来のアプローチ 従来のアプローチでは、欠落しているピクセル値を推定し、画像の解像度を向上させることに重点を置いています。2つのアプローチがあります。補間ベースの方法と正則化ベースの方法です。 補間ベースの方法 スーパーレゾリューションの初期の日々には、補間ベースの方法に重点が置かれ、欠落しているピクセル値を推定し、その後画像を拡大します。隣接するピクセル値が類似しているという仮定を使用して、これらの値を使用して欠落している値を推定します。最も一般的に使用される補間方法には、バイキュービック、バイリニア、および最近傍補間があります。しかし、その結果は満足できないものでした。これにより、ぼやけた画像が生じました。これらの方法は、基本的な解像度タスクや計算リソースに制限がある状況に適しているため、効率的に計算できます。 正則化ベースの手法 一方で、正則化ベースの手法は、画像再構成プロセスに追加の制約や先行条件を導入することで、超解像度の結果を改善することを目的としています。これらの技術は、画像の統計的特徴を利用して、再構築された画像の精度を向上させながら、細部を保存します。これにより、再構築プロセスにより多くの制御が可能になり、画像の鮮明度と細部が向上します。しかし、複雑な画像コンテンツを扱う場合には、過度の平滑化を引き起こすため、いくつかの制限があります。 これらの従来のアプローチにはいくつかの制限があるにもかかわらず、超解像度の強力な手法の出現への道を示しました。…

中国の研究者グループが開発したWebGLM:汎用言語モデル(GLM)に基づくWeb強化型質問応答システム
大規模言語モデル(LLM)には、GPT-3、PaLM、OPT、BLOOM、GLM-130Bなどが含まれます。これらのモデルは、言語に関してコンピュータが理解し、生成できる可能性の限界を大きく押し上げています。最も基本的な言語アプリケーションの一つである質問応答も、最近のLLMの突破によって大幅に改善されています。既存の研究によると、LLMのクローズドブックQAおよびコンテキストに基づくQAのパフォーマンスは、教師ありモデルのものと同等であり、LLMの記憶容量に対する理解に貢献しています。しかし、LLMにも有限な容量があり、膨大な特別な知識が必要な問題に直面すると、人間の期待には及びません。したがって、最近の試みでは、検索やオンライン検索を含む外部知識を備えたLLMの構築に集中しています。 たとえば、WebGPTはオンラインブラウジング、複雑な問い合わせに対する長い回答、同等に役立つ参照を行うことができます。人気があるにもかかわらず、元のWebGPTアプローチはまだ広く採用されていません。まず、多数の専門家レベルのブラウジング軌跡の注釈、よく書かれた回答、および回答の優先順位のラベリングに依存しており、これらは高価なリソース、多くの時間、および広範なトレーニングが必要です。第二に、システムにウェブブラウザとのやり取り、操作指示(「検索」、「読む」、「引用」など)を与え、オンラインソースから関連する材料を収集させる行動クローニングアプローチ(すなわち、模倣学習)は、基本的なモデルであるGPT-3が人間の専門家に似ている必要があります。 最後に、ウェブサーフィンのマルチターン構造は、ユーザーエクスペリエンスに対して過度に遅いことがあり、WebGPT-13Bでは、500トークンのクエリに対して31秒かかります。本研究の清華大学、北京航空航天大学、Zhipu.AIの研究者たちは、10億パラメータのジェネラル言語モデル(GLM-10B)に基づく、高品質なウェブエンハンスド品質保証システムであるWebGLMを紹介します。図1は、その一例を示しています。このシステムは、効果的で、手頃な価格で、人間の嗜好に敏感であり、最も重要なことに、WebGPTと同等の品質を備えています。システムは、LLM-拡張検索器を含む、いくつかの新しいアプローチや設計を使用して、良好なパフォーマンスを実現しています。精製されたリトリーバーと粗い粒度のウェブ検索を組み合わせた2段階のリトリーバーである。 GPT-3のようなLLMの能力は、適切な参照を自発的に受け入れることです。これは、小型の密集リトリーバーを改良するために洗練される可能性があります。引用に基づく適切なフィルタリングを使用して高品質のデータを提供することで、LLMはWebGPTのように高価な人間の専門家に頼る必要がありません。オンラインQAフォーラムからのユーザーチャムアップシグナルを用いて教えられたスコアラーは、さまざまな回答に対する人間の多数派の嗜好を理解することができます。 図1は、WebGLMがオンラインリソースへのリンクを含むサンプルクエリに対する回答のスナップショットを示しています。 彼らは、適切なデータセットアーキテクチャがWebGPTの専門家ラベリングに比べて高品質のスコアラーを生成できることを示しています。彼らの定量的な欠損テストと詳細な人間評価の結果は、WebGLMシステムがどれだけ効率的かつ効果的かを示しています。特に、WebGLM(10B)は、彼らのチューリングテストでWebGPT(175B)を上回り、同じサイズのWebGPT(13B)よりも優れています。Perplexity.aiの唯一の公開可能なシステムを改善するWebGLMは、この投稿時点で最高の公開可能なウェブエンハンスドQAシステムの一つです。結論として、著者らは次のことを提供しています。・人間の嗜好に基づく、効果的なウェブエンハンスド品質保証システムであるWebGLMを構築しました。WebGPT(175B)と同等のパフォーマンスを発揮し、同じサイズのWebGPT(13B)よりもはるかに優れています。 WebGPTは、LLMsと検索エンジンによって動力を与えられた人気システムであるPerplexity.aiをも凌駕します。•彼らは、WebGLMの現実世界での展開における制限を特定しています。彼らは、ベースラインシステムよりも効率的でコスト効果の高い利点を実現しながら、高い精度を持つWebGLMを可能にするための新しい設計と戦略を提案しています。•彼らは、Web強化QAシステムを評価するための人間の評価メトリックを定式化しています。広範な人間の評価と実験により、WebGLMの強力な能力が示され、システムの将来的な開発についての洞察が生成されました。コードの実装はGitHubで利用可能です。

Pythonで絶対に犯してはいけない10の失敗
Pythonを学び始めると、多くの場合、悪い習慣に遭遇することがありますこの記事では、Python開発者としてのレベルを上げるためのベストプラクティスを学びます私が覚えているのは、私が...

GitHubトピックススクレイパー | PythonによるWebスクレイピング
「GitHub Topics Scraper」このプロジェクトは、GitHub Topicsページから情報を取得し、リポジトリ名と詳細を抽出することを目的としています

新しい方法:AIによって地図がより没入感あるものになる
AIの進歩により、マップで経路を理解する新しい方法がありますさらに、開発者向けの新しい没入型ツールもあります

Google フォトのマジックエディター:写真を再構築するための新しいAI編集機能
Magic Editorは、AIを使用して写真を再構想するのを手助けする実験的な編集体験です今年後半には、選択されたPixel電話での早期アクセスが計画されています
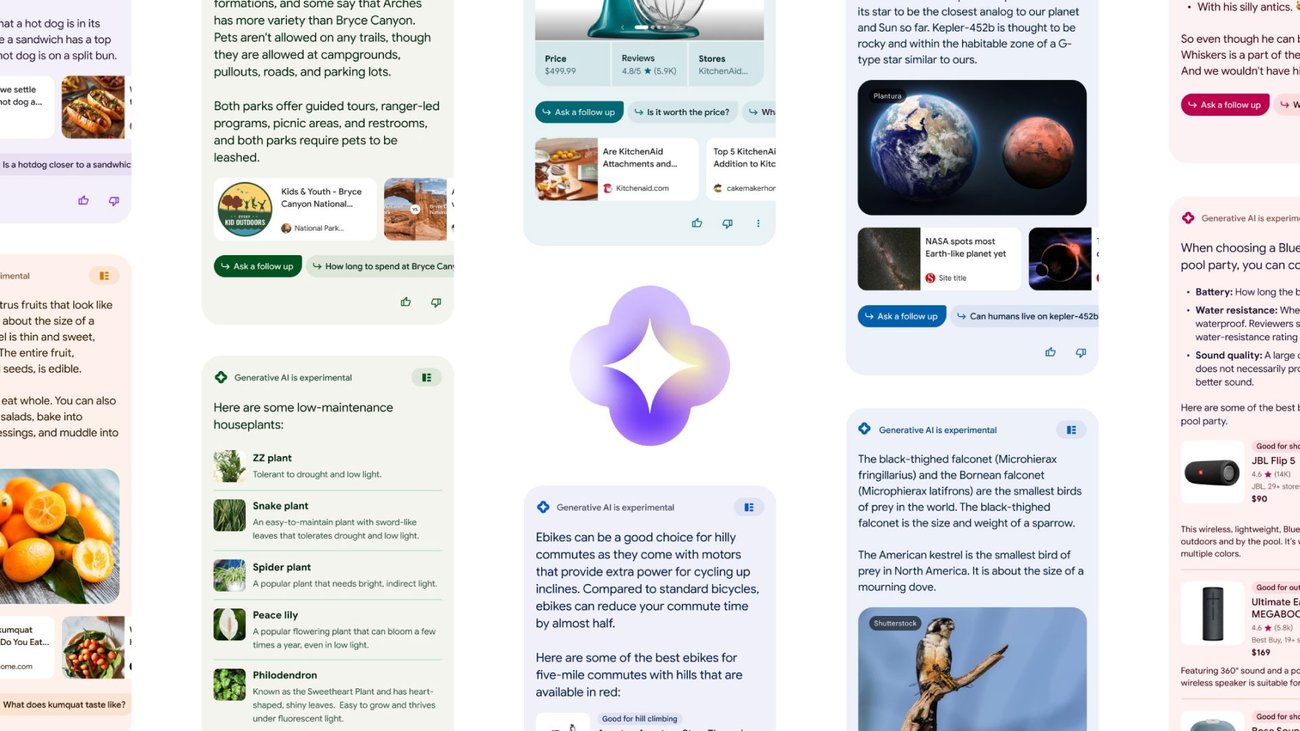
生成型AIによる検索のスーパーチャージ
私たちは、ジェネレーティブAIを使用するSGE(Search Generative Experience)という名前の検索ラボの実験から始めます
責任あるAI進歩のための政策アジェンダ:機会、責任、セキュリティ
社会がAIの恩恵を受けるためには、機会、責任、そして国家安全保障戦略が共有されたAIのアジェンダに組み込まれる必要があります
欠陥が明らかにされる:MLOpsコース作成の興味深い現実
不完全なものが明らかにされる舞台裏バッチ特徴ストアMLパイプラインMLプラットフォームPythonGCPGitHub ActionsAirflowMLOpsCI/CDコース

「Storytelling with Data」によると、データの視覚化をすぐに改善するためのMatplotlibのヒント
「Storytelling with Data」(Cole Nussbaumer Knaflic著)で得た教訓に基づいて、Matplotlibとseabornのデータ可視化を改善する方法
Find the right Blockchain Investment for you
Web 3.0 is coming, whether buy Coins, NFTs or just Coding, everyone can participate.